
マネージド&セキュリティサービス部サービスプラットフォーム部門の田中です。 2023年度の下期にダブルワークという社内施策で、イノベーションセンター生成AIチームに参加しました。
その取り組みとして、本ブログの記事データを管理している GitHub リポジトリに LLM (大規模言語モデル) の1つである GPT-4 を用いた校正CIを導入してみました。 適切なプロンプトを得るための試行錯誤や、この記事自体を校正させてみた結果をお伝えします。
目次
背景
本ブログ記事のデータ管理やレビューには GitHub を利用しています。 投稿者は記事を執筆した後 PR (Pull Request) を出し、レビュアーが PRコメントで記事の修正を提案し、推敲していきます (なお、GitHubを活用した記事公開プロセスについては、別記事「開発者ブログをリニューアルしたついでにレビューと記事公開プロセスをいい感じにしたお話」で紹介していますので、ご興味がありましたらご覧ください) 。
レビュー観点の1つに、日本語の文章表現に誤りがないかといった校正的な観点があります。 この観点では、以前よりtextlint を用いた文章校正CIが GitHub Actions に実装されており、文末の句点有無などを機械的にチェックしています。
ただ、誤字脱字など textlint だけでは検出できない誤りも一定数あり、今回は LLM を用いることでより抜けのない校正ができるのではと考え、CIに組み込んでみることにしました。
LLM校正CIの詳細
校正CIに使う LLM は、記事全文を1度に入力できる Azure OpenAI の GPT-4 32k を利用することにしました。 システムプロンプトは以下を与え、マークダウン形式の記事全文を入力として与えます。
あなたは日本語文章を校正するアシスタントです。
与えられたマークダウン形式の文章で、誤字や文法誤りのある行を抜き出し、修正した行を出力してください。
その際、確実に修正すべき誤りのみを出力してください。
出力は、5個以下とし、より優先的に修正すべきものを出力してください。
また、以下のようなJSON形式で出力してください。
[
{"error_line": "...", "revised_line": "..."}
]
PRを契機に、編集のあった記事に対して校正CIが動き、以下のようにPRコメントの形で校正提案を表示するようにしました。 PRコメントの表示には、reviewdog を利用しています。

プロンプトの試行錯誤
上述のプロンプトは、複数のプロンプトを試行錯誤した結果得られたものです。 過去記事数件を入力とした結果を比較して、どれにするかを決めていきました。 レビュアーを担当される方の意見に、「指摘数が多くなると確認が大変になるかもしれない」というものがあったため、Recall よりも Precision *1 を重視する方針をとりました。 ここでは、試したものをいくつかご紹介します。
はじめは以下のようなプロンプトを与えてみました。
あなたは日本語文章を校正するアシスタントです。
与えられたマークダウン形式の文章で、誤字や文法誤りのある行を抜き出し、修正した行を出力してください。
その際、確実に修正すべき誤りのみを出力してください。
また、以下のようなJSON形式で出力してください。
[
{"error_line": "...", "revised_line": "..."}
]
すると、以下のような非常に多くの出力が返ってきました。
抜けた「を」を追加している1つめなどの良い修正提案もありますが、特に必要性を感じない修正提案や修正できていない出力 (error_lineとrevised_lineが同じもの) などが含まれており、ノイジーな印象です。
(文字が小さく申し訳ありません、読みづらい場合は拡大してご覧ください。なお、見やすさのために改行を追加したり差分文字に色をつけています)

そのため以下の1文を加えて、出力数を制限してみました (これが前章記載の最終的にCIに組み込んだプロンプトです) 。
出力は、5個以下とし、より優先的に修正すべきものを出力してください。
結果は次のようになりました。
指定した通りに出力数は5個までに減りました。
しかし、別に修正しなくてもよさそうな提案が依然残っています。

では、やってほしい文法誤りの修正例や誤字の修正例を与えればうまくいくのではと思い、別記事をもとにデータを用意して One-shot Prompting *2 を試してみました。
結果は以下となりました。
Zero-shot とは異なる有効な修正提案が見られる一方で、修正できていない出力が増えてしまっており、トータルではあまり改善がみられないといった印象です。
他記事でも出力を確認したのですが、同様の印象でした。
また、One-shot の分だけ入力が大きくなり LLM の出力にかかる時間が大幅に増えたため、Zero-shot でよさそうです。

また、もしかすると修正の分類も同時にさせることで精度が高まるかもしれないと考え、以下のプロンプトも試してみました。
あなたは日本語文章を校正するアシスタントです。
与えられたマークダウン形式の文章で、以下の誤りのある行を抜き出し、修正した行と誤りの分類を出力してください。
* 誤字
* 漢字変換誤り
* 文法誤り
* 表記誤り
その際、確実に修正すべき誤りのみを出力してください。
出力は、5個以下とし、より優先的に修正すべきものを出力してください。
また、以下のようなJSON形式で出力してください。
[
{"error_line": "...", "revised_line": "...", "error_type": "..."}
]
結果は以下となりました。
どうやら誤りの分類もうまくできていないようです。
また、同様 One-shot も試してみましたが、特にあまり変化は見られませんでした。

他にもプロンプトを英文にするなど試してみましたが、大きな変化は見られませんでした。 そのため、比較的シンプルなプロンプト (前章のプロンプト) を CI で使うことにしました。
この記事の校正結果
校正CIを導入後にこの記事を書いているので、もちろんこの記事にもCIは実行されます。 ここでは、その結果をお見せしたいと思います。
うまくいくといいなと思いながら、今回はわざとすこし誤字を放置して PR を出すと以下のコメントが1つ付きました!
有効な修正提案です!
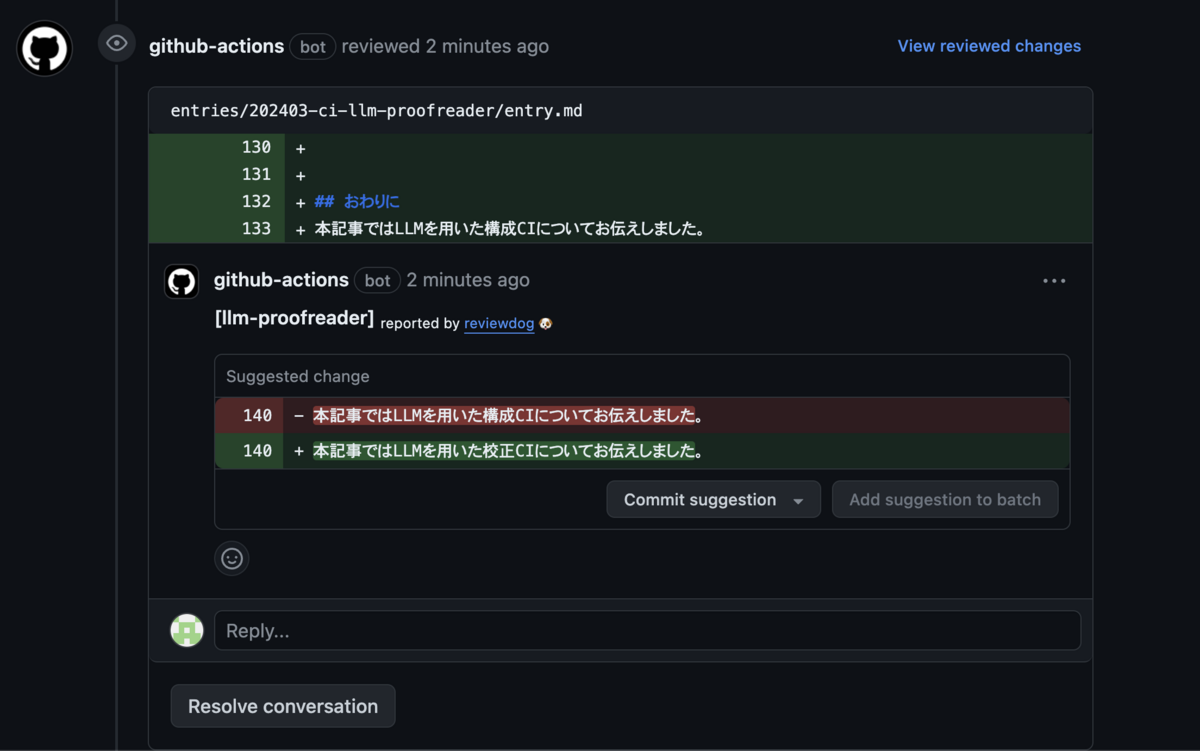
一方で、実は他に以下の誤字が記事に含まれていたのですが、これらは検出されませんでした。
しかし、別に修正しなくてもよさそうな提案が以前残っています。
また、もしかしると修正の分類も同時にさせることで精度が高まるかもしれないと考え、以下のプロンプトも試してみました。
修正提案は Recall よりも Precision 重視の方針をとっているものの、正直なところ、これらも検出してほしかったなあと思います。
おわりに
本記事ではLLMを用いた校正CIについてお伝えしました。 プロンプトの試行錯誤や、この記事での校正結果をご紹介しました。
校正という1つのタスクに対してさまざまなプロンプトを試してみることは、個人的に初めてのことだったため良い経験になりました。 また、GPT-4 クラスのモデルでも、一見簡単そうに思える日本語長文の文章校正でもまだ完璧でないということを知りました。
今回は環境面の点から、Azure OpenAI の GPT-4 32k を利用しましたが、現在続々と誕生している日本語メインで学習した LLM を用いるとどのような結果が得られるのかが気になります。 機会があれば、これらも今後試していけたらと思います。
校正CIは導入してまだ間もないため、一定期間 CI を試してみて、実際に利用した方の意見を収集し、改善や利用継続を判断する予定です。