
はじめに
こんにちは、SDPFクラウドでSDN開発を担当している梶浦(@ykajiaaaaa)です。
今回の記事は今夏のインターンシップで私のチームに来ていただいた伊藤さんによるものです。
このインターンシップでは我々が実際に昔出会った問題をベースにトラブルシューティングを行い、その体験記を執筆いただきました。
それではどうぞよろしくお願いします。
目次
参加したインターンシップの紹介
こんにちは、インターンシップ生の伊藤吉彦です。普段は研究室でネットワークの構築・運用をしたり、WIDEプロジェクトのvSIXでSDNコントローラを作ったりしています。
2023年8月28日から9月8日の2週間、NTTコミュニケーションズのインターンシップに参加させていただきました。
本インターンシップでは「エンタープライズ向け大規模クラウドサービスを支えるネットワーク開発」というテーマで業務に参加しました。本記事ではその体験談を記載します。
配属されたチームについて
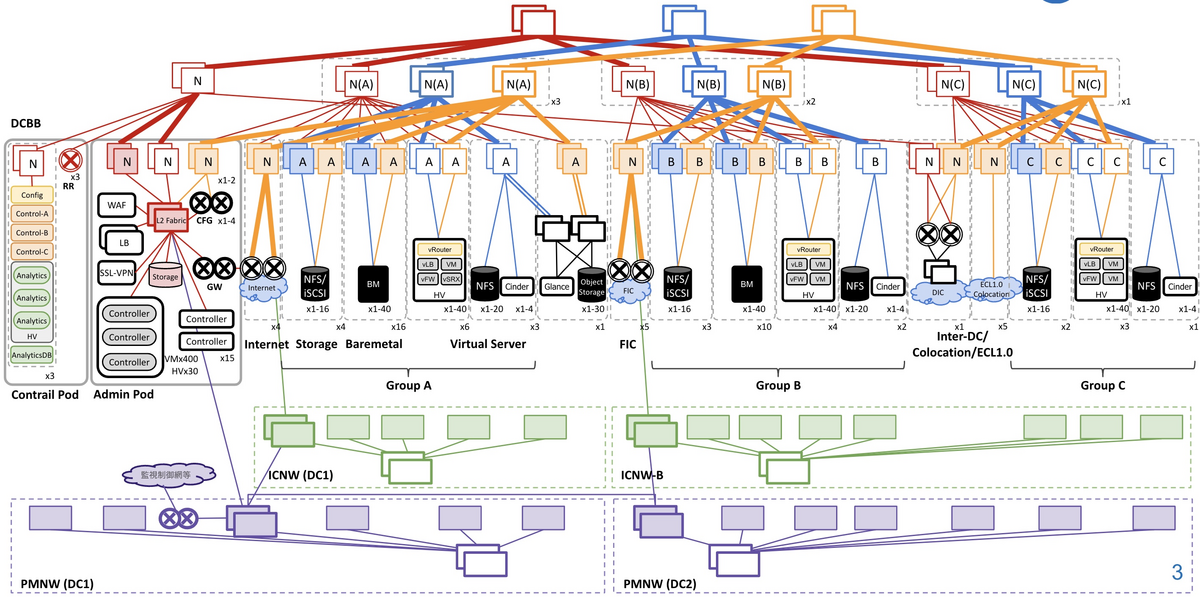
NTTコミュニケーションズでは、SDPF (Smart Data Platform)というプロダクトの一部であるSDPFクラウドで、IaaSをエンタープライズ向けに提供しています。
このサービスではオンプレのネットワークをそのままクラウドに載せることができ、仮想L2ネットワークの構築やマルチキャストなどに対応しています。
今回、このSDPFクラウドの裏で動作するSDNコントローラのチームでインターンを行いました。
インターンシップで取り組んだこと
概要
SDPFクラウドではContrailというSDNコントローラ製品を利用しています。ContrailはJuniper社の製品でありながら、Tungsten FabricとしてOSS版が公開されています。 今回はそのコードベースを用いて、「サイズが大きいパケットを送信すると、疎通しないことがある」というユーザからの申告をもとに、その原因を突き止めて修正するという業務に取り組みました。
本インターンシップではさらに、以下の情報が新たに与えられ、これらの情報を踏まえて問題を切り分けていき、原因の究明に努めました。
- 仮想ルータをインストールし直すと復旧するが、10日ほどで同じ症状が起きる
- 同じ仮想ネットワークに属するVM同士でも同様の症状が見られる
- 疎通性が全く取れない時もあれば、稀に取れる事もある
問題の切り分け
現状把握
まず、疎通性が取れなくなる状況を分析するために、パケットサイズを変えながら疎通性を確認しました。その結果、パケットサイズが1472Byte以下ではパケットロスは確認できず、1473Byte以上になると報告のあった事象が起きていました。
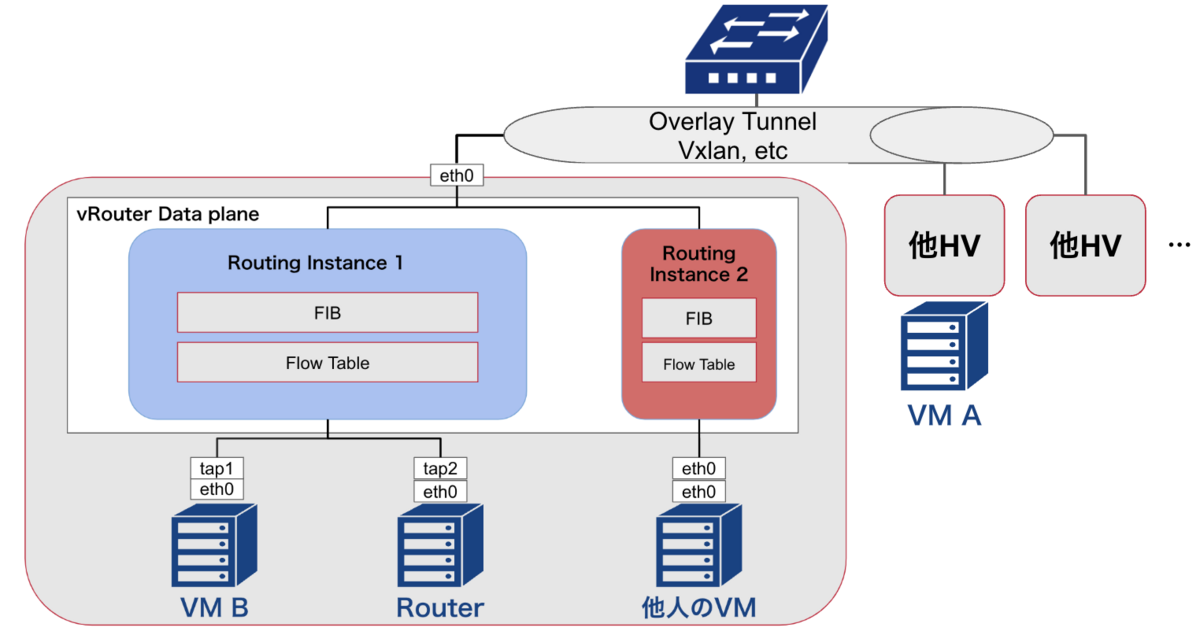
また、SDPFクラウドの転送図は以下のようになっています。ここでSDPFクラウドを構成する各要素について説明します。
- HV:HyperVisorの略称で、複数のVMを収容するサーバ
- vRouter:HV内部で複数VMのトラフィックの仮想化、転送を司るソフトウェアルータ
- vRouter Data Plane:トラフィックを転送するカーネルモジュール
- vRouter Agent:vRouterのコントロールプレーン。経路やフロー情報をvRouterに格納する
- RoutingInstance, FIB, FlowTable:vRouter内部で異なる仮想NW毎に通信を分けるために必要な情報群
- tap:仮想NWのインターフェース
VM AからVM Bへの疎通が取れないという報告を受けていましたが、分析を続けていく中で、同じHV, Routing Instance以下のVM BからRouterへの疎通においても同様の問題が確認できました。そのため、解析前はネットワークに問題があると考えたのですが、HV内の転送に原因があると分かりました。
原因箇所の更なる切り分け
続いて、原因箇所の更なる切り分けを行いました。その際、以下のツールを使用しました。
- tcpdump:パケットキャプチャ
- contrail-tools
- dropstats:vRouter上でドロップしたパケットの情報を取得
- flow:アクティブなフロー情報を取得
- vif:HV上の仮想インターフェースの情報を取得
さらに、scapyを使って、常に同じパケットを生成し、問題の原因がパケットそのものにあるかも調査しました。結果、IPヘッダのIdentificationフィールド(以降IP ID)を指定すると常に疎通が取れる、あるいは全く疎通が取れないという状況を作り出すことができ、パケットを処理するデータプレーンに原因があると推測されました。この状況でdropstatsコマンドを用いて監視すると、パケットドロップ時にFragment Errorsがカウントアップされました。以上より、vRouterのフラグメント処理に問題があることを突き止められました。
問題の修正
ここまででvRouterに原因があると分かったため、vRouterについて調査しました。
まず初めにvRouter Agentを再起動してみても疎通性は回復しませんでした。そのため、vRouterのカーネルモジュールに原因があると推測されました。vRouterカーネルモジュールはtf-vrouterをモジュール化したものです。
デバッグ方法
カーネルモジュールのデバッグを行う際、カーネルのメモリのステートをdumpしてその内容を読む手法が取られます。意図的にカーネルをクラッシュさせ、コアファイルを生成し、crashコマンドでその中身を読んでいきます。
ハッシュテーブル
vRouterではフラグメントをハッシュテーブルで管理しています。ハッシュキーはパケットのソースと宛先アドレス、IP IDなどが使われています。scapyで調査した内容も踏まえ、このハッシュテーブルに問題がありそうだという仮説を立てました。事実、crashコマンドを用いてフラグメントのハッシュテーブルの中身を覗くと、次のような結果が得られました。
crash> struct vr_htable 0xffff914c203ceea0 // fragment hash table
struct vr_htable {
ht_router = 0xffffffffc0b08620 <router>,
ht_hentries = 8192,
ht_oentries = 1024,
ht_entry_size = 97,
ht_key_size = 40,
ht_bucket_size = 4,
ht_htable = 0xffff914c2b981bc0,
ht_otable = 0xffff914c2b981000,
ht_dtable = 0xffff914c2b981e00,
ht_get_key = 0xffffffffc0ab4e70 <vr_fragment_get_entry_key>,
ht_free_oentry_head = 0x0,
ht_used_oentries = 1024,
ht_used_entries = 8306
}
ht_hentriesとht_oentriesはハッシュテーブルのエントリ数を、ht_used_oentriesやht_used_entriesはハッシュテーブルのエントリのうちすでに埋まっている数を示しています。
これらの値から、ハッシュテーブルが全て埋まることでハッシュ衝突が起きたために、フラグメントの処理がうまくいかなかったと分かりました。
エントリの削除
vRouterのフラグメントテーブルは定期的にハッシュテーブルのスキャニングが走り、最終更新から一定時間経過しているエントリは解放される仕組みになっています。1回あたり2048エントリ分スキャンされます。どうやらこのスキャンがカーネルをロードした後、1回しか走っていないようでした。
vRouterではスキャンの定期実行のために、linux timerの機能を使っています。まず、functionを実行するtimerを作ります。そして、timerの期限が切れたら、もう一度functionを動かす新たなtimerを作ることで、定期実行を可能にしています。vRouterではvt_stop_timerに格納された値で条件分岐しており、0であったらtimerが再度作られ、スキャンを再度走らせる仕組みになっています。

原因の特定
以上より、vt_stop_timerが怪しいと突き止められました。vRouterでvtimerを作っている箇所をコードレビューすると、kmallocでメモリ確保をしていました。 kmalloc はメモリを確保するものの初期化しないため、値が不定になってしまいます。ここでvt_stop_timerに0以外の値が入ると、新たなtimerが作られなくなります。
ここまでで、原因の根源はメモリの初期化ミスであることが分かりました。そのため、zallocでメモリ確保をするようにコードを修正することで対応しました。実際に修正後のモジュールをリロードすると、問題なく動作する様子が確認できました。
- vtimer = vr_malloc(sizeof(*vtimer), VR_TIMER_OBJECT); + vtimer = vr_zalloc(sizeof(*vtimer), VR_TIMER_OBJECT); if (!vtimer) { vr_module_error(-ENOMEM, __FUNCTION__, __LINE__, sizeof(*vtimer)); goto fail_init; } vtimer->vt_timer = fragment_table_scanner; vtimer->vt_vr_arg = scanner; vtimer->vt_msecs = VR_FRAG_HASH_TABLE_SCANNER_INTERVAL_MSEC; if (vr_create_timer(vtimer)) { vr_module_error(-ENOMEM, __FUNCTION__, __LINE__, 0); goto fail_init; }
もう1つの問題
ハッシュエントリが解放されないのはメモリの初期化ミスが原因でした。しかしながら、調査を進めていくうちに、もう1つのバグが起こりうる箇所を特定できました。
エントリが削除対象かを判定する関数でパケットフラグメントの宛先アドレスが0.0.0.0であった時、エントリが削除されないようになっていました。これは初期化されていないnullを想定したコードですが、nullを表す0と0.0.0.0が同一視されることで、削除されなくなっていました。通常、このアドレス宛のパケットは発行されませんが、潜在的に攻撃対象となる可能性がありました。そのため、他の箇所を確認しこの条件がなくても要件を満たせると判断した上で、以下のように修正を加えました。
fe = VR_FRAGMENT_FROM_HENTRY(ent); - if (!fe || ((!fe->f_dip_u) && !(fe->f_dip_l))) + if (!fe) return; vr_get_mono_time(&sec, &nsec); if (sec > fe->f_time + VR_FRAG_HASH_TABLE_TIMEOUT_SECS) { vr_fragment_del(table, fe); }
トラブルシューティングのまとめ
サイズの大きいパケットが一定確率でドロップしてしまうという問題のトラシューを行いました。問題を切り分けていくうちに、原因はvRouterのデータプレーンにあると突き止めることができ、パケットのフラグメント処理に問題があると分かりました。コアファイルでデバッグをすると、フラグメントのハッシュエントリが解放されておらず、ハッシュのスキャンが走っていないと分かりました。原因の根幹にあったのは、スキャンを定期実行させるためのvtimerのメモリが初期化されていないことでした。
また、攻撃可能性として0.0.0.0宛のパケットを投げるとハッシュが埋め尽くされてしまうと分かりました。
以上の2つのバグを発見し、修正を加えることができました。
ライブパッチ
本インターンシップでは、ライブパッチを当てるタスクにも取り組みました。
SDPFクラウドはエンタープライズ向けであるので、パッチを当てる際にサービスの停止時間を無視できません。通常のパッチを当てるやり方ではカーネルモジュールを置き換える必要があり、その間通信ができなくなります。ダウンタイムを極力抑えつつ、修正したパッチを当てるためにLinuxカーネルライブパッチを用いました。この機能を使うことでパッチ適用時に再起動や停止をする必要がなくなります。
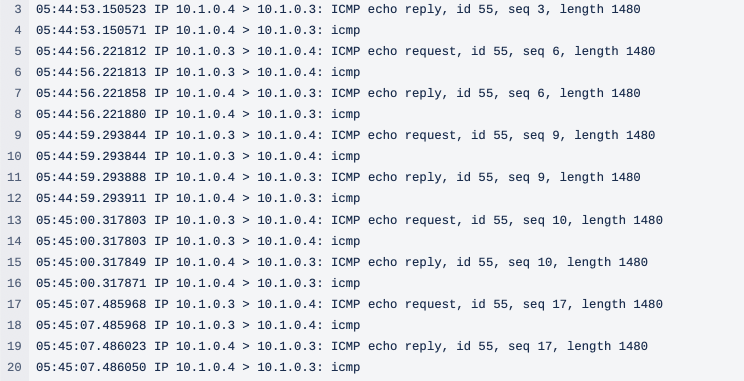
以下に示すように、通常のパッチを当てるやり方では通信断が発生しています。
1秒に1回送信しているpingパケットのicmp_seqが5-24まで欠落していることから約19秒の通信断があると分かります。
$ ping 10.0.0.4 PING 10.0.0.4 (10.0.0.4) 56(84) bytes of data. 64 bytes from 10.0.0.4: icmp_seq=1 ttl=64 time=1.24 ms 64 bytes from 10.0.0.4: icmp_seq=2 ttl=64 time=0.605 ms 64 bytes from 10.0.0.4: icmp_seq=3 ttl=64 time=0.766 ms 64 bytes from 10.0.0.4: icmp_seq=4 ttl=64 time=0.664 ms 64 bytes from 10.0.0.4: icmp_seq=5 ttl=64 time=0.771 ms # ここから 64 bytes from 10.0.0.4: icmp_seq=24 ttl=64 time=395 ms # ここまで 64 bytes from 10.0.0.4: icmp_seq=25 ttl=64 time=0.629 ms 64 bytes from 10.0.0.4: icmp_seq=26 ttl=64 time=0.700 ms 64 bytes from 10.0.0.4: icmp_seq=27 ttl=64 time=0.643 ms 64 bytes from 10.0.0.4: icmp_seq=28 ttl=64 time=0.626 ms 64 bytes from 10.0.0.4: icmp_seq=29 ttl=64 time=0.615 ms ^C --- 10.0.0.4 ping statistics --- 29 packets transmitted, 11 received, 62% packet loss, time 28606ms rtt min/avg/max/mdev = 0.605/36.612/395.474/113.482 ms
今回、kpatchを用いてライブパッチを実装しました。0.0.0.0の方はライブパッチを当てると即座にバグが修正されました。しかし、vtimerの方はタイマー作成時にmod_timerで繰り返し実行を実装している仕組み上、単にvtimerのメモリ初期化をするライブパッチを当てても修正されません。そこで、contrail-toolsのコマンドを実行するとvtimerが新たに作られるように修正を加えました。通常のパッチを当てるやり方では、通信断が回復するまで約19秒かかっていましたが、ライブパッチを使うことでダウンタイムを大幅に削減できました。結果は以下に示す通りで、ダウンタイムはほとんどありません。
PING 10.0.0.4 (10.0.0.4) 56(84) bytes of data. 64 bytes from 10.0.0.4: icmp_seq=1 ttl=64 time=1.94 ms 64 bytes from 10.0.0.4: icmp_seq=2 ttl=64 time=0.388 ms 64 bytes from 10.0.0.4: icmp_seq=3 ttl=64 time=0.559 ms 64 bytes from 10.0.0.4: icmp_seq=4 ttl=64 time=0.520 ms 64 bytes from 10.0.0.4: icmp_seq=5 ttl=64 time=0.471 ms 64 bytes from 10.0.0.4: icmp_seq=6 ttl=64 time=0.373 ms 64 bytes from 10.0.0.4: icmp_seq=7 ttl=64 time=0.437 ms 64 bytes from 10.0.0.4: icmp_seq=8 ttl=64 time=0.440 ms 64 bytes from 10.0.0.4: icmp_seq=9 ttl=64 time=0.496 ms 64 bytes from 10.0.0.4: icmp_seq=10 ttl=64 time=0.351 ms 64 bytes from 10.0.0.4: icmp_seq=11 ttl=64 time=0.522 ms 64 bytes from 10.0.0.4: icmp_seq=12 ttl=64 time=0.551 ms 64 bytes from 10.0.0.4: icmp_seq=13 ttl=64 time=0.448 ms 64 bytes from 10.0.0.4: icmp_seq=14 ttl=64 time=0.463 ms 64 bytes from 10.0.0.4: icmp_seq=15 ttl=64 time=0.532 ms 64 bytes from 10.0.0.4: icmp_seq=16 ttl=64 time=0.501 ms 64 bytes from 10.0.0.4: icmp_seq=17 ttl=64 time=0.530 ms 64 bytes from 10.0.0.4: icmp_seq=18 ttl=64 time=0.432 ms # ここから 64 bytes from 10.0.0.4: icmp_seq=19 ttl=64 time=0.492 ms # ここまで 64 bytes from 10.0.0.4: icmp_seq=20 ttl=64 time=0.428 ms 64 bytes from 10.0.0.4: icmp_seq=21 ttl=64 time=0.377 ms 64 bytes from 10.0.0.4: icmp_seq=22 ttl=64 time=0.539 ms 64 bytes from 10.0.0.4: icmp_seq=23 ttl=64 time=0.395 ms 64 bytes from 10.0.0.4: icmp_seq=24 ttl=64 time=0.547 ms 64 bytes from 10.0.0.4: icmp_seq=25 ttl=64 time=0.521 ms 64 bytes from 10.0.0.4: icmp_seq=26 ttl=64 time=0.466 ms 64 bytes from 10.0.0.4: icmp_seq=27 ttl=64 time=0.395 ms 64 bytes from 10.0.0.4: icmp_seq=28 ttl=64 time=0.536 ms 64 bytes from 10.0.0.4: icmp_seq=29 ttl=64 time=0.332 ms 64 bytes from 10.0.0.4: icmp_seq=30 ttl=64 time=0.495 ms ^C --- 10.0.0.4 ping statistics --- 30 packets transmitted, 30 received, 0% packet loss, time 29639ms rtt min/avg/max/mdev = 0.332/0.516/1.949/0.273 ms
インターンシップの感想
本インターンシップでは、普段あまり触る機会のないlinuxカーネルモジュールやライブパッチを体験でき、非常に楽しかったです。
メンターの梶浦さんを始めとし、チームの皆さんには色々と補助をしてもらいました。チームは普段リモート業務が主流のところをわざわざ対面で実施してくださり、本当に感謝しています。2週間という短い期間でしたが、おかげさまで大変充実した時間を過ごすことができました。
また、データセンターの見学や送別会で、インターネット作ってきて今はIOWNに携わっている日本電信電話株式会社所属の先輩とお話をする機会を設けていただいたりと、貴重な体験をさせたいただきました。
最後になりますが、本インターンシップでさまざまな経験をさせていただき本当にありがとうございます。
メンターからのコメント
梶浦です。伊藤さん、まずはお疲れ様でした。
2週間という短い期間かつ、普段あまり触れない領域であったにも関わらず持ち前の深い洞察力ですぐに深い部分まで理解しておられました。
最後には我々も初挑戦だったカーネルライブパッチまで実装いただき、実務上も大変助かりました。ありがとうございます。
この類まれな技術力と課題解決能力でこれからもご活躍されることを心より信じています。
さいごに
NTTコミュニケーションズでは冬期にもインターンシップの開催を予定しており、募集が始まっています。
私のチームでも「48.エンタープライズ向け大規模クラウドサービスを支えるネットワーク開発」(「プロダクト・サービスエンジニア」ワークフィールド内にあります)で募集しています。
このポストではSDN開発だけでなく、クラウド上でネットワーク機能を提供するNFV開発や、その裏側にあるバックボーンネットワークの開発にも携わることができます。
このような内容に興味のある方はぜひご応募ください。