
はじめに
こんにちは、イノベーションセンターの鈴ヶ嶺です。普段はクラウドサービスをオンプレ環境でも同様のUI/UXで使用を可能とするハイブリッドクラウド製品の技術検証をしています。
NTT Comでは以下の過去の記事のように、AWSのハイブリッドクラウドソリューションAWS Outposts ラックの導入や技術検証を進めています。
本記事では、AWS Outpostsで実現するオンプレ環境におけるデータレイクのユースケースについて紹介します。 データレイクとは構造化データ、非構造化データに関わらず全てのデータを一元的に保存可能なストレージを意味しています。 このユースケースにより、低遅延性が求められる、もしくは秘匿性の高い大規模なデータをオンプレ環境で一元的に取り扱うことが可能となります。
オンプレ環境におけるデータレイクの背景と課題
膨大なユーザデータやIoTセンサーデータなどのビックデータを企業が適切に管理と分析を行う事が期待されています。そこから、社会の中で企業は更にサービスの質を向上させていくことが求められていることにより、データレイクの重要性は年々増しています。 データレイクを利用する中で、特に高速にデータ処理するために低遅延性が求められるケース、秘密情報を取り扱うためにセキュリティ保護上データの所在をコントロールしたいケースなどではオンプレ環境に構築する必要があります。 次にオンプレ環境にデータレイクを構築する場合の課題を3つ挙げます。
- ストレージ・データ分析基盤の構築
- オンプレ環境に大規模なデータを安価に格納可能なストレージや、それらのデータを処理するための並列分散処理基盤の構築が必要となります。これらはデータや分析需要の増加に対応するため、スケーラブルな設計を考慮している事が求められます。
- 保守運用コスト
- それぞれのストレージ・並列分散処理基盤のハードウェア管理やソフトウェアのversion管理などの保守運用も多くの稼働が必要となります。故障対応なども製品ごとにエスカレーション先が異なる場合に製品同士の依存関係を把握して対応する稼働コストも製品数に比例して増大すると考えられます。
- オンプレ環境のセキュリティ
- 構築したオンプレサービス群に対して適切なアカウント管理やリソースのアクセス制限などのセキュリティ対策が必要です。オンプレ環境では、特に不十分な例として認証方式の不統一や共通されたパスワード運用による脆弱性が問題視されています。
AWS Outpostsで実現するオンプレデータレイク
先ほど述べた3つのストレージ・データ分析基盤の構築、保守運用コスト、オンプレ環境のセキュリティの課題を解決するためにAWSのハイブリッドクラウドであるAWS Outpostsを用いたオンプレデータレイクシステムを提案します。
- S3 on Outposts、Auto Scaling Groupを活用したスケールするストレージ・データ分析基盤の構築
- AWS Outpostsには事前にデータサイズを決定せずに大規模データを貯蔵可能なS3 on Outpostsというオブジェクトストレージサービスがあります。また、オンプレ環境でAuto Scaling Groupを利用することで柔軟にスケールする並列分散基盤を作成可能です。これにより先の述べたストレージ・データ分析基盤の構築の課題を解決できます。
- AWSによる保守運用の一括管理
- AWS Outpostsはフルマネージド型インフラストラクチャであり、ハードウェアの故障対応なども含めて全て一括でAWSが管理することで高い稼働コストを削減できます。
- AWS IAMによるセキュリティ対策
- AWS Outpostsの上で動作するリソースは全てAWS IAMというきめ細かなアクセス制御を担うサービスで管理できるので最小限のアクセス権限やアカウントの二段階認証導入による対策により高いセキュリティを担保可能です。
アーキテクチャ
ここからAWS Outpostsで実現するオンプレデータレイクのアーキテクチャとそれぞれのシステム詳細について紹介します。
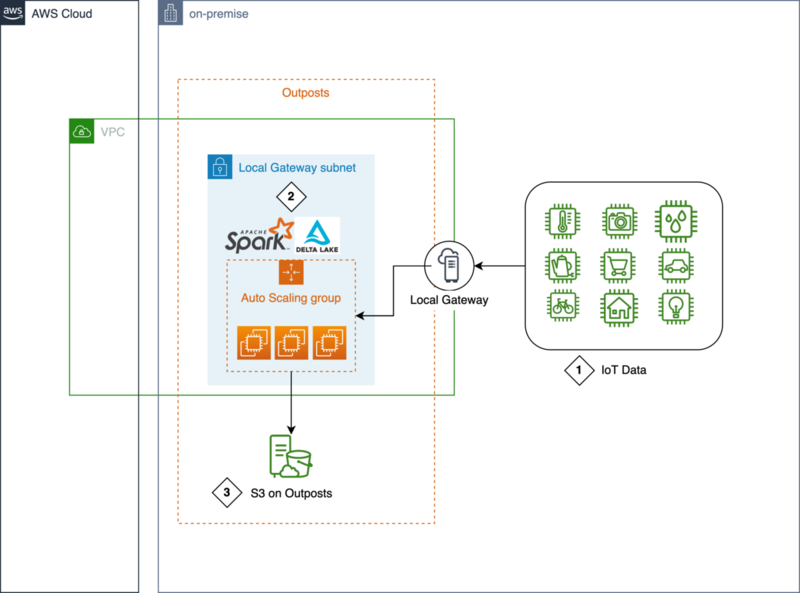
1. オンプレ環境の多数のIoTセンサーデータ
オンプレ環境の多数のIoTセンサーデータをAWS Outpostsに送信します。AWS OutpostsはLocal Gatewayを用いることでオンプレ環境と通信できます。これによりセキュリティ要件上オンプレ環境からのみ取得可能なデータにアクセスすることを可能とし、定められた時間内に処理することが求められるデータを低遅延に蓄積・処理が可能となります。
2. Spark・Delta Lakeによるデータ更新
データレイクにはDelta Lakeというデータレイクの信頼性、セキュリティ、性能を高め、ストリーミング/バッチ処理の両方を柔軟に対応するオープンソースのストレージレイヤーを利用します。このストレージレイヤーをAuto Scaling Groupを用いて並列に構築されたSparkで実行します。これによりスケーラビリティを担保して大規模なデータを蓄積・処理が可能となります。
3. S3 on Outpostsによるセキュアなビックデータ管理
S3 on Outpostsは事前にデータサイズを決定する必要がない、柔軟に大規模なデータをオンプレ環境に貯蔵可能なオブジェクトストレージサービスです。Delta Lakeで処理されたデータはこのS3 on Outpostsに貯蔵されます。2022年8月時点でS3 on Outpostsに貯蔵可能なデータ量の最大は380TBです。 また、S3 on Outpostsはインターネットなどの外部からデータにアクセス不可能で、AWS Outpostsやオンプレ環境からのみアクセス可能です。さらにAWS IAMを用いることで最小限のデータアクセス制御を実装可能です。 これらのことからS3 on Outpostsによって、オンプレ環境でセキュアなビックデータの管理を実現可能です。
データレイクの性能検証
ここでは、データレイクの性能を検証します。 データセットとしてUCI Machine Learning RepositoryのKASANDR Data Setを利用します。これはヨーロッパのeコマース広告のKelkoo社の顧客の行動を記録したデータです。今回は学習データのtrain_de.csv(3.14GB)を使用します。
以下に実際のデータ例を抜粋しました。時刻データやカテゴリデータが含まれるデータとなっています。
| userid | offerid | countrycode | category | merchant | utcdate | rating |
|---|---|---|---|---|---|---|
| fa937b779184527f12e2d71c711e6411236d1ab59f8597d7494af26d194f0979 | c5f63750c2b5b0166e55511ee878b7a3 | de | 100020213 | f3c93baa0cf4430849611cedb3a40ec4094d1d370be8417181da5d13ac99ef3d | 2016-06-14 17:28:47.0 | 0 |
| f6c8958b9bc2d6033ff4c1cc0a03e9ab96df4bcc528913be886254d1ad8c7c44 | 19754ec121b3a99fff3967646942de67 | de | 100020213 | 21a509189fb0875c3732590121ff3fc86da770b0628c1812e82f023ee2e0f683 | 2016-06-14 17:28:48.0 | 0 |
| 02fe7ccf1de19a387afc8a11d08852ffd2b4dabaed4e2d2af9130e9c5dfb9ee8 | 5ac4398e4d8ad4167a57b43e9c724b18 | de | 125801 | b042951fdb45ddef8ba6075ced0e5885bc2fa4c4470bf790432e606d85032017 | 2016-06-14 17:28:50.0 | 0 |
| 9de5c06d0a16256b13b8e7cdc50bf203ecef533eb5cbe18d514947b1c5296f33 | be83df9772ec47fd210b28091138ff11 | de | 125801 | 4740b6c83b6e12e423297493f234323ffd1c991f3d4496a71daebbef01d6dcf0 | 2016-06-14 17:29:19.0 | 0 |
データサイズの比較
次のように、データセットをDelta Lake形式でS3 on Outpostsに保存します。 実際の処理はspark-shell 3.3.0を用いました。 2022年8月時点では、以下のようにAmazon EMR on OutpostsではS3 on Outpostsをサポートしていないため、S3 on Outpostsへのデータ保存に対応するため、Hadoop-AWSに対して改善パッチを当てたものを使用しました。 また、Hadoopに改善パッチ取り込みを要求中です。
S3 is the only supported option for Amazon EMR on Outposts. S3 on Outposts is not supported for Amazon EMR on AWS Outposts. https://docs.aws.amazon.com/emr/latest/ManagementGuide/emr-plan-outposts.html
以下がS3 on OutpostsにDelta Lake形式でデータを保存するスクリプトです。
sc.hadoopConfiguration.set("fs.s3a.bucket.delta-bucket.accesspoint.arn", "arn:aws:s3-outposts:ap-northeast-1:123456789:outpost/op-123456789/accesspoint/delta-lake") val base_path = "s3a://delta-bucket/delta" val df = spark.read.format("csv").option("header", "true").option("inferSchema", "true").option("delimiter", "\t").load("train_de.csv") df.write.format("delta").mode("overwrite").save(base_path)
データの実態は次のようにApache Parquetとして保存されます。
> aws s3 ls s3://arn:aws:s3-outposts:ap-northeast-1:123456789:outpost/op-123456789/accesspoint/delta-lake --summarize --recursive 2022-07-14 09:36:17 21697 delta/_delta_log/00000000000000000000.json 2022-07-14 09:34:43 55352961 delta/part-00000-2de3a57b-1c68-4679-8c9d-c950c7e45de6-c000.snappy.parquet 2022-07-14 09:34:43 55539573 delta/part-00001-884e0e49-84d9-49c3-933e-9eddb364f674-c000.snappy.parquet 2022-07-14 09:34:52 55236752 delta/part-00002-e64a5825-7425-4435-aace-7fd77d4ba19a-c000.snappy.parquet 2022-07-14 09:34:52 55669516 delta/part-00003-d15c00cc-a2b9-4be0-9029-9132fa14a98f-c000.snappy.parquet 2022-07-14 09:35:01 55512327 delta/part-00004-73c45fe3-7572-4989-8b68-63b786f2c328-c000.snappy.parquet 2022-07-14 09:35:01 55560218 delta/part-00005-94f8f7aa-b2e5-4d61-93bd-94b11518c662-c000.snappy.parquet 2022-07-14 09:35:09 55337097 delta/part-00006-4bc8a8ae-67f9-4941-967e-4392d78161e6-c000.snappy.parquet 2022-07-14 09:35:09 55284570 delta/part-00007-e8d4d3f6-f550-4321-afbe-8ca4dd50277f-c000.snappy.parquet 2022-07-14 09:35:18 55354729 delta/part-00008-f442a193-1286-46a2-80f2-eeb25e4c75ec-c000.snappy.parquet 2022-07-14 09:35:18 55283349 delta/part-00009-973a1e4f-cccd-484e-bf59-72db29b42e3e-c000.snappy.parquet 2022-07-14 09:35:26 55466100 delta/part-00010-dd722212-766e-434c-b6d9-772bb4ca5293-c000.snappy.parquet 2022-07-14 09:35:26 55163670 delta/part-00011-e324ec88-218d-426f-bc2a-a982538f9bde-c000.snappy.parquet 2022-07-14 09:35:34 55244413 delta/part-00012-9789b931-a5b8-4ea6-957c-6d6d9c751821-c000.snappy.parquet 2022-07-14 09:35:35 55321192 delta/part-00013-b7a43423-2a53-4a41-a6f4-a8883083315c-c000.snappy.parquet 2022-07-14 09:35:42 55569791 delta/part-00014-c1b90126-3e54-4730-8ffa-7ab79a9ab112-c000.snappy.parquet 2022-07-14 09:35:44 55471295 delta/part-00015-69d1f3b7-b7ac-4357-af09-1c45ba360a3a-c000.snappy.parquet 2022-07-14 09:35:50 55426860 delta/part-00016-a276226c-169c-40b2-9cb7-c8b28d335160-c000.snappy.parquet 2022-07-14 09:35:53 55399812 delta/part-00017-2275eb45-d961-41f3-8e6f-46cd5b59bf11-c000.snappy.parquet 2022-07-14 09:35:58 55366224 delta/part-00018-38c48ee9-98f8-44f8-a30d-5898cb962e3f-c000.snappy.parquet 2022-07-14 09:36:01 55470407 delta/part-00019-05744950-7c1f-439a-a2d9-8515f21b87c6-c000.snappy.parquet 2022-07-14 09:36:06 55318799 delta/part-00020-99108c63-21e3-4560-9667-c9dfd2cce99e-c000.snappy.parquet 2022-07-14 09:36:09 55274819 delta/part-00021-cada37d7-8ecc-4d4c-8bac-97afde209cb3-c000.snappy.parquet 2022-07-14 09:36:14 55666013 delta/part-00022-16bff2b2-2346-4507-9fde-08f3d60d0f5b-c000.snappy.parquet 2022-07-14 09:36:13 22632601 delta/part-00023-b13c0d3b-e3a7-46f7-a345-fde187d4d08e-c000.snappy.parquet Total Objects: 25 Total Size: 1296944785
| データ形式 | データサイズ |
|---|---|
| CSV | 3.14GB |
| Delta Lake | 1.30GB |
このDelta Lake形式で保存されたデータと元のCSVデータのデータサイズを上記の表を用いて比較します。Delta Lake形式にすることでCSV形式よりもおよそ59%のデータサイズが削減可能です。これはDelta Lakeの内部形式であるApache Parquetの高い圧縮率が主要な要因であると考えられます。
データ処理時間の比較
データ処理時間の比較のため、S3 on OutpostsにCSV, Delta Lake形式で同様のデータを保存し処理の時間をそれぞれ30回計測します。処理内容は次のように特定のカラム(category)のグループ集計をとるものとします。
sc.hadoopConfiguration.set("fs.s3a.bucket.delta-bucket.accesspoint.arn", "arn:aws:s3-outposts:ap-northeast-1:123456789:outpost/op-123456789/accesspoint/delta-lake") // CSV形式で処理する時間を計測する val csv_path = "s3a://delta-bucket/csv/train_de.csv" val csv_df = spark.read.format("csv").option("header", "true").option("inferSchema", "true").option("delimiter", "\t").load(csv_path) spark.time(csv_df.groupBy("category").count().show()) // Delta Lake形式で処理する時間を計測する val base_path = "s3a://delta-bucket/delta" val delta_df = spark.read.format("delta").load(basePath) spark.time(delta_df.groupBy("category").count().show())
| データ形式 | 処理時間(sec) |
|---|---|
| CSV | 26.3 |
| Delta Lake | 4.3 |
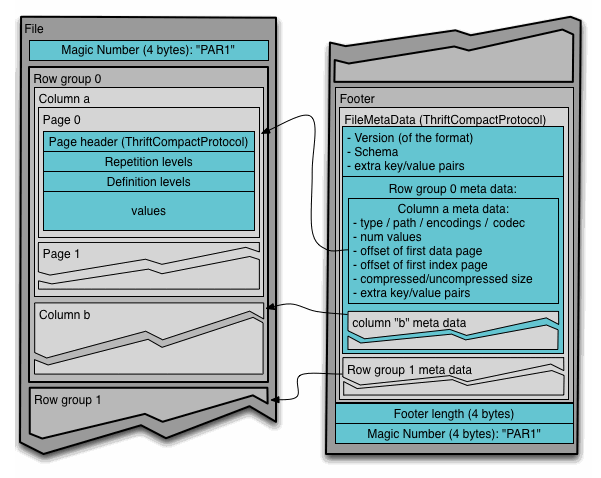
上記が平均の処理時間の表になります。Delta Lake形式の方がCSV形式よりも高速に処理可能であることが分かります。CSVのデメリットとしてデータ形式上特定の列データ(category)のみを読み込むことができないため、今回の処理では全データを読み込むオーバーヘッドが生じます。一方、Delta Lake形式は内部形式Apache Parquetが次の画像のように列指向フォーマットで保存されているため特定の列データ(category)のみを読み込むことが可能となり、不必要なデータを読み飛ばしたことでCSVよりも高速に処理できました。
まとめ
以上のようにAWS Outpostsを用いることでオンプレ環境にスケーラブルなストレージ・分析基盤の構築や、稼働コストを抑えた保守運用、AWSサービスを包括的に使用することで高いセキュリティを達成可能であることを紹介しました。 また、性能検証の結果から従来のようにCSV形式のままで保存するよりもDelta Lakeを利用することでデータサイズの大幅な圧縮とデータ処理時間の高速化というメリットが得られることを示しました。