
この記事は NTTコミュニケーションズ Advent Calendar 2023 の15日目の記事です。
この記事では、ChatGPT と 音声認識モデルの Whisper を用いた発音練習アプリケーションをご紹介します。
ChatGPT に読み上げる文章を考えてもらい、その文章の読み上げた音声を Whisper で文字起こしします。 正確に発音できていれば、正確に文字起こしできる、という考えから、 原稿と文字起こし結果を比較すれば発音練習に使えるのではないかと考えました。
実際に使ってみた結果、発音のどこが悪かったのかといったフィードバックはもらえませんが、 自分の発話した音声に対して評価がつくだけでも、結構楽しく練習できると感じました。
音声認識を活用したアプリケーションは、一般に音声認識精度がネックになると思いますが、 このアプリケーションは音声認識精度が100%ではないことを逆手にとっている点と ChatGPT に比べると影の薄い Whisper くんの長所である多言語対応を活用できている点がユニークです。
本アプリケーションは Streamlit を用いて比較的簡単に作成できました。 Streamlit で音声データを扱うアプリケーションは文献が少ないように感じるので、 本記事が似たようなことをやりたい方の参考になれば幸いです。
目次
はじめに
こんにちは、ソリューションサービス部の是松です。 普段はデータ利活用ソリューションに向けた、技術検証やデータ分析のPoCを行っています。
生成AIをはじめとする革新的な技術が次々と世に出てくる昨今、それらの新しい技術を使ってどんなことができるのかを手軽に試したいですよね。 Streamlit は、簡単に UI を含むアプリケーションを作成できるため、技術検証やデモをスピーディに行うのに便利です。
Streamlit は 3rd-party ライブラリがいくつも作られているのも特長で、 streamlit-webrtc というライブラリを使うことで、映像・音声も手軽に処理できます。
今回は (1) ChatGPT を使って読み上げ原稿を作成、 (2) streamlit-webrtc を使って音声を録音、(3) Whipser を使って文字起こし、という手順をとっています。 音声をあつかうアプリケーションは検索してもあまり情報がなく、はまりどころも多いので、本記事が音声を扱ったアプリケーションをつくりたい方の参考になれば幸いです。
発音練習アプリの使い方
アプリケーション全体の処理の流れは以下の通りです。
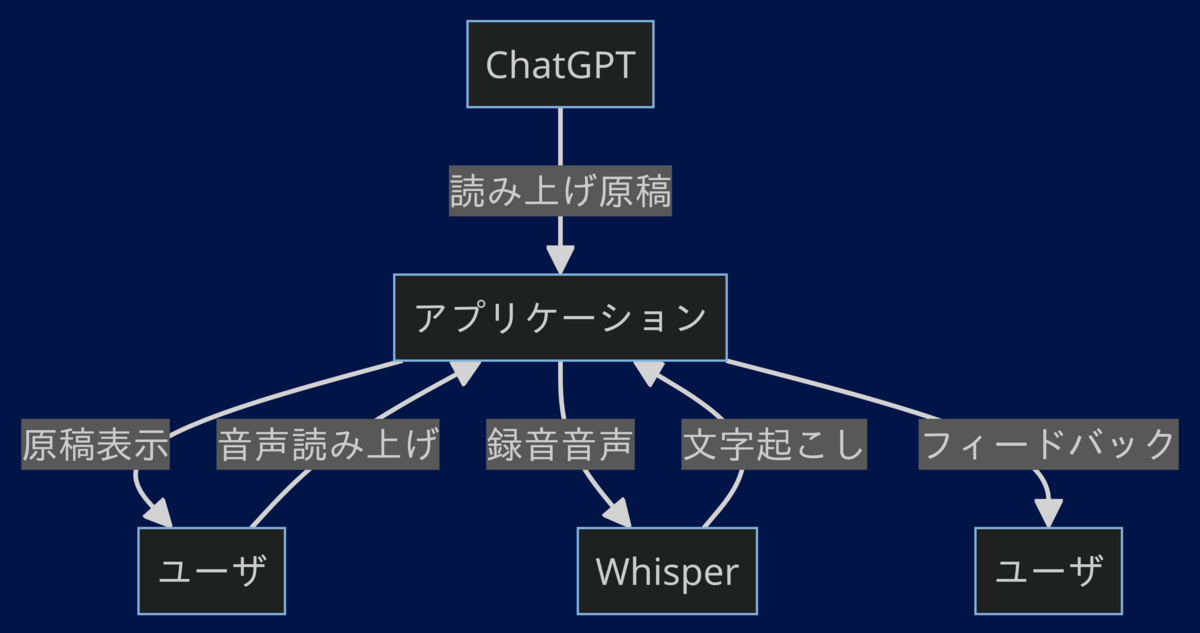
読み上げ原稿の用意
まず、自分が練習したい文章を ChatGPT に生成してもらいます。 今回は英語で比較的簡単な文章の練習をすることにします。

{ "scripts": [ "The quick brown fox jumps over the lazy dog.", "A kind smile can make someone's day better.", "Every morning, I enjoy a cup of green tea.", "The library is quiet and perfect for studying.", "On Sundays, we often go to the park.", "She plays the piano beautifully and gracefully.", "The cat sat on the warm windowsill.", "Learning a new language is both challenging and rewarding.", "He jogs around the lake every evening.", "Birds sing cheerfully in the early morning." ] }
...私にとっては結構難しそうな文章が出てきたので、今回はもっと簡単なもので試すことにします。
{ "scripts": [ "The cat sat on the mat.", "I like to eat apples and bananas.", "My friend is very kind." ] }
このjsonファイルを所定の場所に置いておきます。
読み上げ文ごとに音声を録音する
アプリケーションを起動すると、以下のような画面が表示されます。

赤い Start ボタンを押すと、音声録音が始まります。 もう一度ボタンを押すと録音が止まり、録音した音声を確認できます。
音声の確認が済んだら、右上の Next ボタンを押して次の原稿に移ります。 これを繰り返します。
結果を確認する
全ての原稿の録音が終わると、結果画面が表示されます。

読み上げ原稿と、録音の文字起こしが完全に一致した場合を正解として、 正解した問題数が得点になります。
音声認識処理はバックグラウンドで動いているので、まだ処理が完了せず画面に反映されていない場合は、更新ボタンを押して画面を更新します。
このように、実際に自分の発話を聞いて音声認識モデルにどのように認識されるのかを確認することで、 自分一人でのスピーキングの反復練習に活用できます。
実装に使ったライブラリ・フレームワークの紹介
Streamlit
Streamlit は、Python を使って簡単にWebアプリケーションを作成できるフレームワークです。
以下のような特長を持ちます。
- シンプルで便利なウィジェットを組みあわせることで、少ない行数でアプリケーションを構成できる
- Python が得意なデータ処理や機械学習モデルとの組み合わせが容易にできる
- 3rd-party モジュールが多数公開されており、さまざまな用途に対応できる
詳しくは、公式ドキュメントをご参照ください。
streamlit-webrtc
streamlit-webrtc は、Streamlit 上でリアルタイム映像・音声信号処理ができる 3rd-party ライブラリです。
色々なユースケースのサンプルコードも公開されており、映像・音声を使ったアプリケーションの検証をするのに便利です。 WebRTC の特性上、streamlit-webrct ではクライアントとサーバ間で映像・音声ストリームのやり取りをリアルタイムに行います。 そのため、頻繁に画面が更新される Streamlit と相性が良くなかったり1、ネットワーク上の問題で正常に動作しなかったりと、使いこなす難易度は高いと感じました。
今回は以下のページを参考に実装しています。
Whisper
OpenAI の多言語音声認識モデルです。ソースコードは公開されており、誰でも自由に試すことができます。
APIサービスも提供されています。(Large モデルのみ)
昨年のアドベントカレンダー企画で書いた記事 にて、Whisper を紹介していますので、よろしければご参照ください。
先月の OpenAI DevDay にて、large-v3 モデルの発表もありましたが、ChatGPT の話題性に比べて、あまり盛り上がっていないように感じられて悲しいです。
振り返り
Streamlit を使ってみた感想
今回、フレームワークとして Streamlit を採用しましたが、プロトタイプアプリケーションを作成するのに、非常に有用だと感じました。 特に Whisper で音声認識をする処理を Python でそのまま書けるため、手元で Whisper を試すのと同じ感覚で、アプリケーション開発への組み込みができました。 音声録音処理は、はまりどころが多くて苦労したのですが、UIを全く意識することなく処理を実装できました。
課題としては、UI はあらかじめパーツが決まっており、自分でカスタマイズができないこと。 コードは短くシンプルに書けるが、裏側でどのように処理が行われているのかが見えづらいため、デバッグが難しいこと。 あくまでプロトタイプやデモアプリケーション向けのフレームワークであると感じました。
音声認識を活用したアプリケーションの作成
Whisper を使って誰でも手軽に高精度の音声認識モデルを触れるようになりましたが、 なかなか活用するのは難しいと感じていました。
Whisper はモデルタイプが複数あり、large モデルの性能が一番良いのですが、 その分、マシンスペックや実行時間が重くなってしまいます。 また、音声認識精度が高いとはいえ、ミスはどうしても発生してしまいます。 音声認識結果を活用しようとしても、認識ミスのせいで満足のいくクオリティのものが作れないという悩みを持つ人は多いのではないでしょうか?
今回作った発音練習アプリケーションは、音声認識に誤りがあることを逆に利用して、正しく音声認識させることを目的にしている点が面白いと思っています。 Whisper の軽量モデルは、large モデルと比較すると性能が落ちてしまうのですが、今回のアプリではそれが難易度上昇に繋がっていて、ポジティブにも捉えられると思います。 また、Whisper はさまざまな言語に対応しており言語推定機能を備えているため、読み上げ原稿さえ用意すれば、好きな言語で発音練習ができるはずです。 まだまだ機能としては荒削りですが、個人的に使いたいと思えるアプリケーションを作ることができました。
今後やりたいこと
読み上げ原稿のリアルタイム生成
アプリケーション上で ChatGPT への問い合わせを行なって、毎回ランダムな問題が表示できるようにしてみたいです。 API 料金がかかるので、リアルタイム生成結果はファイル保存した上で、リアルタイム生成かファイル参照かを選べるようにすると良いかなと思います。
発音記号の実装
JSON のフォーマットを変更して、発音記号などで読み方も表示されるようにしたいです。
正誤判定処理の見直し
現状は完全一致を正解としているので、もう少しゆるい正誤判定ルールに変更したいです。
アプリケーションの主要な構成要素の解説
ここからは、実際のアプリケーションのコードをかいつまんで解説します。
Questionクラス
まず、読み上げる文章ごとに、録音音声や文字起こしテキストをまとめて管理するためのクラスを用意します。
import hashlib from dataclasses import dataclass from pathlib import Path @dataclass class Question: script_index: int script: str transcript: str wav_dir_path: Path @property def file_id(self): return hashlib.md5((self.script + str(self.script_index)).encode()).hexdigest() @property def output_wav_name(self): return f"{self.file_id}.wav" @property def wav_file_path(self): return self.wav_dir_path / self.output_wav_name @property def record_info(self): return {"script": self.script, "file_name": self.output_wav_name}
script は読み上げ文、transcript は録音の文字起こし、wav_dir_path は録音ファイルの保存先の情報を格納します。
ファイル名はハッシュ処理をしており、プロパティとして参照できます。
読み上げ原稿の表示
ChatGPT に作成してもらった読み上げ原稿情報を、scipts/en.json に格納しておきます。
それを以下のようにして、アプリケーションで表示させています。
import streamlit as st from pathlib import Path from question import Question # 録音ファイルの保存先の設定 RECORD_DIR = Path("./records") RECORD_DIR.mkdir(exist_ok=True) # セッション状態の管理 if 'current_question_index' not in st.session_state: st.session_state['current_question_index'] = 0 # 問題文を読み込む script_file_path = Path('scripts/en.json') scripts = load_scripts(script_file_path) # 問題リストの初期化 if 'questions' not in st.session_state: st.session_state['questions'] = [ Question(script_index=i, script=script, transcript="", wav_dir_path=RECORD_DIR) for i, script in enumerate(scripts) ] # 現在の問題を取得 question = Question( script_index = st.session_state["current_question_index"], script = scripts[st.session_state['current_question_index']], transcript = "", wav_dir_path = RECORD_DIR, ) # 読み上げ文を表示 st.markdown(f"# {question.script}")
Streamlit では、画面に何かしらの変更があるたびに、コードが全て再実行される仕様となっているため、
通常の変数だと画面の更新のたびに初期化されてしまいます。
streamlit.session_state を使用することで、セッションを通して変数を保持できます。
上のコードでは current_quesiton_index と questions という2つの変数を、セッションを通して保持しています。
current_quesiton_index は、「現在表示している問題が何問目か」を管理する変数で、
questions は、読み上げ分の数だけ Question クラスオブジェクトを保持する変数です。
ファイルから読み上げ原稿を読み込んだ後、questions を初期化します。
この時点では、文字起こしは存在しないため、transcript の中身は空にしておきます。
最後に、st.markdown() を使って、問題文を表示します。
音声の録音
録音用の WebRTCRecord クラスを定義します。
import queue import pydub import streamlit as st from streamlit_webrtc import WebRtcMode, webrtc_streamer class WebRTCRecord: def __init__(self): self.webrtc_ctx = webrtc_streamer( key="sendonly-audio", mode=WebRtcMode.SENDONLY, audio_receiver_size=256, rtc_configuration={"iceServers": [{"urls": ["stun:stun.l.google.com:19302"]}]}, media_stream_constraints={ "audio": True, }, ) if "audio_buffer" not in st.session_state: st.session_state["audio_buffer"] = pydub.AudioSegment.empty() def recording(self, question): status_box = st.empty() while True: if self.webrtc_ctx.audio_receiver: try: audio_frames = self.webrtc_ctx.audio_receiver.get_frames(timeout=1) except queue.Empty: status_box.warning("No frame arrived.") continue status_box.info("Now Recording...") sound_chunk = pydub.AudioSegment.empty() for audio_frame in audio_frames: sound = pydub.AudioSegment( data=audio_frame.to_ndarray().tobytes(), sample_width=audio_frame.format.bytes, frame_rate=audio_frame.sample_rate, channels=len(audio_frame.layout.channels), ) sound_chunk += sound if len(sound_chunk) > 0: st.session_state["audio_buffer"] += sound_chunk else: break audio_buffer = st.session_state["audio_buffer"] if not self.webrtc_ctx.state.playing and len(audio_buffer) > 0: status_box.success("Finish Recording") try: audio_buffer.export(str(question.wav_file_path), format="wav") except BaseException: st.error("Error while Writing wav to disk") # Reset st.session_state["audio_buffer"] = pydub.AudioSegment.empty()
初期化処理で、webrtc_streamer の設定します。
クライアントからサーバーへの送信のみを行うモード(サーバからクライアントへの送信は行わない)で、映像なし音声ありの設定です。 key は単なる識別子なのでなんでも良いです。
session_state で audio_buffer 変数を保持して、音声バイナリデータを溜めていきます。
recording 関数の中の、While 句の中身は、ユーザが録音開始ボタンを押してから停止ボタンを押すまでの間に実行されるループ処理です。
録音している音声バイナリを、audio_buffer 内に蓄積させる処理が行われています。
停止ボタンが押されたら、audio_buffer の中身を、ファイルに書き出して処理を終了します。
このコードからわかるように、録音中は音声データを蓄積し続けるので 停止をしないと、そのうちバッファが溢れアプリケーションが落ちます。
音声認識
import threading import whisper import streamlit as st def format_string(s): s = s.replace(',', '') s = s.replace('.', '') s = s.strip() return s def transcribe(file_path, model): result = model.transcribe(str(file_path)) return format_string(result["text"]) def async_transcribe(question, model): transcript = transcribe(question.wav_file_path, model) question.transcript = transcript def start_transcription_thread(question): model = st.session_state["ASR_MODEL"] x = threading.Thread(target=async_transcribe, args=(question, model)) x.start() # 次の問題へ if st.button("Next >") and question.wav_file_path.exists(): # 音声ファイルがない場次へ行い current_question = st.session_state['questions'][st.session_s['current_question_index']] # トランスクリプションをバックグラウンドで開始 start_transcription_thread(current_question) # 次の問題へ移動 st.session_state["current_question_index"] += 1
音声認識処理は実行に時間がかかるため、別スレッドで実行しています。
音声認識結果は、question.transcript に格納され、結果表示画面で参照されます。
また、音声認識処理開始と合わせて、 current_question_index 変数をインクリメントすることで、次の問題が表示されます。
結果表示
# 結果表示画面 if st.session_state['current_question_index'] >= len(scripts): score = 0 st.title("結果発表") for question in st.session_state['questions']: if question.script == question.transcript: score += 1 if question.transcript: st.markdown(f"### 問題 {question.script_index}") st.write(f"原稿:{question.script}") st.write(f"結果:{question.transcript}") else: st.markdown(f"### 問題 {question.script_index}") st.write(f"原稿:{question.script}") st.write(f"結果:処理中...") st.markdown(f"# あなたのスコアは... {score} 点!") # スレッドが完了した後にボタンを表示 if st.button("画面を更新"): st.rerun()
最後の問題が終わったら、結果表示画面に移ります。
questions に保持している情報を展開していくだけですが、音声認識が終わっていない場合は transcript 変数の中身は初期化時の空白のままなので、処理中.... と表示されます。
streamlit.rerun() を実行すると、強制的に画面の更新ができ、もし更新時に音声認識が終わっていれば、結果が正しく表示されます。
おわりに
本記事では、Streamlit を用いた発音練習アプリケーションを紹介しました。 音声を使ったアプリケーション作成の参考になれば幸いです。
それでは、明日の記事もお楽しみに!