
こんにちは、デジタル改革推進部の河合と浅野です! 私たちデジタル改革推進部では、普段から全社で使うためのデータ分析環境の開発・提供を行っています。 今回は社内でデータ分析コンペティションを開催したのでその内容を報告します。
社内データ分析コンペティションとは?
社内にある様々なデータ活用課題をコンペティション形式に落とし込み、全社で知恵をしぼって解こうという試みです。 もともと、データサイエンスの界隈ではKaggleやatmaCupと呼ばれる分析力を競うコンペが行われており、課題や技術を集団で共有して解く文化があります。 今回はそれらを参考に、社内のデータを使ったコンペを 6/21~7/2 の2週間にかけて初開催しました。
開催にあたって期待したことは、以下の3つです。
- 様々な部署に散らばっているサービス特有のドメイン知識、データ、分析技術を一箇所に集める
- 優れたソリューションを集合知によって短期間で探し出す
- データ活用人材の育成や発掘
上記を満たすために、KaggleやatmaCupを参考にコンペのルールを工夫して作りました。
具体的には下記のような点です。
- 予測結果の設定
- 特定期間に過学習してしまうのを避けるため、予測範囲を2種類に分けて評価する。
- 一方は予測値を投稿すると即時計算されるpublic scoreに、もう一方は最終日まで結果がわからず順位決めに使われるprivate scoreとして評価する。
- 情報共有に対する評価
- 参加者は分析結果を適宜共有する(Discussion)ことができ、そこにいいねやコメントをつけることが可能。いいね数が上位の方も表彰対象とする
- チームでの参加も可能とする
コンペのテーマと進め方
第一回のテーマとして、インターネットのトラフィック量(※通信量のこと)の将来予測を設定しました。 必要な分析技術の範囲としては、複数地域のトラフィックを予測する多変量の時系列予測となります。スコアとしては平均絶対パーセント誤差(MAPE)を使いました。
コンペティションは以下のようなスケジュールで実施しました。
- 6/21(月) 開会式: テーマの説明
- 6/22(火) 初心者向け講座#1
- データの読み込みからベースラインのsubmitまでのチュートリアル
- 6/24(木) 初心者向け講座#2
- 応用コンテンツの紹介。 EDA/validation評価について
- 6/28(月) もくもく会#1
- 6/29(火) もくもく会#2
- 7/2(金) ~17:30 コンペ終了
- 7/6(火) 結果発表・閉会式
- 7/14 成績上位者の発表. 分析内容の共有会
今回のイベントはフルリモートのオンライン開催でしたが、 コンペ初参加の方でもイベントに入りやすいように、初心者向け講座を複数回 また分析作業内容や疑問点を解消するためのもくもく会も複数回実施しました。
これらに参加すれば、誰でも共有されたサンプルコードを使って 予測結果を作って投稿できるような形にしています。
コンペ環境
デジタル改革推進部では、NTTcom内のデータ活用を推進するためDLXと呼ばれる全社員が使える分析基盤を開発しています。 今回はこの分析基盤にコンペ参加者に向けてJupyter labベースの環境を用意し、PythonやRを使って分析できるようにしました。 データセットはhadoop上に置き、trinoと呼ばれる分散SQLクエリエンジンを使って自由に参加者がSQLを叩いてアクセスできるようになっています。
また、某コンペサイトを参考に、社内コンペサイト「Saggle」を用意し、予測結果の投稿やコードの共有ができるようにしました。
分析Notebookの共有
リーダーボード
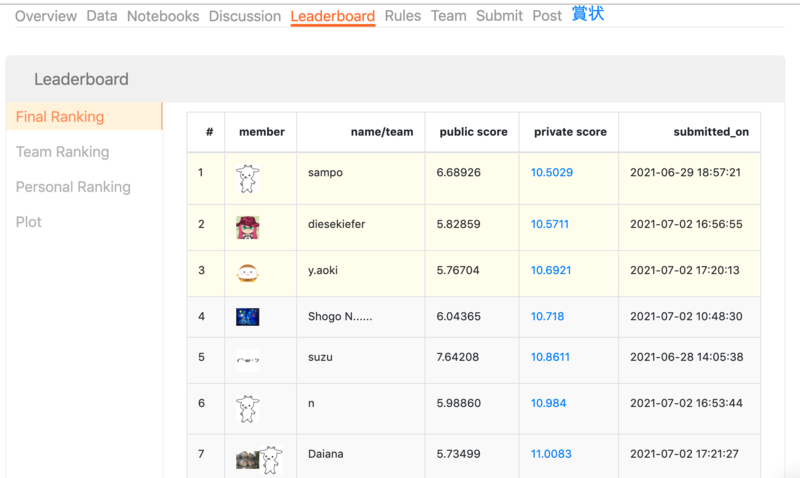
結果
50名を超えるエントリーをいただき、最終的なsubmit回数は800回を超えました。
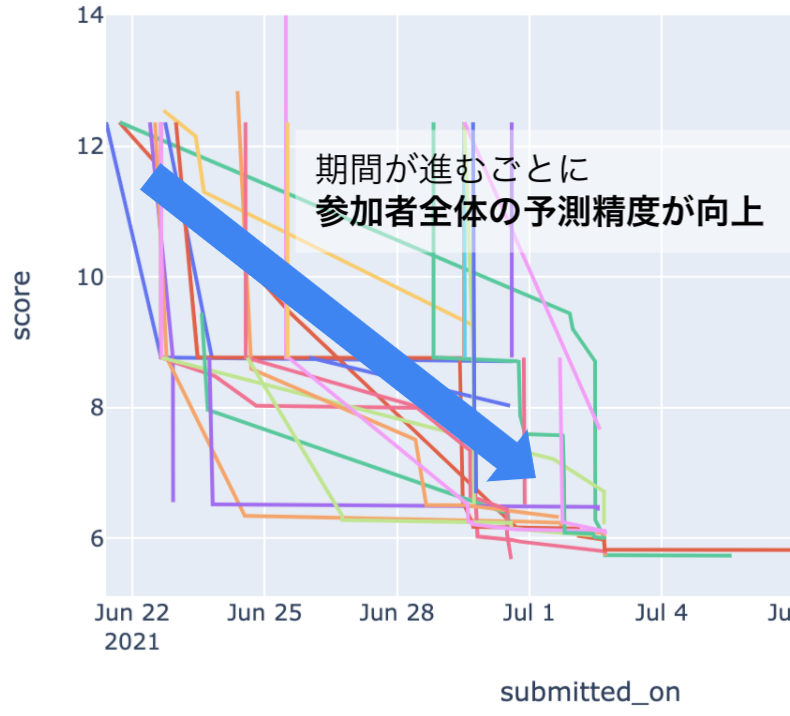
参加者の予測誤差のスコア(public)の推移は以下のような感じでした。
コンペが進むにつれ全体のスコアが良くなっていく様子がみて取れます。
一方でprivate scoreの方も合わせて見てみると、分析コンペでありがちな過学習が発生していたのがわかります。
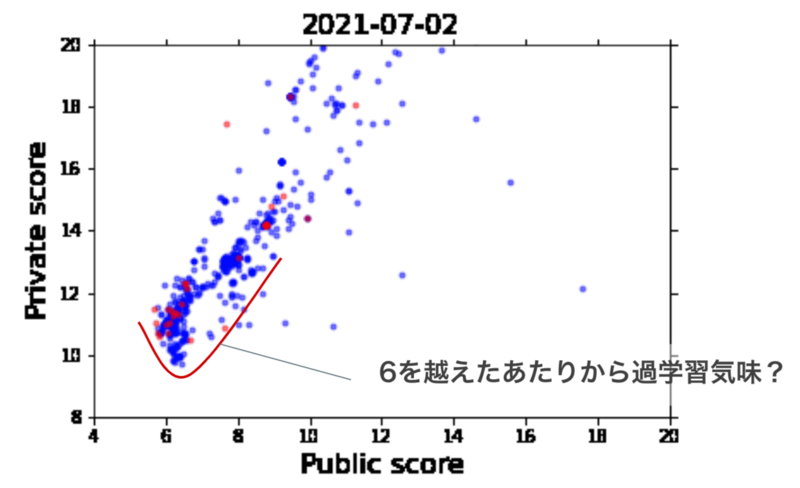
今回はsubmit回数の制限を行わなかったこともあり、public scoreを追い求めすぎてprivate scoreが下がり、最終順位が下がる(shake down)という悲しい思いをされた参加者が多かったと思います。
順位発表後には、スコア上位者の方に使った手法を解説していただきました。
参加者の声
開催後、参加者の方からアンケートを取ったところ
課題がやや難しかったという意見もありましたが、
「知識が無いなりにも操作ができる環境・サンプルコード準備を始め、基礎的な質問への応援サポートに感謝感謝でした」「初めてのコンペ参加でしたが、ディスカッションも盛り上がり、いろいろな気付きがあって大変楽しむことができました」
といった意見を多数いただくことができました。
このうち90%以上の方から、「次回開催があれば他の社員にも参加をお勧めしたい」と回答をいただき、社内でも非常にポジティブな意見をいただくことができました。
まとめ
今回は社内の実データを使った分析コンペの開催報告でした。
今回の分析コンペによって下記のような結果が得られました。
- 共通のデータを使って多様なスキルやバックグラウンドを持つ社員が議論しながら一つの分析課題に取り組むことができた
- 2週間という短い期間でデータの理解とより高精度な予測モデルを作成することができた
- 初めてコンペに参加した方/分析知識がなかった方を含め50名以上の方が、データ分析、予測までできるようになった
今後は、アイデアソンなどもう少し範囲を広げて分析コンペを定期開催できるよう目指していきたいと考えています。 これからもコムのデータ活用が盛んになり、業務やサービスをよりよくしていけるように取り組んでいきます!