
はじめに
こんにちは、クラウド&ネットワークサービス部で SDPF のベアメタルサーバー・ハイパーバイザーの開発をしている山中です。
先日 GitHub Actions self-hosted runners のオートスケーリング構成の紹介(クラウドサービス開発を支える CI の裏側) の記事で、自作の runner controller と Docker を用いた、オンプレミスでの CI 環境構成についてご紹介しました。 今回の記事では、構築した CI 環境上で動かしている workflow の紹介をしながら、workflow 作成についての Tips をいくつかご紹介したいと思います。
記事を書いたモチベーション
実際の業務で GitHub Actions を使用するにあたって、ありがちな悩みを解決するための workflow の作成事例や工夫などの記事が検索であまり見つからなかったためです。 どのような workflow を作成するかは開発現場によって様々であり、今回紹介する Tips も汎用的ではないものもありますが、他のチームはこんな風にこの機能を使ってるんだ〜みたいに読んでもらえればなと思います。
なお、この記事は GitHub Actions を普段使っている方向けに書いていることや、後ろのトピックほど私たちのチーム独自の内容になっていることをご了承ください
トピック
- run_name、Job Summary で workflow の実行パラメータを見やすく
- composite action、reusable workflow による処理の再利用の例
- 複数リポジトリ間での機密情報の扱い方
- 独自キャッシュによる効率的なファイル共有
run_name、Job Summary で workflow の実行パラメータを見やすく
私たちのチームではリポジトリごとに単体テストの workflow を作成しています。 単体テストは workflow_dispatch で実行することになっており、PR に紐づくブランチを指定して手動で workflow を実行することになっています。
私たちのリポジトリでは、単体テストは環境の初期化やテスト項目数の多さなどにより時間がかかるものが多く、1並列でしかテストを流せないという制約もあります。 Pull Request(以下、PR)の更新などによって自動でテストを流してしまうと、開発者が望むタイミングでテストを流しづらくなってしまうため、workflow_dispatch を使っています。
workflow_dispatch の歯がゆい点
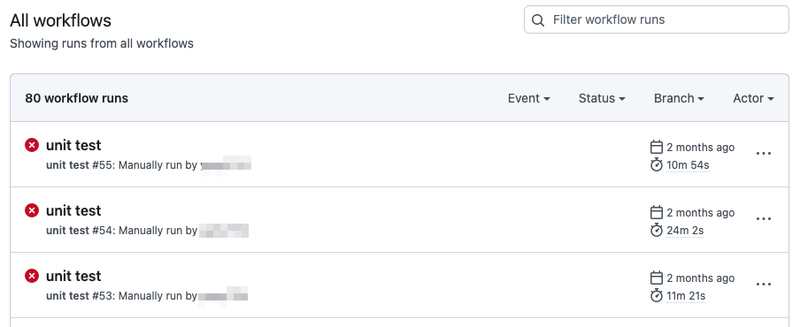
そんな workflow_dispatch ですが、GUI 上での見え方にやや難があり、以下のように workflow 実行時に指定したブランチがひと目で分かりません。
右上の Filter からブランチを絞り込んで表示することも可能ですが、わざわざ絞り込むのが手間です。
on: push などで workflow を実行した場合はブランチを表示してくれるのですが、workflow_dispatch の場合は workflow の name や実行者ぐらいしか表示してくれません。
run-name の活用
こんなときに役立つのが、run-name です。 workflow ファイル内で run-name を定義すると、実行された run の名前をカスタマイズでき、GUI 上での見え方に変化を与えることができます。
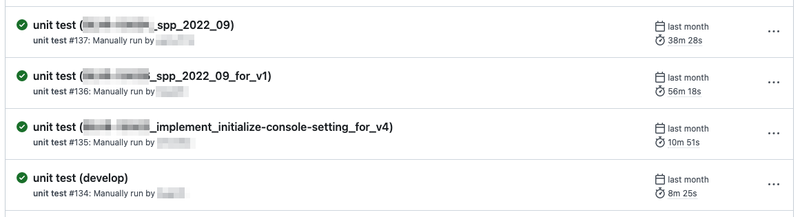
例えば以下のように run-name を定義することで「どの run がどのブランチから実行されたのか」がひと目で分かるようになります。
run-name: ${{ github.workflow }} (${{ github.ref_name }})
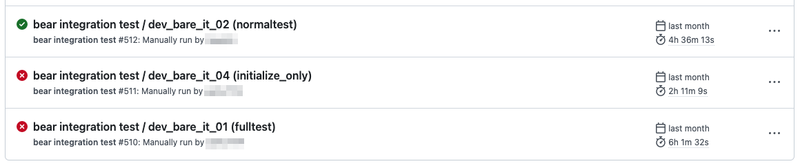
また、workflow 実行時に指定した inputs も run-name で参照でき、以下のように run-name を定義することで「どの run がどのパラメータで実行されたのか」もひと目で分かるようにもできます。
run-name: ${{ github.workflow }} / ${{ inputs.environment }} (${{ inputs.scenario }})
Job Summaries の活用
ここで表示した inputs ですが、数が多くなってくると run-name に全て表示しきれなくなってきます。 そんなときは Job Summaries を使うのがおすすめです。
GitHub Actions では workflow 実行時に渡した inputs を見やすい場所に表示してくれないため、どのような inputs で workflow を実行したのか辿りづらいのですが、 以下のような step を定義しておくと、inputs を job summary として run の画面に表示できるようになります。
steps:
- name: post test summary
uses: actions/github-script@v6
with:
script: |
parametersTable = [
[{ data: 'key', header: true}, { data: 'value', header: true }],
['branch', '${{ github.ref_name }}']
]
retryCommand = `gh workflow run --ref ${{ github.ref_name }} '${{ github.workflow }}'`
for ([key, value] of Object.entries(context.payload.inputs)) {
parametersTable.push([key, value])
retryCommand += ` -f ${key}='${value}'`
}
await core.summary
.addRaw("### Test Parameters\n")
.addTable(parametersTable)
.addRaw("\n### Retry Command\n")
.addCodeBlock(retryCommand)
.write()
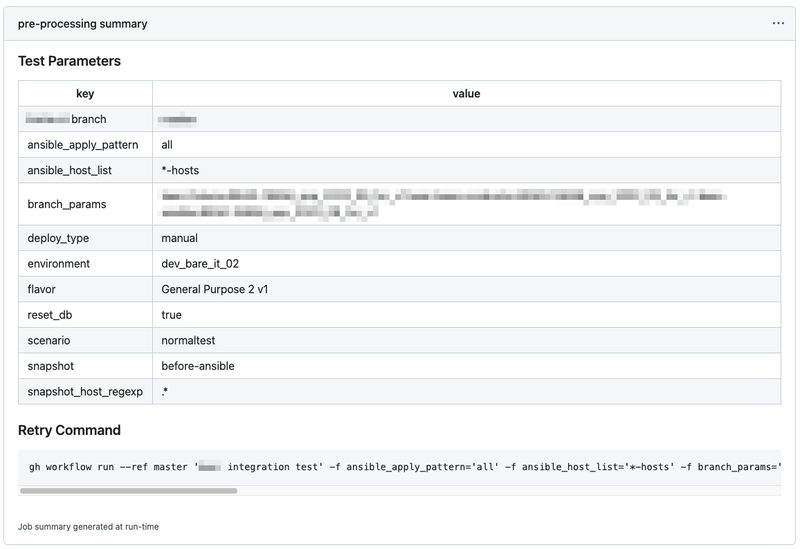
workflow の再実行コマンドの表示
上の図の下部に Retry Command というコードブロックが表示されていますが、これも工夫点の1つです。
workflow の再実行をしたい場合、同じパラメータで再実行するのであれば re-run の機能を使えばよいですが、少しだけパラメータを変更して再実行したい場合、inputs が多いとパラメータの再入力が面倒です。
そこで、同じパラメータで workflow を実行するためのコマンドを run の画面に表示し、パラメータを少しだけ変更して workflow を再実行するという操作を簡単に行えるようにしています。
composite action、reusable workflow による処理の再利用の例
GitHub Actions における処理の再利用といえば composite action や reusable workflow ですよね。
自分で独自に custom action を作成する場合、 選択肢としては Docker container や JavaScript を用いて作成する方法がありますが、個人的に一番使いやすいと思っているのが composite action です。
Docker container や JavaScript だと workflow ファイルの記法から外れて所定の形式に従って Dockerfile を書いたり JavaScript を書いたりする必要がありますが、composite action の場合は workflow ファイルと ほぼ同じ記法 で一連の処理を記述でき、学習コストやメンテナンスコストを抑えられます。
composite action で定義した step は呼び出し元の job で定義された step と同じように実行されるため、処理をまとめて複数の workflow で使い回せるようにしたり、workflow ファイルの巨大化を防ぐのに向いています。
composite actions の活用例
私たちのチームでは先程述べた単体テストを行うリポジトリが数多くあり、それぞれに workflow ファイルを作成しています。 数が多いと同じ処理は共通化したい欲が強くなるため、共通処理リポジトリを作成し、そこに様々な composite action を作成しています。
特に共通化の恩恵を受けているのが、以下のように workflow の最初と最後に定義している pre-processing と post-processing という job です。
jobs:
pre-processing:
runs-on: xxx
steps:
- uses: <org>/<repo>/.github/actions/unit-test/pre-processing@master
lint:
...
unit-test:
...
post-processing:
if: always()
needs: unit-test
runs-on: xxx
steps:
- uses: <org>/<repo>/.github/actions/unit-test/pre-processing@master
pre-processing と post-processing では以下のような処理を行っています。
post-processing job は if: always() により workflow が途中で失敗しても必ず実行されるようにしています。
- pre-processing
- 先程でも述べた workflow 実行時に渡した inputs の表示
- workflow 実行時に指定したブランチに紐づく PR のステータス更新(checks を pending に変更)
- workflow_dispatch だと PR の checks が自動更新されないため、手動で更新する必要がある
- post-processing
- workflow 実行時に指定したブランチに紐づく PR のステータス更新(checks を success や error などに変更)
- テスト結果の slack 通知
- 最近リリースされた Slack や Microsoft Teams で workflow についてのイベントを subscribe する機能 も非常に便利ですが、複数リポジトリのテスト結果を1つの Slack channel に投稿する場合、どのリポジトリからの通知なのかが若干分かりづらいため、私のチームでは workflow 側に定義した Slack 通知でもうしばらく運用しようかなと思っています。
reusable workflows の活用例
reusable workflow も私たちのチームにとって非常にありがたい機能です。
私たちのチームではベアメタルサーバー1とハイパーバイザー2の2つのプロダクトを開発しているのですが、 ハイパーバイザーはベアメタルサーバーの機能をがっつり利用しているため、ハイパーバイザーの結合テストではベアメタルサーバーの環境構築も必要となります。
このような事情のため、以下のように reusable workflow を呼び出すことで、ベアメタルサーバーとハイパーバイザーの結合テストの処理の共通化をうまく行っています。 マイクロサービスアーキテクチャにおける結合テストで、結合先のサービスをモック化できず自前で構築しないといけない場合には、このような reusable workflow の使い方が向いているのではないかと思います。
name: ベアメタルサーバーの結合テスト
jobs:
initialize-baremetal-environment:
uses: <org>/<repo>/.github/workflows/initialize_baremetal_environment.yml@master
with:
...
create-baremetal-instance:
...
name: ハイパーバイザーの結合テスト
jobs:
initialize-baremetal-environment:
uses: <org>/<repo>/.github/workflows/initialize_baremetal_environment.yml@master
with:
...
initialize-hypervisor-environment:
uses: <org>/<repo>/.github/workflows/initialize_hypervisor_environment.yml@master
with:
...
create-hypervisor-instance:
...
複数リポジトリ間での機密情報の扱い方
workflow 内で扱うパスワード等の機密情報の格納先の第一候補は secrets ですよね。 ですが、扱っているリポジトリが多く、各リポジトリで同じ機密情報を使いたい場合、各リポジトリに同じ secrets を設定していくのは手間です。
Organization Administrator の権限があれば、Organization に secrets を設定して各リポジトリから参照することもできますが、Organization Administrator ではない開発者からするとこの方法は取りづらいです。 secrets はコードとして管理できるものでもないので構成管理もしづらいです。
機密情報の参照用の自作 action
そこで私たちのチームで作成しているのが「機密情報の参照用の自作 action」です。 共通処理リポジトリに set-credentials という composite action を作成しており、この action を以下のように呼び出すことで、機密情報を環境変数に設定して利用可能にしています。
steps:
- uses: <org>/<repo>/.github/actions/common/set-credentials@master
with:
decryption_key: ${{ secrets.DECRYPTION_KEY }}
credential_names: test_key test_middleware_pasword
- runs: bundle exec rsepc ← 環境変数 test_key と test_middleware_password が export された状態で実行される
set-credentials action の中身は以下です。
name: set credentials
description: set credentials
inputs:
decryption_key:
required: true
credential_names:
required: true
description: ex) 'hoge_password fuga_password'
runs:
using: composite
steps:
- name: set credentials to GITHUB_ENV
working-directory: ${{ github.action_path }}
run: |
for credential_name in ${{ inputs.credential_names }};
do
credential_value=$(openssl xxxx -d -in secret.yml.enc -pass pass:${{ inputs.decryption_key }} xxxx | yq -r .${credential_name})
if [ $credential_value == null ]; then
continue
fi
echo "::add-mask::${credential_value}"
echo "${credential_name}=${credential_value}" >> $GITHUB_ENV
done
shell: bash
action のディレクトリに配置してある secret.yml.enc というファイルを inputs で与えた decryption_key で復号しつつ credentials_names で指定した値だけを抽出し、GITHUB_ENV に格納して job 内で利用可能にしています。 このとき add-mask の workflow command によってログに機密情報の文字列が直接表示されないようにしているのがポイントです。
この方法だと各リポジトリに設定する secrets は1つで済むことになり、それ以外の機密情報はコードとして構成管理できるので取り回しもしやすくなります。 (機密情報を環境変数に格納すると、悪意のある外部 action から情報を読み取られるリスクがあるため、その点は注意しながら使っています)
独自キャッシュによる効率的なファイル共有
長い workflow を作っていくと、どの部分から処理を再実行できるようにするかを意識して job を分割していくことになります。 job を分割していくと job 内で利用するファイルを job 間で共有したくなってきますが、こんなときに便利なのが GitHub Actions の機能として提供されている cache です。 この機能を使うことで、ブランチやタグの制約はありますが job 間や run 間、workflow 間でキャッシュしたファイル(ディレクトリ)を使い回すことができます。
公式の cache の注意点
ですが、この cache 機能では 機密情報のキャッシングを行うのは推奨されません。
私たちの workflow では、複数の job 間で Ansible のコードを使いまわしてテスト環境の構築などを行いたいと思い、Ansible のコードをディレクトリ丸ごとキャッシングしようとしていたのですが、この Ansible にはパスワードなどの機密情報が入っているため GitHub 公式の cache action でキャッシングするのは好ましくありません。
独自の cache action
そこで作成したのが以下のような独自 cache action です。
name: cache
description: save/restore local directory to/from remote storage or remove outdated directory on remote storage
inputs:
key:
required: false
default: ${{ github.run_id }}
path:
required: false
default: .
action:
required: true
type: choice
options:
- save
- restore
- clean
runs:
using: composite
steps:
- name: save local directory to remote storage by rsync
if: ${{ inputs.action == 'save' }}
run: |
<rsync コマンドにより指定したパスの内容をストレージサーバに保存>
shell: bash
- name: restore local directory from remote storage by rsync
if: ${{ inputs.action == 'restore' }}
run: |
<rsync コマンドによりストレージサーバから指定したパスの内容を取得>
shell: bash
- name: delete content last accessed at before 1 week
if: ${{ inputs.action == 'clean' }}
run: |
<ストレージサーバ上の古いファイルを削除>
shell: bash
inputs として key path action を与えて action を呼び出すことで、runner が動作する環境上の path の内容を、検証環境内のストレージサーバ上に key という名前で save したり、逆にストレージサーバ上の内容を runner 環境上へ restore できるように作っています。
検証環境内の転送速度はかなり高いため、多少サイズが大きいディレクトリをキャッシングしても読み書きにさほど時間はかかりません。
デフォルトでは key は github.run_id としており、実行した run 内でのみキャッシュが共有可能となるため、job 間でのデータ共有に特化した作りとなっています。
もちろん公式の cache でも紹介されているように hashFiles と組み合わせることでライブラリ部分だけをキャッシングするといった使い方もしています。
独自 cache のスコープ
この仕組みは、検証環境内の self-hosted runner でのみ動作させる前提であるため、意図的にキャッシュのスコープを制限しないようにしています。
つまり、異なるブランチ同士でも、はたまた リポジトリの垣根を超えても、key を適切に指定すればキャッシュを利用できるようにしています。
こうすることで、公式の cache を超えたリポジトリ横断での効率的な CI を実現することが可能となっています。
キャッシュの削除も定期実行 workflow で行っているため、ストレージサーバの容量がいつの間にか膨れ上がっていた、ということも防げるようになっています。

余談
先述した reusable workflow を使いつつ、job 間の依存関係を解きほぐしながら並列実行できる部分を積極的に並列実行するようにした結果、以下のような長い workflow ができあがりました。(workflow 自体の時間を短くできて re-run できる箇所も多くて良いのですが見づらい、、)

さいごに
いかがでしたでしょうか?
GitHub Actions には様々な機能があり、それらを組み合わせてオリジナルの workflow を作っていく楽しさがあります。 みなさんも時間があるときに GitHub Actions の公式ドキュメントを全部読み漁って、自分の workflow に適した機能をぜひ見つけてください。
次回の記事では CD にフォーカスした内容についてご紹介をしたいと思います。 CD は CI よりも課題が多く現在も検討を続けている最中のため、具体的な方針が固まったら記事を執筆する予定です。
最後になりますが、SDPF クラウドは国内最大級のクラウドサービスです。 開発メンバーは、数千台以上の物理サーバーの操作の自動化をはじめとした、技術的難易度の高い課題に取り組みつつ、日々より良いサービスにしようと邁進しております。 今回紹介した workflow を活用した CI 設計など、大規模サービスだからこそのやりがいのある課題もたくさん転がっています。
もし私たちのチームに興味を持たれた方は こちら からの応募をお願いいたします。
- 専有型の物理サーバーをオンデマンドに利用可能とするサービス。 https://sdpf.ntt.com/services/baremetal-server/↩
- ベアメタルサーバー上に vSphere ESXi や Hyper-V など代表的なハイパーバイザーを予めセットアップした状態で利用可能とするサービス。https://sdpf.ntt.com/services/vsphere/ https://sdpf.ntt.com/services/hyper-v/↩