
目次
- 目次
- はじめに
- 論文紹介
- The Norm Must Go On: Dynamic Unsupervised Domain Adaptation by Normalization
- OcclusionFusion: Occlusion-aware Motion Estimation for Real-time Dynamic 3D Reconstruction
- EPro-PnP: Generalized End-to-End Probabilistic Perspective-N-Points for Monocular Object Pose Estimation
- Cascade Transformers for End-to-End Person Search
- TrackFormer: Multi-Object Tracking With Transformers
- Global Tracking Transformers
- TransWeather: Transformer-based Restoration of Images Degraded by Adverse Weather Conditions
- 最後に
はじめに
こんにちは、イノベーションセンターの鈴ヶ嶺・加藤・齋藤です。前編では、CVPR2022の概要とメンバーが参加したワークショップの模様をご紹介しました。後編では、CVPR2022本会議に採択された論文を7つご紹介します。

論文紹介
The Norm Must Go On: Dynamic Unsupervised Domain Adaptation by Normalization 1
実装:https://github.com/jmiemirza/DUA
この論文では、ドメイン適応への応用を目的としたBatch Normalizationの改良が提案されています。 ドメイン適応(domain adaptation)には大量のラベルありorラベル無しデータが必要です。そのため、自動運転中の天候変化など、ドメインシフトが連続的に起こる環境ではデータが十分に収集できないことがあります。 この論文ではBatch Normalizationレイヤの統計量(running mean, running variance)をいじることで少量のラベル無しデータでのドメイン適応を実現しました。これにより、連続的なドメインシフトが起こる環境でもオンラインで適応させることが可能になります。
Dynamic Unsupervised Adaptation
Batch Normalizationレイヤではミニバッチ内の平均と分散を移動平均を用いて記録し、データセット全体においてそのレイヤに入力されるデータの分布を正規化します。テスト時にはそれらの統計量は固定されますが、学習データの分布から離れた入力がくると出力分布が崩れてしまい、パフォーマンスが大きく劣化してしまいます。
そこでテスト時にもこれらの統計量(running mean, running variance)を更新することで、入力分布の変化に適応させます。 統計量はサンプルによって大きく変化しうるため、Batch Normalizationをそのまま適用するだけでは収束しにくいという問題がありました。この論文では、モーメンタムにexponential decayを適用することで、異なるドメインへの収束効率を向上させることが提案されています。 また、更新統計量を計算するときに左右反転、クロッピング、回転などのdata augmentationを施すことで性能をより良くできることが示されています。
所感
実装がシンプルで様々なタスクに利用できそうです。 一方で、ドメイン適応を自動化するためには統計量を監視しドメインシフトの発生を検出する必要がありそうです。
OcclusionFusion: Occlusion-aware Motion Estimation for Real-time Dynamic 3D Reconstruction 2
この論文では、RGB-Dカメラを入力とする、オクルージョンに強いリアルタイム3次元復元手法を提案しています。
LSTMにgraph neural networkを組み込み、今見えている場所の動きを蓄積することで見えていない部分の動きも予測するのが特徴です。ネットワークは物体表面をメッシュグラフで表現した時の各ノードの動きと予測自信度(予測分布の分散)を出力しています。
近年の3D復元はFusion-basedな手法が高い性能を誇っています。これは前景の物体を自動で追跡しながら3D復元できるため、対象物体の3Dモデルを必要とせず、また非剛体的な動き(タオルなど)も事前情報なしに予測できることが大きな要因です。
しかし単一視点の入力でオンライン処理をしようとすると、連続するフレーム間で信頼性のある対応点を取りづらく、誤差が蓄積されトラッキングに失敗することがあります。 本手法では、単一視点の困難の1つである「見えない部分のモーション予測」を、これまでの動きや物体形状による制約を活用することで高精度化し、オフライン手法をも超える予測精度を達成しました。 実行速度はNVIDIAのGeForce RTX 2080Ti x2, 解像度480pで36ミリ秒だとしています。
Network architecture
入力画像から2D optical flowを計算し、深度情報と併せて3D optical flowとします。これと対象物体のノードグラフを入力することで、各ノードに3D座標と(カメラから見えているなら)3Dモーションベクトルが特徴量として与えられます。この時あらかじめ物体全体の剛体運動(回転+平行移動の)を計算しておくことで、ネットワークは相対的な非剛体運動のみを推定させています。
そして各ノードにLSTMを導入してステートを持たせることで、これまでの動き情報も推論に活用できるようになっています。
学習時は予測値と予測分散に対してガウス分布のlog-likelihood lossを与えてネットワークを学習しています。
Confidence guided non-rigid reconstruction
前処理で使ったoptical flowやgraph neural networkの出力した予測モーションと確信度を使い、次のコスト関数の重み付き和を最小化するような各頂点のモーションを求めます。
- 深度制約:測定した深度と予測位置に一貫性を持たせる。前フレームの予測頂点と2D optical flowからその頂点の今フレームにおけるカメラ座標を計算し、その位置の深度情報をもとに3D空間に逆投影する。深度マップのサブピクセル分だけずれが生じるので、ピクセルをポリゴンとして3D空間に逆投影し、ポリゴンと予測頂点位置との距離をコストとする。
- モーション制約:最終的な予測モーションとGraph neural networkの予測モーションとの一貫性を保つ。予測自信度で重み付けされたモーションベクトルとのユークリッド誤差をコストとする。
- 2D制約:最終的な予測モーションと2D optical flowとの一貫性を保つ。物体の各頂点をカメラ座標に投影したときの2次元モーションと2D optical flowとのユークリッド誤差をとる。
- 剛体制約:物体の硬さを制約にする。隣接する頂点同士に対してお互いの予測モーションベクトルのユークリッド誤差をとる。
これで最適化したのちにモデルの最終的な形状を決定します。新しい頂点をトラッキングに追加する方法はDynamicFusion3を利用しています。
EPro-PnP: Generalized End-to-End Probabilistic Perspective-N-Points for Monocular Object Pose Estimation 4
PnP問題のエンドツーエンド確率推論を実現する手法であるEPro-PnPが提案されています。
エンドツーエンドの確率的PnP
以下が全体のアーキテクチャです。注目するポイントは 学習時にEPro-PNPで事後位置姿勢分布 を導出している点です。最終的には、特殊ユークリッド群SE(3)多様体上の位置姿勢の分布を連続空間に対応可能なSoftmaxを用いて出力します。推論時にはソルバーを用いて位置姿勢
を推定しています。

PnP問題の最終的な目的は の2D, 3DのN点の対応点を求めることです。それを定式化すると式(1)のように最小化する関数が導けます。
は回転ベクトル、
は並進ベクトル、
はカメラの内部キャリブレーションのパラメーターを含めた射影関数、
は要素積を示しています。
また、
は3Dから2Dに再射影した誤差を表しています。

式(1)は非線型最小問題のため一意な解でない可能性があり扱いづらいので、エンドツーエンド学習のために微分可能な確率密度を出力するPnPをモデル化しています。累積誤差は次のように定義される尤度関数の負の対数として考えています。

事前位置姿勢分布 を用いてベイズの定理より事後位置姿勢分布
は次のように導出されます。

式(3)は連続空間に対応可能なSoftmaxとして解釈可能です。
学習時には次の式ように教師位置姿勢分布 と
のKLダイバージェンスを最小化することで学習します。

式(2)を代入すると以下のような簡略化した損失関数が定義できます。

の積分についてはGPUで計算しやすいK点のサンプルから計算するAMIS(Adaptive Multiple Importance Sampling)5という効率的なモンテカルロ手法を利用します。

不確実性と識別のバランス
損失関数に対する重み の勾配は次の式(8)ように導出されます。ここで非加重再投影誤差を
として扱います。
最初の項の は負の符号であり再射影誤差が大きく、つまり不確かさが大きい対応点ほど重みづけをしないことを示しています。
次の項の は予測された姿勢に対する再射影の分散を示しています。また正の符号であるため感度の高い対応点にはより強く位置姿勢判別ができるためより重みづけをする必要があることを示しています。

最終的な勾配は図3のようなものとなります。このように学習された対応点の重みは、逆不確実性と識別性に分解できます。既存の研究では前者のみを考慮するため識別性能が不足していました。

実験結果
表4ではnuScenes Benchmark6を用いた結果を示しています。ここでは3つのEPro-PnPを評価しています。
EPro-PnPはベースラインのFCOS3Dを大きく上回っています(nuScenes Detection Score (NDS) 0.425 vs 0.372)。この結果から大規模なデータセットに適切なエンドツーエンドのパイプラインを設定することで直接の位置姿勢推定を上回る結果となることを示唆しています。また、ポーズ推定精度を反映するmAOEについても基本的に他の手法よりもEPro-PnPが上回っています(mAOE 0.337 vs. 0.36)。TTAを用いた結果ではthe state of the artを上回る結果を示しています(NDS 0.439 vs. 0.422)。

定性的な結果として図7で既存手法のCDPN9と学習した重みを比べると提案手法はあまりエッジ部分の詳細をキャプチャできていないです。また、提案手法の座標マップはCDPN 79.46 よりも 79.96 となっているため性能が良いことが分かります。

実際に動作させた結果
以下に実際に動作させた例を記載します。
以下で公開されているpretrain modelの中から今回は epropnp_det_v1b_220411.pth を利用しました。
https://drive.google.com/drive/folders/1AWRg09fkt66I8rgrp33Lwb9l6-D6Gjrg
export PATH=/usr/local/cuda-11.3/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-11.3/lib64:$LD_LIBRARY_PATH conda create -y -n epropnp_det python=3.7 conda activate epropnp_det conda install -y pip pip install torch==1.10.1+cu113 torchvision==0.11.2+cu113 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html pip install mmcv-full==1.4.1 -f https://download.openmmlab.com/mmcv/dist/cu113/torch1.10.0/index.html conda install -y -c fvcore -c iopath -c conda-forge -c bottler fvcore iopath nvidiacub git clone https://github.com/facebookresearch/pytorch3d cd pytorch3d && git checkout v0.6.1 && pip install -v -e . && cd .. git clone https://github.com/tjiiv-cprg/EPro-PnP.git cd EPro-PnP/EPro-PnP-Det pip install -v -e . # sample image inference python demo/infer_imgs.py demo/ configs/epropnp_det_v1b_220411.py epropnp_det_v1b_220411.pth --show-views 3d bev mc # my image inference cp -r demo mydemo # setup my image(file path: mydemo/demo.png) vim mydemo/nus_cam_front.csv # edit camera intrinsic matrix python mydemo/infer_imgs.py mydemo/ configs/epropnp_det_v1b_220411.py epropnp_det_v1b_220411.pth --intrinsic mydemo/nus_cam_front.csv --show-views 3d bev mc
次の結果は、MIT DriveSegのデータセット10の画像を推論した結果になります。 右奥の車両の検出はされていませんが、確率的に存在する可能性の高さを2Dのマップ画像から確認できます。また、奥のいる人などの位置関係はおおむね適切にマッピングされていることが分かります。

所感
微分が難しいPnP問題に対して確率的なレイヤーを加えて柔軟性を持たせることでエンドツーエンド学習が可能となる点が興味深かったです。また、この仕組みは既存のPnP推定ネットワークにも広く応用できるので応用力も期待できると感じました。
Cascade Transformers for End-to-End Person Search 11
画像データベース(gallery set)からクエリ画像に映る特定の人物を検索するperson searchタスクに対し、 この論文ではCascade Occluded Attention Transformer (COAT) を提案し、E2Eな人物検索を実現します。
実装:https://github.com/Kitware/COAT
Person search
人物検索タスクに対する一般的なアプローチは、大きく(1)人物検出、(2)特徴量抽出、(3)特徴量の比較に基づくgallery画像のランキング生成から構成されます。(2)と(3)は、所謂 person re-identification(ReID)と同一です。
このperson searchタスクでは次のような困難が挙げられます。
- 人物検出とReIDそれぞれで必要とする特徴量の性質が異なる
- 人物検出ではどんな見た目の人間でも検出できるような汎用性のある特徴量を学習する必要があるのに対し、ReIDでは個人ごとに分別可能な特徴量を必要とするため、単一の特徴量抽出器で両方をこなすのは難しい。
- E2Eモデルでは検出用とReID用のどちらを先に特徴抽出するかでモデルの構造が変わる。
- ReID first: 多様性のある特徴量マップを計算したのち、人間にあたる特徴を検出する
- detection first: 人間を検出するネットワークでRoI(region of interest)を列挙し、それぞれのbounding boxからReID用特徴を計算する
- 多様なサンプルに対応する必要がある
- scale variations. 写っている人物のサイズが極端に異なる
- pose/viewpoint change. 写っている人物の向きや姿勢が異なる
- occlusion. 体が別の人や障害物に隠れている
人物検出器
本研究では物体検出器としてCascade R-CNN 12を適用しています。小さなIoU閾値で学習させる弱い検出器から得たbounding boxを、より厳しいIoU閾値で学習させる検出器のproposalに使い、さらにそこから得たbounding boxをもっと強い検出器のproposalに...という流れでbounding boxを段階的に洗練させるのが特徴です。
これはfaster R-CNNにおけるRegion proposal network (RPN) を複数段に拡張したものといえます。
Cascade Occluded Attention Transformer
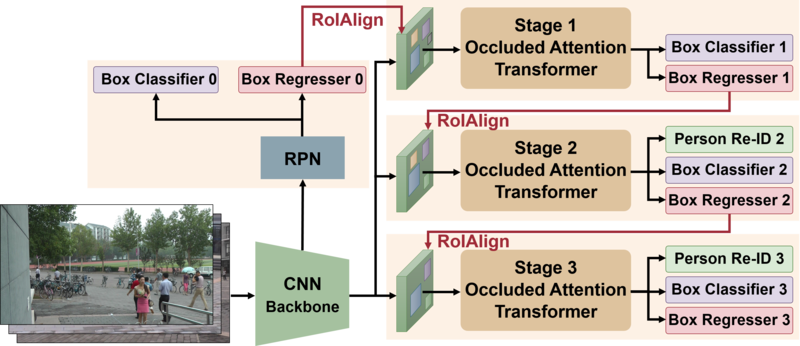 本手法の提案アーキテクチャです。オクルージョンに強い特徴量が得られるOccluded Attention Transformerを多段に繋ぎ、前ステージで推測したbounding boxを次のステージのproposalに使い、そこから推測したbounding boxをさらに次のステージのproposalに...という流れで段階的に人物検出とReID特徴を洗練させます。
本手法の提案アーキテクチャです。オクルージョンに強い特徴量が得られるOccluded Attention Transformerを多段に繋ぎ、前ステージで推測したbounding boxを次のステージのproposalに使い、そこから推測したbounding boxをさらに次のステージのproposalに...という流れで段階的に人物検出とReID特徴を洗練させます。
本手法ではTransformerへの入力前に以下のような工夫を施しています。
- マルチスケール特徴を入力とする。各proposalの特徴マップをチャンネル方向にいくつか分割したのち、convolution layerで特定のスケールに縮小する。そうして得られたマルチスケール特徴をtokenとしてtransformerの入力に使う。
- Data augmentationでオクルージョンをシミュレートする。具体的にはCutMix13の要領で一部のtokenをバッチ間でシャッフルする(切り出す座標と貼り付ける座標は同一)。これにより、各サンプルが一部別の物体によって隠れることを再現できる。学習時のみ有効。
評価
CUHK-SYSU14, PRW15 datasetで評価し、sotaまたはそれに近い性能を達成しました。また、cascadeの各ステージで人物検出の正解判定に用いるIoU閾値は段階的に増やすことで性能が良くなること、また本手法のoccluded attention transformerは、他のattention機構やcutout/mixup等のdata augmentationを使うよりも高い性能を出すことが示されています。
推論速度はNVIDIA A100 GPU, Pytorch実装, 入力サイズ900x1500で11.14FPSでした。
TrackFormer: Multi-Object Tracking With Transformers 16
この論文では、Tracking-by-attentionという新しいトラッキングパラダイムに基づく、エンドツーエンド学習可能なMOT手法を提案しています。
Tracking-by-attention
MOTでは、Tracking-by-detectionと呼ばれる物体検出と検出結果のフレーム間対応付けをカスケードに行う手法が一般的です。それに対して、この提案法ではフレーム特徴と物体・追跡クエリに対するAttentionを基にフレーム間の関連付けを行い物体追跡を実現するTracking-by-attentionを提案しています。物体クエリはバウンディングボックスなどの物体検出に利用される埋め込みベクトルであり、追跡クエリは自己回帰的に移動する位置に対応しフレーム間のオブジェクトを追跡しそのIDを引き継ぐ埋め込みベクトルです。また物体・追跡クエリは連結して利用されるため、この提案法は検出と追跡を同時に出力できます。
MOTを集合予測問題として定式化
提案するモデルは図2のように、以下の連続したステップでフレームごとの物体のバウンディングボックスとIDに関するクラスを予測する集合予測問題として定式化しています。
- Res-Net-5017などの一般的なCNN backboneを用いて
時点の入力からフレーム特徴を抽出する
- Transformerエンコーダ18のself-attentionでフレーム特徴をエンコードする
- Transformerデコーダで
時点の物体・追跡クエリ用いてMLPでバウンディングボックスとクラス予測にマッピングする

実験結果

表1では、MOT17 19 のデータセットを用いて評価した結果で優れた精度を示していることが分かります。

図3は、MOTS2020データセットを用いてR-CNNと比較した結果です。提案法のセグメンテーションの性能が優れていることが分かります。
実際に動作させた結果
以下に実際に動作させた例を記載します。
conda create --name trackformer python=3.7 cmake -y conda activate trackformer conda install pytorch==1.5.0 torchvision==0.6.0 -c pytorch git clone https://github.com/timmeinhardt/trackformer.git cd trackformer pip install -r requirements.txt pip install -U 'git+https://github.com/timmeinhardt/cocoapi.git#subdirectory=PythonAPI' python src/trackformer/models/ops/setup.py build --build-base=src/trackformer/models/ops/ install cd models wget https://vision.in.tum.de/webshare/u/meinhard/trackformer_models_v1.zip unzip trackformer_models_v1.zip cd ../ # sample video inference ffmpeg -i data/snakeboard/snakeboard.mp4 -vf fps=30 data/snakeboard/%06d.png python src/track.py with dataset_name=DEMO data_root_dir=data/snakeboard output_dir=data/snakeboard write_images=pretty # my video inference # setup my video(file path: data/myvideo/myvideo.mp4) ffmpeg -i data/myvideo/myvideo.mp4 -vf fps=30 data/myvideo/%06d.png python src/track.py with dataset_name=DEMO data_root_dir=data/myvideo output_dir=data/myvideo write_images=pretty
次の結果は、DanceTrack 21 の映像に本手法を適用した結果になります。

所感
Tracking-by-attentionによりエンドツーエンドでトラッキングを可能としている点が興味深く、今後のこのような手法に期待させられるような内容でした。
Global Tracking Transformers22
Transformerベースのマルチオブジェクトトラッキング手法を提案している論文です。
Local tracker と Global tracker

主に従来のトラッキング手法ではフレームごとに物体を関連づけるLocal trackersという手法が用いられていました。この提案手法では、短い動画クリップを入力として全てのフレームを通して物体を関連づけるGlobal trackerが用いられています。
Global tracking transformers(GTR)

この提案法は上記のように最初に、全フレームから独立して物体を検出しGlobal tracking transformers(GTR)のエンコーダーに入力されます。またGTRは軌跡クエリをデコーダーの入力として各クエリと物体の関連性スコアを出力し関連づけます。
評価結果

表1にGTRの異なる時間窓の性能をTAO23、MOT17のデータセットを用いて評価しています。基本的な傾向としてより長い時間窓では性能が向上しています。

表3の結果はMOT17のテストデータを用いた結果です。この結果からGTRはトップクラスの性能を達成していることが分かります。
実際に動作させた結果
以下に実際に動作させた例を記載します。
conda create --name gtr python=3.8 -y conda activate gtr conda install pytorch torchvision torchaudio cudatoolkit=11.1 -c pytorch-lts -c nvidia pip install "git+https://github.com/facebookresearch/detectron2.git" git clone https://github.com/xingyizhou/GTR.git --recursive cd GTR pip install -r requirements.txt # setup pretrain model(file path: models/GTR_TAO_DR2101.pth) # https://drive.google.com/file/d/1TqkLpFZvOMY5HTTaAWz25RxtLHdzQ-CD/view?usp=sharing # sample video inference python demo.py --config-file configs/GTR_TAO_DR2101.yaml --video-input docs/yfcc_v_acef1cb6d38c2beab6e69e266e234f.mp4 --output output/demo_yfcc.mp4 --opts MODEL.WEIGHTS models/GTR_TAO_DR2101.pth # my video inference # setup my video(file path: myvideo.mp4) python demo.py --config-file configs/GTR_TAO_DR2101.yaml --video-input myvideo.mp4 --output output/demo_myvideo.mp4 --opts MODEL.WEIGHTS models/GTR_TAO_DR2101.pth
次の結果は、DanceTrackの映像に本手法を適用した結果になります。
非常にオクルージョンが多いデータとなっており、IDの切り替わりなどが多少見受けられる結果になりました。

所感
フレームごとにトラッキングするのではなく、グローバルにトラッキングするという方針が興味深かったです。また、現状GPUメモリの制約があるため実装上では時間窓を32に設定するのが限界のようですが、今後のGPU性能がスケールした際の性能向上に期待が持てると思いました。
TransWeather: Transformer-based Restoration of Images Degraded by Adverse Weather Conditions24
TransWeatherとは
カメラに映り込む悪天候時の雨粒、霧、雪片を除去するために特定のネットワークの構築や複数のEncoder-Decoderのネットワークを構築していましたが、パラメータ数が大きくなる問題がありました。そこで、TransWeatherでは、単一のEncoder-Decoderのネットワークで雨、霧、雪の除去できるネットワークを構築し、特定の状況に特化したモデルと同程度もしくは良い結果を出しています。
ネットワークの説明
ネットワークの構成は、単一のEncoder-Decoderネットワークであり、シンプルな構成となっています。TransWeatherのEncoderは、主に3つの構成要素があります。 図1の左から見ていくと、Intra Patch Transformerは、雨、霧、雪などの細かいものをとらえるために、Patchを縦横半分のサイズでconcatして入力画像として渡しています。Transformer blockでは、計算量を抑えるためにダウンサンプリングの工夫を凝らしているPyramid Vision Transformerを採用しています。TransformerのFFNの層では、Pyramid Vision TransformerのDWConvとMLPの層を設けている構成となっています。 Decoder部分では、通常のViTではdecoderの入力(Q,K,V)は、encoderの最終層から出力された特徴量を使いますが、TransWeatherはクエリ(Q)に天候を入力し、KとVについてencoderの最終層から出力された特徴量を入力としています。クエリ(Q)に天候を入力している部分の実装 を追ってみると、ランダムな1×48のTensorを設定しています。体感としてはここは雨、雪、霧の状態を表すTensorを想定していたので、クエリがこのTensorで妥当なのか、私は実装からは読み取ることができませんでした。
self.task_query = nn.Parameter(torch.randn(1,48,dim))
TransfromerのEncoderとDecoderから出力された特徴量を、MSBDN25のDecoderに渡し、Dehazeの処理をします。それにより、クリーンな画像が出力されます。
 Figure2. TransWeatherのネットワークアーキテクチャ図
Figure2. TransWeatherのネットワークアーキテクチャ図
実験結果
学習のデータセットはAll in One26で使用された学習のデータセットと同じものを使っています。Snow100K27の9,000画像、Raindrop28の1,069画像、Outdoor-Rain29の9,000画像を利用しています。 テスト画像には、Test1、RainDrop、Snow100k-Lを使用しています。
 Table1. 既存のモデルとの比較
Table1. 既存のモデルとの比較
評価指標 - PSNR 2枚の画像で同じ位置同士のピクセルの輝度の差分の2乗を計算した指標です。 - SSIM 輝度、コントラスト、構造を軸にして周囲のピクセル平均、分散、共分散をとることで、ピクセル単体のみならず、周囲のピクセルとの相関を取り込んだ指標となっています。
この評価指標においてTransWeatherは、PSNR、SSIMどちらにおいても既存のモデルを上回っているということを述べています。 パラメータ数も減少しており、Transweatherはパラメータ数が31Mであり、All in One Networkのパラメータ数44Mと比較するとより少なくなっています。
 Figure4. モデルごとのDehazeした結果比較
Figure4. モデルごとのDehazeした結果比較
動作結果
コードを動作させるためにはutil.pyが必要なのですが、github上に実装がなかったためSyn2Realのutil.pyを引用しました。学習済みモデルは見つけることができませんでした。 そのため、配布されている学習セットを使用して手元で学習させました。
# このままcloneしただけでは動かない git clone https://github.com/jeya-maria-jose/TransWeather.git cd TransWeather # NVIDIA RTX3090を用いたのでcudaバージョンはcuda11.0を使用 # torch 1.8.0以上だとsixがないため動かないので、今回はtorch1.7.1をインストール conda env create -f environment.yml conda activate transweather pip install torch1.11.0+cu113 torchvision0.12.0+cu113 torchaudio0.11.0 --extra-index-url https://download.pytorch.org/whl/cu113 pip install mmcv-full1.5.3 -f https://download.openmmlab.com/mmcv/dist/cu111/torch1.10.0/index.html # epoch数はデフォルトの250だったためそのまま採用 python train.py -train_batch_size 32 -exp_name Transweather -epoch_start 0 -num_epochs 250 python test_test1.py -exp_name TransWeather
論文では、Test1、RainDrop、Snow100k-Lを利用していると述べていました。そこに加えcityscapes dataset(leftimg8bit_trainval_rain)とドメインが全く異なるiPoneで撮影した画像を使用してテストを行いました。snow100k、test1、RainDropでテスト画像を何枚使用しているかは不明であったため、論文のテストセットとは同一ではないと思われます。
 Table2. 論文での実験結果
Table2. 論文での実験結果
 Table3. 手元のテスト結果
Table3. 手元のテスト結果
表1と表2を比較すると、psnrとssimの評価指標が論文中の実験と比較し、下回っているように思えます。 次に、1024×576のiPhoneで撮影した画像に対して定性的な評価をしていきます。入力画像を上に、dehazeが行われた後画像の出力画像を下に載せます。赤枠で囲んだ部分を見ると、小さな雪片がうまく消せていることから、学習がうまくいき、Dehazeができていることがわかります。ただ、大きな雪片については、Dehazeが一部できていないように見えます。

雨天の入力をした場合においても、赤枠の部分を注目すると両方の画像において、入力画像にたいして出力画像が雨粒を一部消せていることがわかります。

所感
TransWeatherは単一のEncoder-Decoderネットワークを使用していることからAll in Oneの手法で明確な違いがあることやIntra-patchの導入をしました。それが、既存のモデルを評価指標の面に置いて良い結果につながっていること示しています。公開コードの学習推論を一通り実行することはできたものの、テストセットの詳細が不明なため論文に示されてる結果の再現実験は困難な印象を持ちました。また、これは本手法に限りませんが、dehazeなどの処理が悪天候時の映像を入力とした物体認識にどの程度効果があるのかについても調査してみたいと考えています。
最後に
本ブログでは、CVPR2022への参加者が興味を持った論文をご紹介しました。 NTT Comでは、今回ご紹介した論文調査、画像や映像、更には音声言語も含めた様々なメディアAI技術の研究開発に今後も積極的に取り組んでいきます。
- アカデミックな研究に注力したくさん論文を書きたい
- 最新の技術をいちはやく取り入れ実用化に結び付けたい
- AIアルゴリズムに加え、AI/MLシステム全体の最適な設計を模索したい
という方々に活躍していただけるフィールドがNTT Comには多くあります。今後も私たちの取り組みをブログ等で発信していきますので、興味を持ってくださった方は是非今後もご注目ください!
-
M. Jehanzeb Mirza, Jakub Micorek, Horst Possegger, Horst Bischof. The Norm Must Go On: Dynamic Unsupervised Domain Adaptation by Normalization, In CVPR, 2022.↩
-
Wenbin Lin, Chengwei Zheng, Jun-Hai Yong, Feng Xu. OcclusionFusion: Occlusion-aware Motion Estimation for Real-time Dynamic 3D Reconstruction. In CVPR, 2022.↩
-
Richard A. Newcombe, Dieter Fox, Steven M. Seitz. DynamicFusion: Reconstruction and Tracking of Non-rigid Scenes in Real-Time. In CVPR, 2015.↩
-
Chen, Hansheng et al. “EPro-PnP: Generalized End-to-End Probabilistic Perspective-N-Points for Monocular Object Pose Estimation.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022.↩
-
Jean-Marie Cornuet, Jean-Michel Marin, Antonietta Mira, and Christian P. Robert. Adaptive multiple importance sampling. Scandinavian Journal of Statistics, 39(4):798–812, 2012. 3↩
-
Holger Caesar, Varun Bankiti, Alex H. Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In CVPR, 2020. 1, 5, 6↩
-
Hansheng Chen, Yuyao Huang, Wei Tian, Zhong Gao, and Lu Xiong. Monorun: Monocular 3d object detection by reconstruction and uncertainty propagation. In CVPR, 2021. 2, 3, 4, 5, 6, 7, 8↩
-
Tai Wang, Xinge Zhu, Jiangmiao Pang, and Dahua Lin. FCOS3D: Fully convolutional one-stage monocular 3d object detection. In ICCV Workshops, 2021. 5, 6, 7, 8↩
-
Zhigang Li, Gu Wang, and Xiangyang Ji. Cdpn: Coordinates-based disentangled pose network for real-time rgb-based 6-dof object pose estimation. In ICCV, 2019. 1, 2, 5, 6, 7, 8↩
-
Ding, Li et al. “MIT DriveSeg (Manual) Dataset for Dynamic Driving Scene Segmentation.” (2020).↩
-
Rui Yu, Dawei Du, Rodney LaLonde, Daniel Davila, Christopher Funk, Anthony Hoogs, Brian Clipp. Cascade Transformers for End-to-End Person Search. In CVPR, 2022.↩
-
Zhaowei Cai, Nuno Vasconcelos. Cascade R-CNN: delving into high quality object detection. In CVPR, 2018.↩
-
Sangdoo Yun, Dongyoon Han, Seong Joon Oh, Sanghyuk Chun, Junsuk Choe, Youngjoon Yoo. CutMix: Regularization Strategy to Train Strong Classifiers With Localizable Features. In ICCV, 2019.↩
-
Tong Xiao, Shuang Li, Bochao Wang, Liang Lin, Xiaogang Wang. Joint detection and identification feature learning for person search. In CVPR, 2017.↩
-
Liang Zheng, Hengheng Zhang, Shaoyan Sun, Manmohan Chandraker, Yi Yang, Qi Tian. Person re-identification in the wild. In CVPR, 2017.↩
-
Meinhardt, Tim et al. “TrackFormer: Multi-Object Tracking With Transformers.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022.↩
-
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In IEEE Conf. Comput. Vis. Pattern Recog., 2016. 2, 3, 6↩
-
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Adv. Neural Inform. Process. Syst., 2017. 1, 2, 3, 4, 9↩
-
A. Milan, L. Leal-Taixe, I. Reid, S. Roth, and K. ´ Schindler. MOT16: A benchmark for multi-object tracking. arXiv:1603.00831, 2016. 2, 3, 5, 6↩
-
Paul Voigtlaender, Michael Krause, Aljosa Osep, Jonathon Luiten, Berin Balachandar Gnana Sekar, Andreas Geiger, and Bastian Leibe. Mots: Multi-object tracking and segmentation. In IEEE Conf. Comput. Vis. Pattern Recog., 2019. 2, 6, 7, 8↩
-
Sun, Peize et al. “DanceTrack: Multi-Object Tracking in Uniform Appearance and Diverse Motion.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022.↩
-
Zhou, Xingyi et al. “Global Tracking Transformers.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2022.↩
-
Achal Dave, Tarasha Khurana, Pavel Tokmakov, Cordelia Schmid, and Deva Ramanan. Tao: A large-scale benchmark for tracking any object. In ECCV, 2020. 3, 4, 5, 6, 7↩
-
Jeya Maria Jose Valanarasu, Rajeev Yasarla, Vishal M. Patel.TransWeather: Transformer-based Restoration of Images Degraded by Adverse Weather Conditions. In CVRP2022↩
-
Hang Dong, Jinshan Pan, Lei Xiang, Zhe Hu, Xinyi Zhang, Fei Wang, and Ming-Hsuan Yang. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2157–2167, 2020↩
-
Ruoteng Li, Robby T. Tan, Loong-Fah Cheong1.All in One Bad Weather Removal using Architectural Search. In CVRP2020↩
-
Yun-Fu Liu, Da-Wei Jaw, Shih-Chia Huang, and Jenq-Neng Hwang. Desnownet: Context-aware deep network for snow removal. CoRR, abs/1708.04512, 2017.↩
-
Rui Qian, Robby T Tan, Wenhan Yang, Jiajun Su, and Jiaying Liu. Attentive generative adversarial network for raindrop removal from a single image. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 2482–2491, 2018.↩
-
Ruoteng Li, Loong-Fah Cheong, and Robby T Tan. Heavy rain image restoration: Integrating physics model and conditional adversarial learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1633–1642, 2019↩