
こんにちは、イノベーションセンターの三島です。 本記事では、次世代の監視技術として期待されるTelemetry技術についてご紹介します。
この記事について
本記事では下記の3点を共有します。
- 従来の監視技術が抱える課題とTelemetryの可能性
- Telemetryの技術概要と、各社の実装状況
- NTT Comのネットワーク上で検証し得られた知見と、期待されるユースケース
従来の監視技術が抱える課題
ネットワーク運用においては、障害検知やパフォーマンス分析のため監視技術が重要となります。
従来のネットワークでは、SNMP(Simple Network Management Protocol)と呼ばれる技術が広く利用されています。
SNMPの仕組みを図1に示します。SNMPはUDPベースなネットワーク監視技術です。データモデルはMIB(Management Information Base)と呼ばれるデータベースに定義されており、ベンダ共通の標準MIBと固有の拡張MIBが存在します。
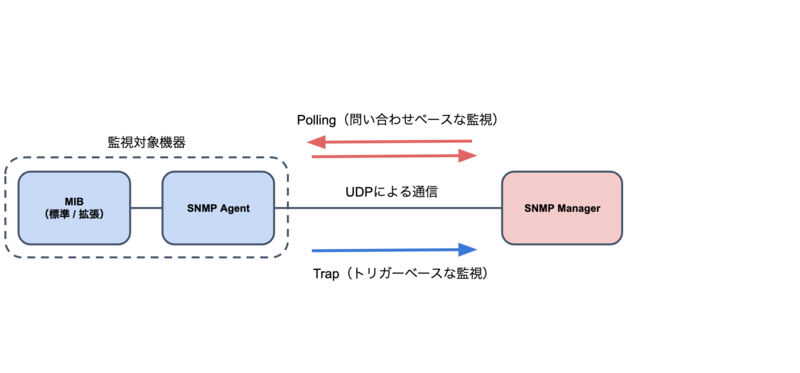
SNMPの情報取得者をSNMP Manager、情報発行者をSNMP Agentと呼びます。情報の取得手法として、SNMP Managerがリクエストベースに情報を取得するPollingと、SNMP Agentがトリガーベースに情報を送信するTrapが存在します。
従来のSNMPが抱える課題として、下記の3点が挙げられます。
- 高負荷な処理構造
- マルチベンダ環境における管理の煩雑さ
- N対N構成での規模性の限界
1.高負荷な処理構造について図2に示します。

ネットワーク監視ではトラフィック量や機器の負荷情報(Memory・CPU・温度等)の取得が求められます。しかしSNMPのPollingはリクエストベースであるため、高精細な情報を取得するために間隔を狭めると、CPU負荷の増大と処理時間の増加が課題となります。
2.マルチベンダ環境における管理の煩雑さについて図3に示します。

SNMPでは標準MIBが乏しく、例えばCPU使用率等のパラメータを取得できない課題が存在します。 そのため、マルチベンダな環境で同じ情報を取得するためには、機種ごとに固有な拡張MIBのOID(Object ID)を指定する必要があり、管理コストが増大します。
3.N対N構成での規模性の限界について図4に示します。

大規模なネットワークでは、データ利活用のため複数のデータ利用者が同じ機器の情報を取得することが考えられます。(例えば利用者Aはトラフィック量を可視化のために取得し、利用者Bはインターフェース状態をDown検知のために取得するなど)
SNMPではAgentとManagerを1対1のUDPで接続して監視するため、N対N構成ではAgent/Managerの組み合わせ分のUDP接続が必要となり、受信側で処理可能なメッセージに限界が生じます。 また、送信先・監視先ごとに異なる値を取得したい場合、組み合わせに応じてSNMP Agent/Managerに定義する必要があり、管理コストが増大します。
まとめとして、SNMPは下記3種の課題を抱えています。
- 高負荷なプロトコル構造による取得可能な情報精度の低下と、リアルタイム性の損失
- 標準MIBの乏しさによるマルチベンダ環境における管理の煩雑さ
- N対N構成構築時の規模性の課題
これらを解決する監視技術として、Telemetry技術が期待されています。
Telemetryについて
Telemetryは次世代のネットワーク監視技術であり、各社による検討や実装・OpenConfig等による標準化が進められています。
Telemetryは、一般的には下記3つの特徴を持つよう設計されています。
- SNMPと比較し低負荷なプロトコル設計による高精細でリアルタイムな情報取得
- OpenConfigによるベンダフリーな情報取得
- Pub/Subモデルの導入が容易な設計による高い規模性
これらの特徴から、前節で挙げたSNMPの課題を解決する技術として期待されています。
Telemetryは、Pub/Subモデルと呼ばれるデータの送受信モデルを採用しています。
Pub/Subモデルについて図5に示します。

Pub/Subモデルは下記3つの要素から構成されます。
- Publisher: 発行者 (送信者)。メッセージを発行する
- Broker: 仲介者。メッセージを仲介する
- Subscriber: 購読者 (受信者)。メッセージを取得し活用する
Pub/Subモデルの利点として、① メッセージの送信者・受信者がお互いを直接認識する必要がなく、非同期かつ疎結合である点、②Brokerを介して1対N、N対N構成が取れるため、規模性の高い点 が挙げられます。情報はTopicという属性で管理され、Publisher・SubscriberはTopicを指定することにより情報を送信・受信します。
図6にTelemetryのパイプライン構成を示します。

Telemetryパイプラインは下記の要素から構成されます。
- Publisher: データの発行元であるネットワーク機器
- Broker: Pub/Subの多重化を行う仲介役
- Subscriber: データの受け取り・利用をするアプリケーション
Pub/Subモデルの利点は失われますが、上記の構成以外にPublisherとSubscriberを直結する構成も可能です。
以降でそれぞれの要素について解説します。
Publisher
Publisherはメッセージの発行者であり、下記の3つの要素から構成されます。
- 監視対象となるネットワーク機器
- 監視対象機器とCollectorを繋ぐTransport部分
- Publisherからデータを受信するCollector
監視対象機器に関する概念として、情報モデルと接続方式の分類についてご説明します。
機器の情報モデルには、主にOpenConfig・ベンダネイティブの2種が存在します。OpenConfigはベンダニュートラルな利用を想定して標準化が進められているネットワークコンフィグのモデルであり、YANGに従い定義されています。一方ベンダネイティブは製品ごとに固有の情報モデルであり、一般的にOpenConfigよりも対応状況が良く、扱うことのできる情報も豊富な傾向があります。
機器が発行する情報は、Sensor-Pathと呼ばれるデータパスにより予め指定されており、決められた間隔でメッセージを発行し、Collectorへと送信します。
下記にSenrsor-Pathの例を示します。Sensor-PathはYANGのツリー構造に合わせて情報を取得するためのデータパスであり、SNMPにおけるOIDに近い概念です。
- OpenConfig: Interfaceに関する情報全般(Configuration/State/Statistic含む)
- “/interfaces/”
- OpenConfig: Interfaceごとの入力パケットカウンタ(単位: byte)
- “/interfaces/interface/state/counters/in-octets”
- OpenConfig: xe-0/0/0の入力パケットカウンタ(単位: byte)
- “/interfaces/interface[name='xe-0/0/0']/state/counters/in-octets”
- Juniper ベンダネイティブ: Interfaceに関する情報全般
- “/junos/system/linecard/interface/”
例のように、深いパスを指定することで取得する情報を細かく指定できます。
また、OpenConfigとベンダネイティブでは同じ情報を取得する場合でも異なるパスを指定する必要があります。
2021年8月時点の実装では、同じOpenConfigでもベンダにより対応状況が異なるため、各社のドキュメントを確認し取得するSensor-Pathを決める必要があります。
次に接続方式の違いについてご説明します。Telemetryでは、情報を発行するPublisherと受け取るCollectorの接続方向により、Dial-InとDial-Outの接続方式が存在します。図7にそれぞれぞれの概念を示します。

Dial-InはCollectorがPublisherに接続する手法です。利点としてはgRPCによる自動化を行っているネットワークの場合、機器に設定されたgNMIを利用して情報を取得できるため、Telemetry用追加設定の不要な点が挙げられます。
一方Dial-OutはPublisherがCollectorに接続する手法です。利点としてはCollector側が監視するPublisherのリストを管理する必要がないためCollectorをステートレスに設計可能であり、Dial-Inに比べて規模性が高い点や、Publisher側にもACLによる制御が不要となる点が挙げられます。
上記より、特別な理由がない場合は管理コストを考慮しDial-Outを採用することをお勧めします。ただし、例えばgRPCによる運用自動化を行っているネットワークなどでは、Dial-InのTelemetryが容易に導入可能な場合もあります。また、2021年8月時点では、ベンダによりDial-In/Dial-Outの対応状況が異なるため、注意が必要です。
次にTransport部分について説明します。Transportは監視対象デバイスとCollectorを繋ぐ転送の役割を持ちます。
TransportはEncodingとEncapsulationの要素から成り立ちます。
- Encoding: メッセージの形式。JSON、GPBなどから選択可能
- Encapsulation: 通信形式。TCP/UDPやgRPC、NETCONFなどを選択可能
SNMPはUDPによる通信のみを採用していましたが、Telemetryではメッセージをどのような形式で記述し、どのような通信形式で送るかを決めることができます。取得したい情報の性質や、運用で既に採用しているプロトコルなどを考慮しながら決めることをお勧めします。
CollectorはPublisherが発行したメッセージを受信する役割を持ちます。2021年8月時点の主なCollector実装を下記の表にご紹介します。
| ベンダ | OSS実装 | ベンダ純正実装 ※Subscriber機能も兼ねる |
|---|---|---|
| Arista | ockafka Openconfigbeat |
Arista CloudVision |
| Cisco | Pipeline Telegraf/Fluentd等の専用Plugin |
Crosswork Health Insights |
| Juniper | Jtimon Telegraf/Fluentd等の専用Plugin |
Paragon Insights |
| SONiC | gnxi(単発で取得するCLIツール) gNMIc |
- |
上記でご紹介したベンダ純正実装は、単体のCollectorではなくSubscriberとしての可視化や自動化の機能を備えています。
Collectorごとに特徴や存在する機能が異なるため、例えばPublisherのグループ化やKafkaとの連携など、必要な機能を考慮し選定することをお勧めします。
Broker
Brokerはメッセージの仲介者であり、Message Queueが該当します。
Message Queueはメッセージを中継する要素であり、主な実装としてはApache Kafkaや、Public CloudにおけるCloud Pub/Sub・SQSなどが挙げられます。
一般的な実装では、クラスタリングやミラーリングなど、冗長化を行う仕組みを持つことが多いです。図8に一般的なBrokerのMessage Queue的な役割を示します。

Publisherが発行するメッセージにはTopicとデータが含まれています。Brokerは受信したメッセージをTopicごとのキューに格納した後、Subscriberからの購読に応じてメッセージを送信します。
Subscriber
Subscriberはメッセージの受信者であり、データを受け取り利用する要素です。
Subscriberはユースケースごとに様々な機能・パイプラインを持ちます。一般的には①リアルタイムな監視 & 詳細な情報に基づく可視化・分析、②アラート、③設定の自動化/自己治癒 などが考えられます。
検証構成と取得結果
ここからは、NTT Com内にて実施した検証についてご紹介します。
今回の構成では、NTT Comの社内ネットワーク環境において検証を実施しました。図9に構成図の一部を示します。

検証ではPublisher/Subscriberをそれぞれ多重化し、Brokerに収容しています。
監視対象の機器はArista・Cisco・Juniperと、Whiteboxな伝送装置に搭載されたSONiCの4ベンダを採用しています。また、SubscriberはオンプレミスのGrafanaによる可視化を行うと同時に、Google Cloud Platform上のKafkaにミラーリングを行い、Public Cloudと連携が行えることも検証しました。
図10、図11にそれぞれから取得した実際のデータをJSON形式で示します。

図10はArista機器で発行し、ockafkaを通じ取得したデータの例です。図の通り、データは単発のJSON型となっています。

一方、図11はその他の機器から取得したデータの例です。図の通り、Juniper/TelegrafではネストされたJSON型になっており、SONiC、gNMIcはJSON型の中にリストが含まれています。また、Cisco/Pipelineでは複数のJSON型がリストに含まれる形式であることがわかります。
このようなデータは直接InfluxDBに取り込むことができないため、整形処理が必要となります。LogstashやTelegrafといったコレクタには整形機能が存在しますが、デバッグが難しい、複雑な条件分岐を書きにくいなど、汎用性に問題がありました。
そこで、今回の検証ではデータ整形機を作成し対応しました。図12にデータ整形機を含めたフローを示します。
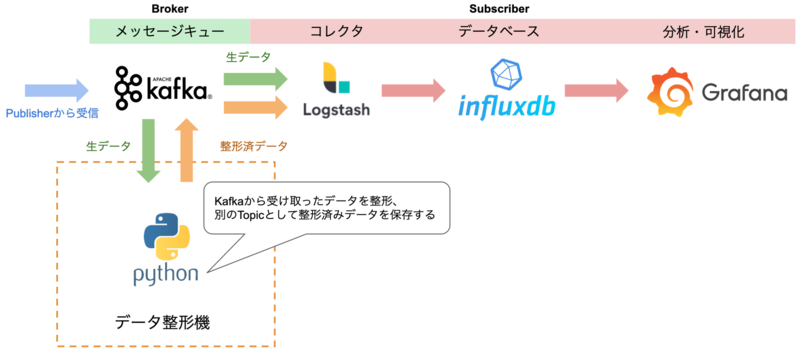
作成したデータ整形機は、まずKafkaから生データが含まれるTopicを購読し、データを取得します。取得したデータをPython Scriptで整形した後、Kafkaに対して取得したものとは異なるTopicでメッセージを発行します。これにより、Subscriberがデータ整形機の発行したTopicを指定することで、整形後のデータを取得できるようにしています。
図13に、実際に取得したデータをGrafanaで可視化した例を示します。

今回の検証では、TelemetryとSNMPで、Interfaceの受信したTraffic量の可視化を行いました。Telemetryは1000ms(Junosのみ2000ms)、SNMPでは負荷を考慮し、一般的に1分以上の間隔で取得することが多いですが、今回はPrometheusが取得可能であった15秒間隔でデータを採り、比較しています。
図13ではマイクロバーストの検知を想定しバーストトラフィックを生成しております。結果の通り、Telemetryではリアルタイムで複数のスパイクが観測されますが、SNMPでは、Pollingによる遅延が入った後、なだらかな山となり可視化が行われていることが読み取れます。
検証を通じて得られた知見
ここからはNTT Com内での検証を通じて得られた知見と期待されるユースケースをご紹介します。
導入時に考慮すべき点として、下記3点が挙げられます。
1. 対象機種ごとにパラメータを分ける手法の検討
現時点のTelemetryでは、ベンダごとに①Collector、②Dial-In / Dial-Out、③OpenConfig/ベンダネイティブの選択を含めたSensor-Path などのパラメータを指定する必要があります。
マルチベンダ環境における効率的な管理のため、例えばNetbox・Zabbix等でデバイス情報を管理しているネットワークでは、それらの情報と組み合わせ、ベンダごとに設定を切り替える仕組みを開発することで、管理コストを下げることが期待できます。
2. データの保持期間と粒度
Telemetryはms単位での情報取得が可能であるため、取得した大量のデータを長期にわたって保持することが現実的ではありません。
そのため、Telemetry導入の際にはデータの保持期間や保持する時間的な粒度などの事前検討が必要となります。
これらに該当するユースケースは主に ① 取得した瞬間の閾値による処理(その瞬間の詳細なデータが必要)、② 障害発生後の切り分け(1日-2日以内の詳細なデータが必要)の2種が想定されます。①、②どちらのユースケースでも、詳細なデータは1日-2日のみ保持し、それを過ぎたものはデータを時間単位などで集約して保持すれば良いと考えます。
3. 監視基盤の性能
2.の内容とも関連しますが、Telemetryを導入する際にはネットワーク規模と取得データと量・保持期間に従い、事前に監視基盤のメモリやストレージ等のリソースを計算しておく必要があり、導入前の検証が必須となります。
Telemetryに期待されるユースケース
これまでの結果より、現時点のユースケースとして下記の3点を考えています。
- シングルベンダ環境におけるリアルタイムな情報収集
- gNMIを通じたコンフィグ投入等、自動化技術との組み合わせ
- 他の監視技術との連携
1.については、OpenConfigでの実装が追いついていない部分もベンダネイティブなSensor-Pathにより情報を取得でき、またベンダごとの独自機能や純正Collectorの利用が可能です。さらに、ベンダ固有の実装(Cisco Event Driven TelemetryやMellanox What Just Happened等)を利用できるなどの利点が存在します。
2.については、共有のgNMIを利用して監視・自動化が可能である利点を生かし、Telemetryにより振る舞いを監視し、閾値や機械学習ベースでのコンフィグ変更・自己治癒などの利用が考えられます。
3.については、例えばTelemetryのStatisticをxFlowのリアルタイムなフローと組み合わせ利用する、SyslogアラートをトリガーとしTelemetryのState・Statisticを保存するなど、高精細な情報を生かす手法が考えられます。
またどの用途についても、今後OpenConfig対応の充実やCollector・Dial-Out対応などの統一により、マルチベンダ対応が進むことにより、より利用しやすい技術となると期待しています。
まとめ
NTT Comでの技術検証を通じ、Telemetryの下記3点の特徴を検証しました。
- SNMPと比較し低負荷な設計によるリアルタイムな情報取得
- OpenConfigによるベンダフリーな情報取得
- Pub/Subモデルの導入が容易な設計による高い規模性
2021年8月時点の実装では、リアルタイムな情報取得はms単位での情報取得・低負荷なプロトコル設計等により期待通りの強みがありますが、マルチベンダ性に課題があるというのが検証から得られた所感です。
OpenConfigの対応状況やCollectorの統一については、これからますます実装が進むと予想されるため、今後の発展に期待しています。
付録
今回の検証で用いた各機器のコンフィグ例を共有します。お手元での検証にご利用ください。 なお、これらコンフィグ例は現状有姿で提供され、NTT Comは明示的・黙示的を問わず一切の保証をせず、何ら責任を負いません。
Arista
本体側はgNMI設定か専用デーモンを立ち上げるかの2択。 EOS 4.22以降ではgNMI設定が推奨されている。
- 本体側 - gNMI設定
management api gnmi
transport grpc Telemetry
port <Port>
ip access-group <ACL名>
provider eos-native
!
- 本体側 - 専用デーモン設定
※ OpenConfigの場合はTerminAttrをOpenConfigに読みかえる。
daemon TerminAttr
exec /usr/bin/TerminAttr -disableaaa -grpcaddr <CollectorのIP addr>:<Port>
ip access-group <ACL名>
no shutdown
!
- Collector - ockafaka(Dockerでの立ち上げ例)
手順は公式リポジトリを参照。
$ docker pull aristanetworks/ockafka $ docker run aristanetworks/ockafka -addrs <Publisher Addr>:<Port> -kafkaaddrs <Kafka Addr>:<Port> -kafkatopic arista_eos_telemetry -subscribe <PATH>
- Collector - openconfigbeat(Dockerでの立ち上げ例)
手順は公式リポジトリを参照。
% git clone https://github.com/aristanetworks/openconfigbeat.git // openconfigbeat.ymlを編集 openconfigbeat: addresses: ["<Publisher Addr>"] default_port: <Port> paths: ["interfaces/interface/name"] username: "<Username>" password: "<Password>" output.kafka: hosts: ["<Kafka Addr>:<Port>"] topic: <Topic名> // openconfigbeat.ymlを/直下に配置するようDockerfileを編集 % docker build -f ./Dockerfile -t openconfigbeat:latest . --no-cache=true % docker run -d --net=host --name openconfigbeat openconfigbeat:latest
Cisco IOS-XR
- 本体側 - Dial-Out設定
telemetry model-driven destination-group <destination-group名> vrf <VRF名> address-family ipv4 <Collector Addr> port <Port> encoding <エンコーディング手法> protocol <トランスポートのプロトコル> ! ! sensor-group <sensor-group名> sensor-path <sensor-path> ! subscription <subscription名> sensor-group-id <sensor-group名> sample-interval <Interval(ms)> destination-id <destination-group名> source-interface <インターフェース名> ! !
- 本体側 - TPA(Third Party Applications)設定
IOS-XR標準のマネジメントVRF以外でTelemetryを扱う場合に必要。
vrf <VRF名> address-family ipv4 update-source dataports active-management ! ! !
- Collector - Pipeline
手順は公式リポジトリを参照。 pipeline.confを編集後、$ docker run -d --net=host [--volume <local>:/data] --name pipeline pipeline:<version>
[collector] stage = xport_input type = grpc encap = gpbkv listen = :<Port> [kafka] stage = xport_output type = kafka encoding = json_events brokers = <Kafka Addr>:<Port> topic = <Topic名> [inspector] stage = xport_output type = tap file = /data/dump.txt datachanneldepth = 1000
Juniper
- 本体側 - Dial-In設定
set system services extension-service request-response grpc clear-text address <Publisher Addr> set system services extension-service request-response grpc clear-text port <Port> set system services extension-service request-response grpc skip-authentication set system services extension-service notification allow-clients address <Collector Addr>
Junos 20.2R1以降でDial-Outにも対応しているが、対応するOSSのCollector実装が存在しないため未検証。
- Collector - Telegraf
Juniper公式のCollector実装であるjtimonも存在するが、Kafkaとの連携機能が存在しないため本検証ではTelegrafのモジュールを採用。
[[inputs.jti_openconfig_telemetry]]
servers = ["<Publisher Addr>:<Port>", "<Publisher Addr>:<Port>"] # 取得対象を複数指定可
username = "<Username>"
password = "<Password>"
client_id = "telegraf" # 取得対象の機器内(ルータ等)でユニークである必要がある
# 1つの機器に対して複数プロセスからsubscribeする場合は、
# 異なる文字列にする
sample_frequency = "2000ms"
sensors = [
"/interfaces/interface[name=vme]/state",
"/system",
"/components",
"/junos"
]
retry_delay = "1000ms"
str_as_tags = false
[[outputs.kafka]]
brokers = ["<Kafka Addr>:<Port>"]
topic = "<Topic名>"
data_format = "json"
SONiC
- 本体側 - Telemetryサービスの設定
# vi telemetry-service.yaml
apiVersion: v1
kind: Service
metadata:
name: telemetry-svc
spec:
type: NodePort
ports:
- port: <Port>
protocol: TCP
selector:
app: usonic
# kubectl apply -f telemetry-service.yaml
kubectl get svcを実行し、待ち受けポートを確認しておく。
- Collector - gNMIc 手順は公式ページ参照。
# vi gnmic.yml
targets:
<Publisher Addr>:<Port>:
subscriptions:
- port_stats
skip-verify: true
username: <Username>
password: <Password>
insecure: true
subscriptions:
port_stats:
target: COUNTERS_DB
paths:
- <Sensor-Path>
mode: stream
stream-mode: sample
sample-interval: 5s
encoding: json
outputs:
output1:
type: kafka
address: <Kafka Addr>:<Port>
topic: <Topic名>
format: json
debug: true