
目次
はじめに
イノベーションセンターの加藤です。普段はコンピュータビジョンの技術開発やAI/MLシステムの検証に取り組んでいます。
今年登場したJetsonの最新版モデル「Jetson AGX Orin」は、前世代である「Jetson AGX Xavier」シリーズの最大8倍のパフォーマンス1、ビジョンや自然言語処理など様々な学習済みモデルにおいては最大5倍の高速化2が謳われており、エッジデバイス上で動かせるAIアプリケーションの幅がかなり広がりそうです。普段メディアAIに取り組んでいる私としてはどのレベルまでの物体検出モデルがエッジ上で動かせるようになったのかが気になりました。そこで本記事ではMMDetectionの提供する物体検出モデルをNVIDIA TensorRTを用いて各デバイス上で最適化し、COCO Val 2017データセットを用いてモデルの推論速度を調査しました。
MMDetectionとは
https://github.com/open-mmlab/mmdetection
MMDetectionはOpenMMLabの提供する物体検出ツールボックスです。ソースコードだけでなく学習済みモデルも公開されているので、さまざまなモデルを使って物体検出の推論ができます。 このツールボックスはPyTorchベースですが、各Jetsonデバイスの性能をめいっぱい活かすために、MMDeployというツールを用いて学習済みモデルをTensorRTモデルに変換してから速度を計測しました。
MMDeployとは
https://github.com/open-mmlab/mmdeploy
MMDeployはMMDetection同様にOpenMMLabが提供するツールで、OpenMMLab製のモデルをONNXやTensorRTなどのバックエンド用に変換して利用できます。物体検出のMMDetectionだけでなく、分類(MMClassification)やセグメンテーション(MMSegmentation)、姿勢推定(MMPose)などのモデルにも対応しています。
実は以前までは内部で使われているビルドオプションの都合上Orinに対応したバイナリがビルドできずMMDeployをOrinで使うにはひと手間必要でしたが、私のプルリクエストによりversion 0.6以降はデフォルトの設定で利用できるようになっています :)
実験内容
使用したデバイスは以下の2点です。
- Jetson AGX Xavier
- Jetson AGX Orin 32GB
いずれのデバイスにもNVIDIA JetPack SDK 5.0を導入しています。 評価データセットは5000枚の画像からなるCOCO Val 2017を使いました。 そしてMMDeployは変換したモデルのベンチマークを計測することができるので、本記事ではこの機能を用いてXavierとOrinそれぞれにおけるTensorRTモデルの推論速度(FPS)を計測しました。
実験コードは こちら にアップロードしていますので参考にしてください。
利用したモデル
実験に使用したモデルの一覧を示します。configリンクは全てMMDetectionのリポジトリ内のコンフィグファイルを指しており、そのコンフィグファイルが置いてあるディレクトリのREADMEでモデルの概要を見ることができます。
| モデル名(バックボーン) | 入力サイズ | box AP | link |
|---|---|---|---|
| YOLOV3(DarkNet53) | 320x320 | 27.9 | config |
| SSD300(VGG16) | 300x300 | 25.5 | config |
| RetinaNet(ResNet50) | 800x1333 | 36.5 | config |
| FCOS(ResNet50) | 800x1333 | 36.6 | config |
| FSAF(ResNet50) | 800x1333 | 37.4 | config |
| YOLOX-s | 640x640 | 40.5 | config |
| Faster R-CNN (ResNet50) | 800x1333 | 37.4 | config |
| ATSS (ResNet50) | 800x1333 | 39.4 | config |
| Cascade R-CNN (ResNet50) | 800x1333 | 40.4 | config |
| GFL(ResNet50) | 800x1333 | 40.2 | config |
| Cascade Mask R-CNN (ResNet50) | 800x1333 | 41.2 | config |
| Mask R-CNN (ResNet50) | 800x1333 | 38.2 | config |
| Mask R-CNN (Swin Transformer) | 800x1333 | 42.7 | config |
計測結果
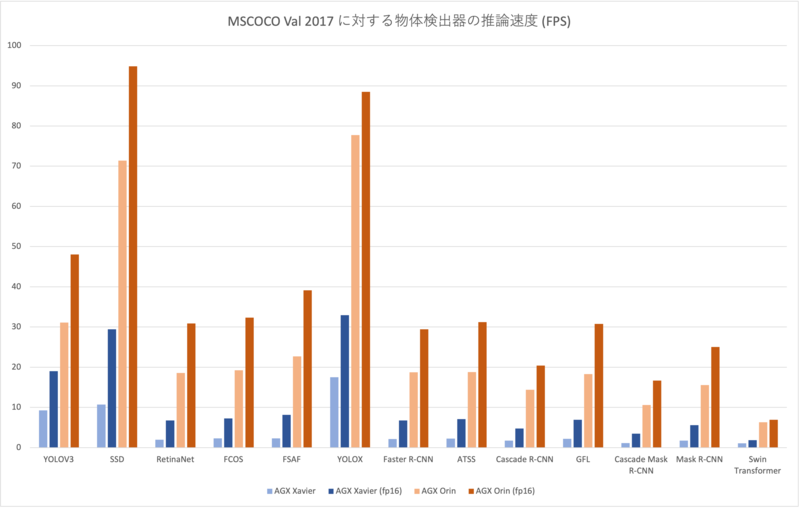
Swin TransformerをバックエンドにしたMask R-CNNはまだまだOrin上でも厳しそうですが、その他のモデルでは半精度化することによって20-30FPSとほぼリアルタイムに動作させられることがわかりました。 AGX Xavierと比較すると、どのモデルにおいても大きな速度向上が見られ、最小でも2.5倍、最大で10倍近い高速化が見られます。 一方で単純計算なら処理速度が2倍になるはずの半精度化(fp16)の恩恵はAGX Xavierが大きく、AGX Orinではあまり速度が伸びませんでした。メモリアクセスが間に合っておらず性能を出しきれていないというのが仮説の1つとして挙げられますが、より詳細な調査が必要そうです。
まとめ
本記事では様々な物体検出モデルをAGX XavierとAGX Orinで動かし、Jetson最新モデルのAGX Orinがどれくらい性能向上したかを調査しました。すると今までエッジ上ではリアルタイム処理に使えなかった高解像度・高性能なモデルが、AGX Orinでは現実的な処理速度を実現していることがわかりました。これは今までのエッジ用AIアプリケーションの性能向上につながるだけでなく、遠くの物や小さいものをリアルタイムに検知する必要があるタスクにおいてもスタンドアローンで処理可能になることも考えられ、自動運転のようにカメラに写る物体の遠近のレンジが大きい環境や、群衆の混雑度監視のように広い範囲に細々とした物体が大量に写る環境などといった解像度がネックになるタスクでもエッジAIが戦えるようになりそうです。