
はじめに
こんにちは、イノベーションセンターの鈴ヶ嶺・齋藤です。普段はコンピュータビジョンの技術開発やAI/MLシステムの検証に取り組んでいます。10月11日から17日にかけて、コンピュータービジョン分野におけるトップカンファレンスのひとつである ICCV2021 がオンラインで開催され、NTT Comからは複数名が参加しました。ここでは、会議の概要と参加メンバー2名からICCV2021の論文紹介をします。
ICCV2021
ICCV(International Conference on Computer Vision)は、2年ごとに開催されるコンピュータービジョン分野におけるトップカンファレンスのひとつです。2021年は10月11日から17日にかけて、オンラインで開催されました。
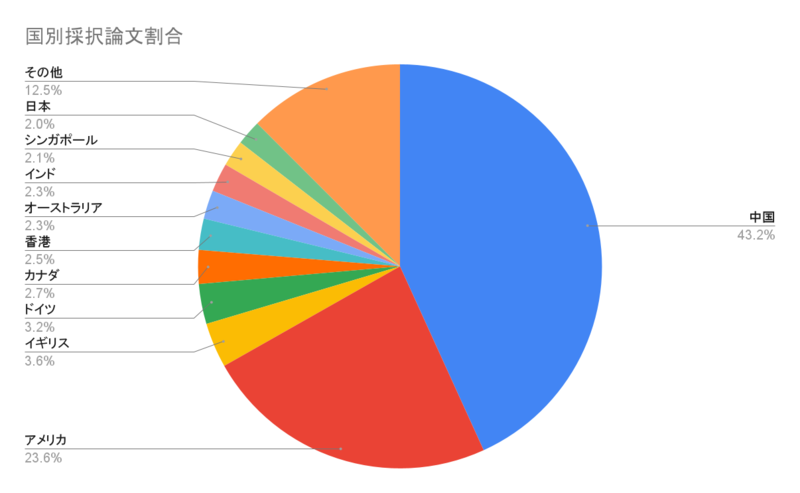
アクセプトされた国の比率は上記のようになっており、中国とそれに続いてアメリカが多数を占めていました。一昨年のICCV2019からおよそ1800件の投稿が増えて6152件が投稿されました。そのうちの26%である1612件の論文が採択される結果となりました。また、口頭発表には3.4%の210件が選ばれました。
論文紹介
ここからは参加メンバーが気になったICCV21の論文と実際にコードを動かした結果を紹介します。
COMISR: Compression-Informed Video Super-Resolution(ORAL PAPER)
COMISRとは
今までの多くの映像の超解像手法は圧縮を考慮せず、低解像の動画から高解像の動画に変換しています。しかし、日常で使用しているwebやモバイルのコンテンツの多くは圧縮されています。この論文では、そのようなコンテンツを対象として、圧縮情報を用いた映像の超解像手法を提案しています。
COMISR1は、Recurrentモデル2をベースにしています。一般的な動画圧縮には、イントラフレームと呼ばれる他のフレームを予測するのに用いられる参照フレームを使用します。イントラフレームは独立に圧縮され、他のフレームはそのイントラフレームからの差分情報のみを使用して復元することから高い圧縮率を達成することが可能となります。このイントラフレームの位置はランダムに選択され事前には分からないため、Recurrentモデルのような前後関係を踏まえた特徴を抽出可能なモデルが使用されます。また、Recurrentモデルはメモリ消費も少なく動画の様々な推論タスクに適しています。 次の画像が、手法の全体像です。提案手法は、主に3つのモジュールのBi-directional Recurrent Module, Detail-aware Flow Estimation, Laplacian Enhancement Moduleから構成されます。

Bi-directional Recurrent Module
Bi-directional Recurrent Moduleを用いることで前方と後方からのフレーム予測に対して一貫性を強制し、精度を向上させています。まず初めに、入力された低解像の画像を後述するDetail-aware Flow Estimationにより高解像のオプティカルフローを推定します。次に、推定した高解像画像に後述するLaplacian Enhancementによりラプラシアン残差を付加してspace-to-depthを経て高解像画像の生成処理をします。
Detail-aware Flow Estimation
Detail-aware Flow Estimationでは、隣接する低解像、高解像の画像の差分を表現したオプティカルフローを推定することであるフレームの次のフレームを生成します。上記の全体像ではフォワードの際の例が示されており、隣接する低解像の画像2つを連結したものを入力としてフローを推定します。その際には、直接フローをアップサンプリングするのではなく追加でdeconvolution層を通します。このようにして、end-to-endな学習や高周波の詳細な特徴を獲得することが可能となります。
Laplacian Enhancement Module
ラプラシアン残差は、多くの視覚タスクで使用されており非常に有用な詳細情報です。しかし、この情報はアップスケーリングネットワークでは容易に失われてしまうため、ラプラシアン残差を高解像の予測フレームに追加することで補完します。具体的には次の式のようにガウシアンフィルターを用いて残差を追加します。

実験結果
提案したCOMISRモデルをVid43、REDS4をCRF23で圧縮したデータセットを使用して既存の超解像モデルと比較した結果が次のようになります。提案手法は大幅な性能向上を達成しました。

次に、Vid4のいつかの結果を示します。定性的に比較してCOMISRが最も復元されていることが分かります。

実際に動作させた結果
次のツールを事前に準備しておきます。
以下が実際に動作させたものになります。
git clone --depth 1 https://github.com/google-research/google-research.git cd google-research/comisr # install package pip install -r requirements.txt # オリジナル動画を準備します (origin.mp4) # cp /path/to/origin.mp4 . # 解像度の確認 ffprobe -v error -select_streams v:0 -show_entries stream=width,height -of csv=s=x:p=0 origin.mp4 # 1920x1440 # オリジナル動画を低解像に変換します (lr_4x.mp4) ffmpeg -i origin.mp4 -crf 0 -vf scale=480:-1 lr_4x.mp4 # 解像度の確認 ffprobe -v error -select_streams v:0 -show_entries stream=width,height -of csv=s=x:p=0 lr_4x.mp4 # 480x360 # 低解像動画を圧縮します (lr_4x_crf25.mp4) ffmpeg -i lr_4x.mp4 -vcodec libx264 -crf 25 lr_4x_crf25.mp4 # download pre-trained model gsutil cp -r gs://gresearch/comisr/model/ . # input, target dataを準備します mkdir -p data/hr/linux_kernel ffmpeg -i origin.mp4 -r 60 data/hr/linux_kernel/img%05d.png mkdir -p data/lr_4x/linux_kernel ffmpeg -i lr_4x.mp4 -r 60 data/lr_4x/linux_kernel/img%05d.png mkdir -p data/lr_4x_crf25/linux_kernel ffmpeg -i lr_4x_crf25.mp4 -r 60 data/lr_4x_crf25/linux_kernel/img%05d.png # 出力先を用意します (output_dir) mkdir output_dir # 推論実行開始 export PYTHONPATH=$(dirname $(pwd)) python inference_and_eval.py --checkpoint_path=model/model.ckpt --input_lr_dir=data/lr_4x_crf25 --targets=data/hr --output_dir=output_dir # 結果 ## output_dir/linux_kernel/output_img00001.png ## output_dir/linux_kernel/output_img00002.png ## ...
今回は、詳解Linuxカーネル第3版の本を対象として実験してみました。以下は結果の抜粋です。



ぱっと見ると、なかなか綺麗に処理されていると思われます。次に、もっと細部に注目して見ていきましょう。

こちらの結果は左下の「O'REILLY オライリー・ジャパン」という文字に着目しています。アルファベットの「O'REILLY」については綺麗に復元されていることが分かります。カタカナの「オライリー・ジャパン」については、「ミライリー・ジャパン」のように読める文字として復元される結果になりました。おそらく、「オ」は潰れてしまい人間の目で見ても非常にわかりづらいので復元するのが難しい結果となったと考えられます。その他のカタカナについては人間が見ても読める文字に復元されています。

こちらの結果は水晶を磨く人物画像に着目しています。水晶の細かな模様についてはあまりに潰れすぎており復元が難しいですが、人物の顔や服の模様などがある程度綺麗に復元されていることが分かります。
所感
超解像の対象として圧縮されたコンテンツに着目した手法を提案している実用面での有用性を感じました。 また、フレーム予測による圧縮技術から着想を経てBi-directional Recurrentを採用した点や高周波情報を追加する工夫がされている点が素晴らしいと感じ紹介させていただきました。
SOTR: Segmenting Objects With Transformers
SOTRとは
SOTR5とは、Segmenting Objects With Transformersの略で、インスタンスセグメンテーションのタスクにおいて、CNNとTransformerを組み合わせたモデルの提案を行なっています。SOTRは、この論文でTwinTransformerを新しく提案し、そこではEncoderが画像の縦方向と横方向のみをAttentionするようになるため、時間とリソースの効率を良く且つ精度の向上を達成したことが示されています。効率よく計算できる理由として、縦横の2次元のAttentionの計算オーダから画像の縦横方向の2つをそれぞれ1次元にAttentionの計算する((縦方向の要素数x横方向の要素数)2 から (縦方向の要素数)2+(横方向の要素数)2)ためです。

まず見ていただきたいのは、Figure 1の図です。ベンチなどの大きいオブジェクトに対しては、これまでのMaskR-CNN6などのモデルでもセグメントが可能でした。しかし、画像左上と右上にあるような、小さい画像に対してのセグメントの精度は高いとは言えませんでした。これについては、後ほどSOTRを動かしてみるので、目で見てわかるほどの違いを体感可能です。SOTRでは、画像の左上や右上の図のようにかなり小さいオブジェクトに対しても、セグメントを高精度に行うことができています。それを可能にしたのが、CNNとトランスフォーマーを組み合わせたモデルとなります。


モデルの概要について説明します。まず、BackboneはFPNの機構を用いて、P2~P6までの特徴量マップを求めます。先程Transformerでは、Positional Embeddingを行いTwin Transformerを実行し、Kernel HeadとClass Headを出力します。SOTRで提案されているTwin Transformerでは、各パッチとその行と列のみをAttentionしています。インスタンスのクラス分類は、ここで説明を行なったTransformer ModuleのClass Headから行います。Multi level Upsampling Moduleでは、Transformer Moduleから出力された低解像度なP5の特徴量マップを取得し、各層P2〜P4でアップスケーリングと結合を最終的にH×W特徴マップを作ります。マスクの予測のために、Transformer Moduleから出力された、Kernel Headを畳み込みKernelとMulti level Upsampling Moduleから出力されたH×W特徴マップを掛け合わせ、マスクを生成します。
実験結果

上のテーブルはTwin TransformerとMask R-CNNやSOLO7などのインスタンスセグメーテーションのモデルの精度を比較したものとなります。学習用データセットは、MS COCO train20178。評価用データセットは、test-devを使用しています。論文著者の学習環境は、32GのRAMを搭載したNvidia V100、4枚で学習されフレームワークにはPyTorchとDetectron2を用いています。結果として、SOTRがテーブルで示している他モデルよりも6つの評価指標のうち5つ(AP,AP50,AP75,APM,APL)において高い精度を示していました。
実際に動作させた結果
まず、SOTRはdetectron2上で動作させるためにはdetectron2, SOTRのセットアップをする必要があります。インストールするスクリプトを流しても良いのですが、PCの環境が汚れてしまうため、今回はDocker&Jupyter Notebookを立て、検証しました。自身の実行環境は、Ubuntu18.04、Single NVIDIA RTX3090です。
FROM nvidia/cuda:11.1.1-cudnn8-devel-ubuntu18.04 MAINTAINER Satoru Saito ENV DEBIAN_FRONTEND noninteractive RUN apt-get update && apt-get install -y \ python3-opencv ca-certificates python3.7-dev git wget sudo python3.7-distutils python3-pip cmake git wget sudo ninja-build && \ rm -rf /var/lib/apt/lists/* #python install RUN python3.7 -m pip install --upgrade pip RUN python3.7 -m pip install numpy RUN ln -sv /usr/bin/python3.7 /usr/bin/python && \ python -V # create a non-root user ARG USER_ID=1000 RUN useradd -m --no-log-init --system --uid ${USER_ID} appuser -g sudo RUN echo '%sudo ALL=(ALL) NOPASSWD:ALL' >> /etc/sudoers USER appuser WORKDIR /home/appuser ENV PATH="/home/appuser/.local/bin:${PATH}" RUN wget https://bootstrap.pypa.io/get-pip.py && \ python get-pip.py --user && \ rm get-pip.py # install dependencies # See https://pytorch.org/ for other options if you use a different version of CUDA RUN pip install --user tensorboard cmake pycocotools RUN pip install torch==1.8.0+cu111 torchvision==0.9.0+cu111 torchaudio==0.8.0 -f https://download.pytorch.org/whl/torch_stable.html RUN pip install --user 'git+https://github.com/facebookresearch/fvcore' RUN pip --no-cache-dir install absl-py==0.10.0 backcall==0.1.0 cachetools==4.0.0 chardet==3.0.4 cloudpickle cycler==0.10.0 cython dataclasses decorator==4.4.2 future==0.18.2 fvcore==0.1.dev200325 grpcio==1.27.2 idna==2.9 ipykernel==5.2.0 ipython==7.13.0 ipython-genutils==0.2.0 jedi==0.16.0 jupyter-client==6.1.1 jupyter-core==4.6.3 kiwisolver==1.1.0 markdown==3.2.1 matplotlib numpy==1.18.2 oauthlib==3.1.0 opencv-python pandas==1.0.3 parso==0.6.2 pexpect==4.8.0 pickleshare==0.7.5 pillow==7.0.0 portalocker==1.6.0 prompt-toolkit==3.0.4 protobuf==3.11.3 psutil==5.7.0 ptyprocess==0.6.0 pyasn1==0.4.8 pyasn1-modules==0.2.8 pydot==1.4.1 pygments==2.6.1 pyparsing==2.4.6 pytz==2019.3 pyyaml==5.3.1 pyzmq==19.0.0 requests==2.23.0 requests-oauthlib==1.3.0 rsa==4.0 scipy==1.4.1 seaborn==0.10.1 six==1.14.0 tabulate tensorboard tensorboard-plugin-wit==1.6.0.post2 termcolor==1.1.0 tornado==6.0.4 tqdm==4.43.0 traitlets==4.3.3 urllib3==1.25.8 wcwidth==0.1.9 werkzeug==1.0.0 yacs==0.1.6 networkx==2.3 python-Levenshtein Polygon3 shapely graphviz # install detectron2 RUN git clone https://github.com/facebookresearch/detectron2 detectron2_repo # set FORCE_CUDA because during `docker build` cuda is not accessible ENV FORCE_CUDA="1" # This will by default build detectron2 for all common cuda architectures and take a lot more time, # because inside `docker build`, there is no way to tell which architecture will be used. ARG TORCH_CUDA_ARCH_LIST="Kepler;Kepler+Tesla;Maxwell;Maxwell+Tegra;Pascal;Volta;Turing" ENV TORCH_CUDA_ARCH_LIST="${TORCH_CUDA_ARCH_LIST}" RUN pip install --user -e detectron2_repo # Set a fixed model cache directory. ENV FVCORE_CACHE="/tmp" WORKDIR "/home/appuser" ENV PATH="/home/appuser/.local/bin:${PATH}" # Jupyter Notebook RUN pip install jupyter && \ mkdir /home/appuser/.jupyter && \ echo "c.NotebookApp.ip = '*'" \ "\c.NotebookApp.port = '8888'" \ "\nc.NotebookApp.open_browser = False" \ "\nc.NotebookApp.token = ''" \ > /home/appuser/.jupyter/jupyter_notebook_config.py EXPOSE 8888 WORKDIR "/home/appuser/detectron2_repo" RUN git clone https://github.com/easton-cau/SOTR.git RUN cd /home/appuser/detectron2_repo/SOTR && \ sudo python setup.py build develop
以上のDockerfileをbuild&runします。
TerminalからJupyterの起動し、任意のディレクトリに SOTR_R101_DCN をダウンロードをします。また、自身の解析したい画像のパスを --input に指定し以下のコードを走らせると推論を始めます。
python SOTR/demo/demo.py \ --config-file SOTR/configs/SOTR/R_101_DCN.yaml \ --input hoge.jpg --output ./SOTR/outputs/ \ --opts MODEL.WEIGHTS ./SOTR/SOTR_R101_DCN.pth
今回私は、MSCOCO val2017から一枚を選び推論をしました。一枚目の画像は、Methodが、MaskR-CNNでBackboneがResNet509。2枚目は、MethodがSOTRでBackboneがResNet DCN101となります。2枚を比較すると、奥にいる小さい人のセグメントが上がっていることが分かります。直感的にも、精度が向上していることが分かりました。ここからは、私の考察になってしまうのですがTwin Transformerが、MaskR-CNNと比較し小さい物体のセグメントをできている理由として、Transformer層で画像の縦横をピクセル単位でAttentionを行なっているため、局所的な特徴量の抽出が可能になっているのではないかと考えられます。今回は、定量的な評価はしないのですが、機会があれば検証したいです。


所感
ここでは、インスタンスセグメンテーションのタスクにおいて、CNNとTransformerを組み合わせたモデルについて説明しました。オリジナルのTransformer Encoderよりも、メモリの消費量を減らし且つ、精度の向上が論文中に示されていたので、興味を持ちご紹介しました。
最後に
ここまで前編では、ICCV2021の概要と発表された論文の一部をご紹介しました。後編も引き続き気になった論文を紹介するのでぜひご覧になってください。
NTT Comでは、今回ご紹介した論文調査、画像や映像、更には音声言語も含めた様々なメディアAI技術の研究開発に今後も積極的に取り組んでいきます。
- アカデミックな研究に注力したくさん論文を書きたい
- 最新の技術をいちはやく取り入れ実用化に結び付けたい
- AIアルゴリズムに加え、AI/MLシステム全体の最適な設計を模索したい
という方々に活躍していただけるフィールドがNTT Comには多くあり、一緒に技術開発を進めてくれる仲間を絶賛募集中です。
-
Li, Yinxiao, Pengchong Jin, Feng Yang, Ce Liu, Ming-Hsuan Yang, en Peyman Milanfar. “COMISR: Compression-Informed Video Super-Resolution”. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2543–52, 2021.↩
-
Takashi Isobe, Xu Jia, Shuhang Gu, Songjiang Li, Shengjin Wang, and Qi Tian. Video super-resolution with recurrent structure-detail network. In ECCV, 2020.↩
-
Jie Liu, Wenjie Zhang, Yuting Tang, Jie Tang, and Gangshan Wu. Residual feature aggregation network for image superresolution. In CVPR, 2020.↩
-
Seungjun Nah, Sungyong Baik, Seokil Hong, Gyeongsik Moon, Sanghyun Son, Radu Timofte, and Kyoung Mu Lee. Ntire 2019 challenge on video deblurring and superresolution: Dataset and study. In CVPR Workshops, 2019.↩
-
Guo, Ruohao, Dantong Niu, Liao Qu, en Zhenbo Li. “SOTR: Segmenting Objects With Transformers”. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 7157–66, 2021.↩
-
Kaiming He, Georgia Gkioxari, Piotr Dollár, and Ross Girshick. Mask r-cnn. In Proceedings of the IEEE international conference on computer vision, pages 2961–2969, 2017.↩
-
Xinlong Wang, Tao Kong, Chunhua Shen, Yuning Jiang, and Lei Li. SOLO: Segmenting objects by locations. In Proc. Eur. Conf. Computer Vision (ECCV), 2020.↩
-
Tsung-Yi Lin, M. Maire, Serge J. Belongie, James Hays, P. Perona, D. Ramanan, Piotr Dollár, and C. L. Zitnick. Microsoft coco: Common objects in context. In ECCV, 2014.↩
-
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.↩