
こんにちは、イノベーションセンターの田良島です。普段はコンピュータビジョンの技術開発や検証に取り組んでいます。7月27日から30日にかけて、画像の認識と理解技術に関する国内会議のMIRU2021が開催され、NTT Comからは計4名が参加し2件の発表をしました。
7/27(火)-7/30(金)にオンラインで開催される、画像の認識・理解シンポジウム(#MIRU2021) において、弊社イノベーションセンターから2件の研究成果を発表します!
— NTTコミュニケーションズ (@NTTCom_online) 2021年7月27日
映像AI分野の研究者・エンジニア・学生が集う国内最大級の学会です。
学生は参加費無料✨
ぜひご参加ください▼https://t.co/4RKvofBCSg
画像の認識・理解シンポジウム(#MIRU2021) において、本日28日(水)のプログラムに、弊社の田良島が登場します!
— NTTコミュニケーションズ (@NTTCom_online) 2021年7月28日
■15:00-15:30 口頭発表(ショート2)
■17:15-18:30 インタラクティブ1-2
「One Shot Deep Model for Multi-Actor Scene Understanding」
詳細はこちら▼https://t.co/4RKvofBCSg
画像の認識・理解シンポジウム(#MIRU2021) にて、弊社の丹野、市川、島田、木村、泉谷が研究成果を発表します!
— NTTコミュニケーションズ (@NTTCom_online) 2021年7月29日
■7/29(木) 15:45-17:00
「プロセスデータおよび炉内映像Optical-Flowに基づくマルチモーダル深層学習によるごみ焼却プラントの蒸気量推定」
詳細はこちら▼https://t.co/4RKvofBCSg
ここでは、参加メンバーでMIRUの報告をしたいと思います。
※なお私たちのチームでは、2021年8月4日現在エントリー受付中の職場体験型インターンシップに、AI/MLシステムとの統合を志向した、メディアAI技術の研究開発というポストを出しています。学生さんであればどなたでも応募可能です、ご興味あればぜひエントリーを検討ください!
MIRU2021
MIRUはコンピュータビジョンや画像映像認識を扱う国内最大級の学会です。個人的には、MIRUはSSIIと並んで画像映像認識を対象とした国内学会の二大巨頭をなしている印象があります。MIRUの方がよりアカデミックな雰囲気今年は過去最多の1,428名の参加があったとのことで、この技術分野の勢いをひしひしと感じます
MIRUの発表区分(招待講演等を除く)には口頭発表(ロング、ショート)とインタラクティブ発表があり、前者は査読があります。今回NTT Comからは、口頭発表(ショート)1件とインタラクティブ発表1件を行いました。以下ではまず、口頭発表の機会をいただいた "One Shot Deep Model for Multi-Actor Scene Understanding" についてご紹介します。
NTT Comからの発表
この研究では、不特定多数の人物(アクター)が写る映像を入力としてそのシーンを認識する問題に取り組んでいます。より具体的には、アクターを検出・追跡することに加え、各個人がとる動作と、アクターが集団でとる行動とを認識するという問題です。集団の行動は、チームスポーツでのセットプレイをイメージしていただくと分かりやすいかもしれません。アクターはシーンの中でお互いに影響を及ぼし合うので、特に個人の動作や集団の行動の認識では、アクター間の相互作用を捉えることも重要になってきます。
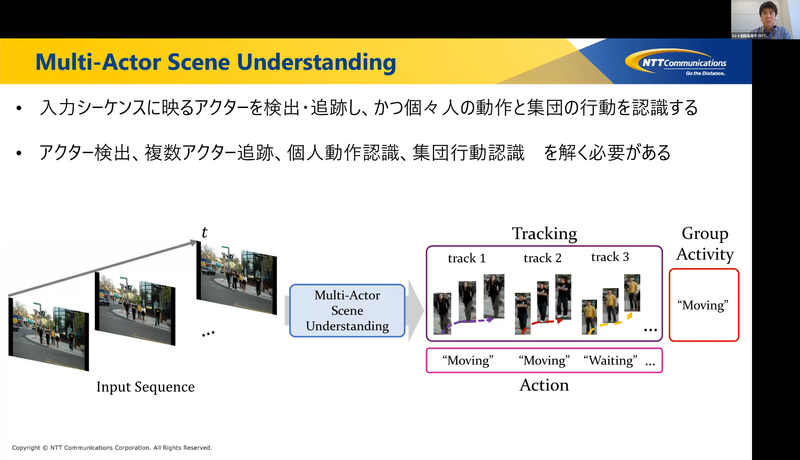
アプローチとして、アクターの検出・追跡・個人動作認識・集団行動認識の各サブタスクにState-of-the-art(SOTA)の方法を適用するというものがまず思いつきます。ですがこのアプローチには、全体の処理が冗長でかつ時間がかかってしまう問題があります。どのサブタスクにも何かしらの深層学習モデルを用意することになり、かつそれらはしばしば同じバックボーンであったりするので、当然と言えば当然です。一方で各サブタスクについて考えてみると、例えば同一人物は前後のフレームで同じ動作を継続している可能性が高いなど、それらは少なからず関係し合っていることに気が付きます。サブタスクは関係し合っているのに各々は独立に解くというアプローチには、改善の余地がある気がしてきました。
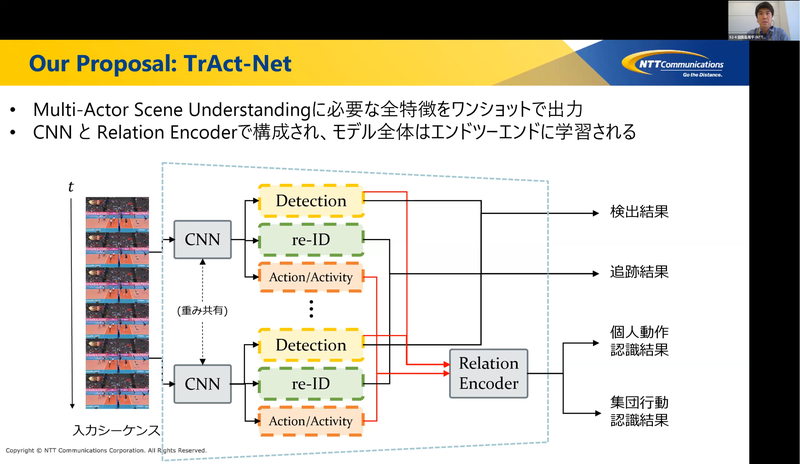
このモチベーションのもと、本研究では上記の全サブタスクを解くための特徴をワンショットで出力可能なモデルを提案しています。モデルは、各フレームから検出、追跡、行動/動作認識のための特徴抽出を担う畳み込みニューラルネットワーク(CNN)、行動/動作特徴をその相互作用を考慮して変換するニューラルネットワーク(Relation Encoder)とから構成しています。Relation Encoderでは、Transformer1で採用されているMulti-Head Attentionを拡張し、アクターの見え方と位置どちらの情報もふまえた特徴変換を実現しているところがポイントです。Volleyballデータセット2という代表的なベンチマークで評価したところ、各サブタスク毎にSOTAを適用するアプローチと同等の性能を、全体で約半分のモデルサイズおよび2倍の処理速度で実現できることが確認できました。
発表はZoomのウェビナーで実施し、およそ450名の方に聴講いただきました。またインタラクティブ発表はoViceで実施し、多くの方と直接ディスカッションさせていただきました。MIRU運営の皆様や聴講・質疑くださった皆様、まことにありがとうございました。この分野の競争は本当に激しいなと感じていますが、来年以降もぜひ私たちの取り組みを発表していけるよう頑張りたいです。
気になった発表
こんにちは、イノベーションセンターの鈴ヶ嶺です。普段は、クラウド・ハイブリッドクラウド・エッジデバイスを利用したAI/MLシステムに関する業務に従事しています。私からは3件気になった発表をご紹介します。
L1-2 動的光線空間のシングルショット撮影
概要
時間成分を含んだ動的な光線空間をシングルショット撮影から復元する手法を提案していました。光線空間とは様々な角度から撮影した画像を利用した多視点画像群で3次元ディスプレイなどに応用されます。従来的なカメラアレイでは装置の大規模化という課題、レンズアレイ型のplenoptic cameraでは一台のカメラで撮影できる代わりに視点ごとの空間解像度が低下するという課題があります。
例: 大規模なカメラアレイシステム3
提案法では、1台のカメラの開口面と撮像面で得られる情報を適切に2次元上に符号化し、CNNで5次元の動的な光線空間を復元し高解像度、高フレームレートを実現していました。さらにハードウェアによる検証も実施しており、実応用上の有効性も示していました。
所感
1台のカメラにある開口面と撮像面の関係が光線空間を表現していることを利用し、それを2次元空間上に符号化し復元する発想が面白かったです。さらにハードウェアでも検証が成功しており、今後の応用が期待される研究でした。
L2-1 連動する骨格動作の表現に適した時空間特徴の学習による人物運動予測法
概要
人物骨格動作の予測モデルにおいて動作特徴を時間的・空間的に集約するアーキテクチャを提案していました。
人物運動予測モデルには、2つ課題があります。まず直前の動作が支配的なケースや、長期的な動作が支配的なケースなど参照すべき特徴が異なる時間的問題です。次に、局所的な動作のみを考慮すれば良いケースと大域的な動作を考慮しなければならないケースなど参照する特徴が異なる空間的問題です。提案法では、時間的問題に対してMultiscale Temporal Convolution4のそれぞれの中間層を用いて参照時間の異なる特徴を表現することで時間的に集約しています。空間的問題に対しては、Encoderでは位置ベースの空間に出力し、Decoderに角度ベースの空間を入力として利用していました。それぞれの空間は位置と回転ベクトルのヤコビ行列から2つの特徴量空間間のヤコビ行列を生成して写像されます。これらの手法から、高い性能を示す予測結果を提示していました。
所感
EncoderとDecoderで位置と角度という異なる特徴を用いることで空間的に頑健な予測モデルにしている点が面白かったです。実際のデモを見ても高い精度で予測されており、興味深い研究でした。
L5-3 An Improved Inter-intra Contrastive Framework for Self-supervised Video Representation Learning
概要
この発表では、動画に関する対照学習5の手法Inter-Intra Contrastive(IIC)6を改良したIICv2を提案していました。
IICの全体像
主にIICv2は3つの要素が拡張されています。1つ目がAnchorであるフレーム群からFrame repeating, Temporal shuffling, Clip rotationなど操作をして対照学習の負例を生成するintra-negative sampleです。2つ目は画像に対してのStrong data augmentations7です。3つ目はContrastive lossが適用される空間に表現をマッピングする小さなネットワークであるprojection head8です。実験結果としてUCF1019, HMDB5110のデータセットにおいて最新のSOTAを上回る結果を示していました。
所感
動画に対する対照学習において、負例の生成方法や効果的なデータの水増し法などの様々な改良をしており勉強になりました。最終的な性能も現在のSOTAを上回っており、今後の参考にしたいと思いました。
こんにちは、イノベーションセンター新入社員の齋藤です。普段は、今回一緒に参加している鈴ヶ嶺と同じく、クラウド・ハイブリッドクラウド・エッジデバイスを利用したAI/MLシステムの研究開発をコンピュータビジョンを題材に取り組んでいます。私からも3件気になった発表をご紹介します。
L1-3 Can Vision Transformers Learn without Natural Images?
概要
Vision Transformer(ViT)11の性能は、学習に用いるデータセットサイズに強く影響を受けることが知られていますが、大規模なデータセットを用意するにはコストや倫理の問題が生じます。この研究では、数式から画像とラベルを自動生成するFractalDB12を用いてViTの事前学習を行うと、自然画像とその正解ラベルを用いて学習した場合とほぼ同精度が得られる、つまり自然画像を用いることなくViTの事前学習は可能だという驚くべき結果が示されています。
評価
・FractalDBで事前学習したViTとImageNet-1k13,Places-36514などを事前学習させたViTを比較した実験 ・FDSL(FractalDB-10k)とSSL(Jigsaw15, Rotation16, MoCov217, SimCLRv218)の比較実験を行っています。
Computer Vision and Pattern Recognition (CVPR). (2009) 248–255
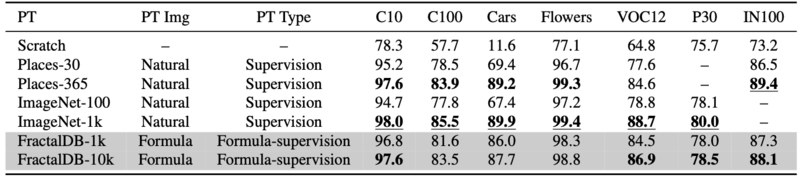 DeiTsで事前学習済みのFractalDB-1k/10kがImageNet-100/Places-30のモデルを上回り、ImageNet-1k/Places-365を上回ることはできませんでした。ですが、ImageNet-1kと肉薄した性能を持っていることが実験から分かりました。
DeiTsで事前学習済みのFractalDB-1k/10kがImageNet-100/Places-30のモデルを上回り、ImageNet-1k/Places-365を上回ることはできませんでした。ですが、ImageNet-1kと肉薄した性能を持っていることが実験から分かりました。
FractalDB-10KはSimCLRv2よりも若干精度を上回った結果を出しました。また、C10、VOC12、P30においては精度を上回った結果を出しています。
所感
今後、研究が発展することにより様々なタスクへの応用可能性が高いため、楽しみな研究の1つになりました。ソースコードもオープンソースで公開されているので、手元で試してみたいとも思います。
L2-4 Lightning-fast Virtual Try-on without Paired Data and Direct Supervision
概要
この研究では、弱教師あり学習を用いて、仮想試着を提案しています。仮想試着とは、Sourceの画像に対して、Targetの服に着せ替える技術のことで、応用先として、アパレルのECショップなどがあります。従来手法の、アノテーションコスト、メモリの消費量、テスト速度の問題を解決するものとして、本発表の手法 (LiVIRT) を提案しています。エンジンの中身としては、3つのネットワークを用いています。その中で無駄を取り払うなどの工夫によるネットワークの高速化を行っています。
評価
データにペアデータがある場合の実験では、教師あり学習の手法(CP-VTON19, SieveNet20)とLiVIRTの比較を行い、教師あり学習とほぼ同じ精度で仮想試着ができています。 ペアデータが存在する場合の実験においても、精度が良いことが実験で示されています。
所感
私が試したことのある仮想試着は、実際に着ている感があまりありませんでした。仮想試着の技術はECサイトのUX向上に大きく影響すると思うので、興味深く発表を聞かせていただきました。
L5-1 複屈折反射特性の計測に基づく材質識別
概要
材質識別は、資源の開発やリサイクル、自動運転など様々なシーンで求められる技術です。この研究では、複屈折反射特性から抽出された特徴量をU-net21に入力してクラス分類を行っています。
評価
79種類の材質を、金属・木材・布・樹脂・石材に材質クラスの識別を行っています。U-netと比較する手法としては、k近傍法を用いています。結果として、5種類の材質クラスの識別平均正解率は、U-netで0.90、k近傍法で0.87となり、U-netを用いた方が正解率が高いことが確認できました。
所感
複屈折反射特性から特徴量を求めている点が面白いと感じました。モデルのバックボーンを変えた場合の精度変化も気になるところです。
最後に
MIRU2021の模様をご紹介しました。NTT Comでは、今回ご紹介した学会での発表調査はもちろんのこと、画像や映像、更には音声言語も含めた様々なメディアAI技術の研究開発に今後も積極的に取り組んでいきます。また一緒に技術開発を進めてくれる仲間も絶賛募集中です。
- アカデミックな研究に注力したくさん論文を書きたい
- 最新の技術をいちはやく取り入れ実用化に結び付けたい
- AIアルゴリズムに加え、AI/MLシステム全体の最適な設計を模索したい
という方々に活躍していただけるフィールドが弊社には多くあり、いくつか新卒採用のポジションを用意する予定です。エントリーの受付開始は2022年1月以降となる予定ですが、よろしければぜひ新卒採用ページをウォッチしていただけると嬉しいです
さらに冒頭でも述べた通り、2021年8月4日現在、NTT Comでは夏の職場体験型インターンシップのエントリーを受付中です。私達のチームからも、AIエンジニアカテゴリにAI/MLシステムとの統合を志向した、メディアAI技術の研究開発というポストを出しています。インターンを通じて、会社やチームの雰囲気、そして私たちの取り組みを知っていただく機会にできればと考えています。皆様のご応募、心からお待ちしています!
-
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).
arXiv:1706.03762↩ -
Ibrahim, M.S., Muralidharan, S., Deng, Z., Vahdat, A., & Mori, G. (2016). A Hierarchical Deep Temporal Model for Group Activity Recognition. 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 1971-1980.↩
-
裸眼立体ライブ映像システムを支えるカメラアレイの開発 https://news.mynavi.jp/photo/article/20080625-cameraarray/images/004l.jpg↩
-
Lea, C., Flynn, M. D., Vidal, R., Reiter, A., & Hager, G. D. (2017). Temporal convolutional networks for action segmentation and detection. In proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 156-165).
arXiv:1611.05267↩ -
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., … & Krishnan, D. (2020). Supervised contrastive learning. arXiv preprint arXiv:2004.11362.
arXiv:2004.11362↩ -
Tao, Li, Xueting Wang, and Toshihiko Yamasaki. “Self-supervised video representation learning using inter-intra contrastive framework.” Proceedings of the 28th ACM International Conference on Multimedia. 2020.
arXiv:2008.02531 ↩ -
Grill, J.-B., Strub, F., Altche, F., Tallec, C., Richemond, P. H., ´Buchatskaya, E., Doersch, C., Pires, B. A., Guo, Z. D., Azar, M. G. et al.: Bootstrap your own latent: A new approach to self-supervised learning, Advances in Neural Information Processing Systems (2020)↩
-
Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020, November). A simple framework for contrastive learning of visual representations. In International conference on machine learning (pp. 1597-1607). PMLR.↩
-
Soomro, K., Zamir, A. R. and Shah, M.: UCF101: A dataset of 101 human actions classes from videos in the wild, arXiv preprint arXiv:1212.0402 (2012).↩
-
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T. and Serre, T.: HMDB: A large video database for human motion recognition, IEEE International Conference on Computer Vision, pp. 2556–2563 (2011).↩
-
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., … & Houlsby, N. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929.
arXiv:2010.11929↩ -
H. Kataoka, K. Okayasu, A. Matsumoto, E. Yamagata, R.Yamada, N.Inoue, A. Nakamura, and Y. Satoh. Pre-training without Natural Images. In Asian Conference on Computer Vision (ACCV), 2020.
arXiv:2006.10029↩ -
Deng, J., Dong, W., Socher, R., Li, L.J., Li, K., Fei-Fei, L.: ImageNet: A LargeScale Hierarchical Image Database. In: The IEEE International Conference on↩
-
Zhou, B., Lapedriza, A., Khosla, A., Oliva, A., Torralba, A.: Places: A 10 million Image Database for Scene Recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 40 (2017) 1452–1464↩
-
Noroozi, M., & Favaro, P. (2016, October). Unsupervised learning of visual representations by solving jigsaw puzzles. In European conference on computer vision (pp. 69-84). Springer, Cham.↩
-
Gidaris, S., Singh, P., Komodakis, N.: Unsupervised Representation Learning by Predicting Image Rotations. In: International Conference on Learning Representation(ICLR) (2018)
arXiv:1803.07728↩ -
Chen, X., Fan, H., Girshick, R., & He, K. (2020). Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297.
arXiv:2003.04297↩ -
Chen, T., Kornblith, S., Swersky, K., Norouzi, M., & Hinton, G. (2020). Big self-supervised models are strong semi-supervised learners. arXiv preprint arXiv:2006.10029.
arXiv:2006.10029↩ -
Bochao Wang, Huabin Zheng, Xiaodan Liang, Yimin Chen, Liang Lin, Meng Yang.“Toward Characteristic-Preserving Image-based Virtual Try-On Network”.arXiv preprint arXiv:1807.07688.
arXiv:1807.07688↩ -
Surgan Jandial, Ayush Chopra, Kumar Ayush, Mayur Hemani, Abhijeet Kumar, Balaji Krishnamurthy.“SieveNet: A Unified Framework for Robust Image-Based Virtual Try-On”.arXiv preprint arXiv:2001.06265.
arXiv:2001.06265↩ -
O. Ronneberger, P. Fischer, T. Brox, ”U-net: Convolutional networks for biomedical image segmentation”, MICCAI, 2015↩
{kind=link}