
AWS Lake Formationでのデータレイク登録からデータアクセスまで
この記事は NTTコミュニケーションズ Advent Calendar 2021 の16日目の記事です。
はじめに
はじめまして!BS本部SS部の荒井です。データマネジメントに関するプリセールスを担当しています。
今回はアドベントカレンダー企画ということで、AWS Lake Formationに関する記事を投稿をさせていただきます。
データレイクとAWS Lake Formation
近年データ分析の盛り上がりなどから、散逸している様々な形式のデータを一元管理できるレポジトリ、いわゆるデータレイクを導入するケースが増えてきています(参考:データレイクとは)。 例えばシステムごとに保存されていた「会員データ」「購入履歴」「問合せ履歴」などのデータをデータレイクに集約することでシステム横断の顧客分析を手軽に行うことができ、利益率向上の施策を検討したり顧客離れの原因を理解することにつながります。
AWSではこのデータレイクを構築するためのLake Formationというサービスがあります。
Lake Formationではデータカタログや権限管理などデータのマネジメントに関わる様々な機能を持っています。
今日はこのLake Formationを用いて、以下の流れでデータレイク作成からデータカタログを介したデータアクセスまでの操作に関してお話ししたいと思います。
- データレイクを作成する
- 保持しているファイルをデータレイクに保存する
- データレイクに保存したファイルのメタデータを自動取得しデータカタログに登録する
- データカタログを介してファイルの中身にアクセスする
権限周りの設定やフォルダ構成など、ところどころで注意点があるのでこちらも随時説明していけたらと思います。
全体図
全体のイメージは以下になります。
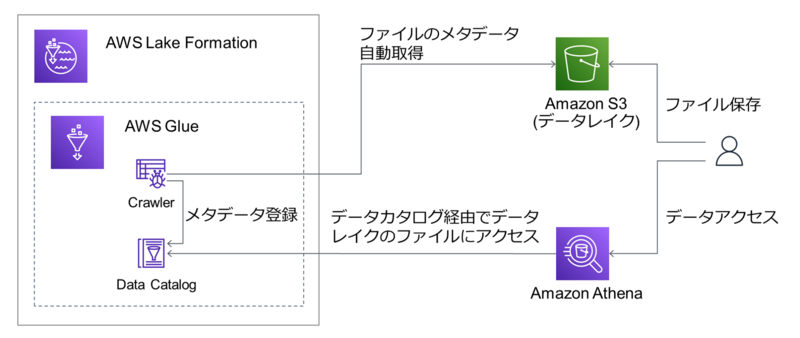
流れに沿うとポイントは以下の通りです。
Lake Formationは裏ではGlueの機能をベースに作られているため、ここでもGlueの機能を使います。
- データレイクを作成する ⇒ データレイクはAWSだと
S3になります。 - 保持しているファイルをデータレイクに保存する ⇒ 今回は手動で実施します。
- データレイクに保存したファイルのメタデータを自動取得しデータカタログに登録する ⇒ メタデータの自動取得は
GlueのCrawlerを使います。データカタログもGlueの機能です。 - データカタログを介してファイルの中身にアクセスする ⇒ 今回は手軽にSQLを叩いてアクセスできる
Athenaを使います。
データレイクを作成する
データレイクとするS3 Bucketを作成してLake Formationに登録します。
以降の作業はAWSのコンソールにログインして実行します。
まずはS3 Bucketを作成します。
S3に移動 >バケットを作成- 設定値で以下を入力(指定がないものはデフォルト) >
バケットを作成- バケット名 : 任意の名称
次に作成したS3 BucketをLake Formationに登録します。
なお、登録時にはIAM Roleが必要となりますが通常はAWSServiceRoleForLakeFormationDataAccessというAWSが用意したものを使えば大丈夫です。
ただ、ユースケースによっては自分で作成する必要があります。詳しくはこちらを参照ください。
AWS Lake Formationに移動- 初回だと
Welcome to Lake Formationのダイアログが出るので、Add myself>Get Started(データレイク管理者を自分に定義) Data lake locations>Register location- 設定値で以下を入力(指定がないものはデフォルト) >
Register location- Amazon S3 path : 作成した
S3 Bucket - IAM Role :
AWSServiceRoleForLakeFormationDataAccessor 自分で作成したIAM Role
- Amazon S3 path : 作成した
これでデータレイクの作成と登録は完了です!
保持しているファイルをデータレイクに保存する
次に、ファイルをデータレイクに保存します。
本記事では手動で行いますが、Lambda等を使って自動化しても大丈夫です。
今回はサンプルデータとしてよく使われるタイタニック号乗客者データを使います。こちらなどからダウンロードしておきます。
S3> データレイクのS3 Bucketを選択フォルダの作成からtitanicという名称のフォルダを作成- 作成した
titanicフォルダにタイタニック号乗客者データ(titanic.csv)をアップロード
無事データレイクにデータを保存できました!
(補足) 今回のケースではtitanicフォルダを1つ作成するのみでしたが、より多くの種類のデータを保存する場合にはフォルダ構成は重要です。
この後でCrawlerという機能を使ってデータカタログへ自動登録する際に、フォルダ構成に従って精査されたり各種名称が決められるためです。
以下にフォルダ構成の一例を示します。
- 例えば、サービスAの購買データ、アクセスデータ、会員データを保存する場合を考えます。
まず最初はサービスA用の大きくひとくくりのフォルダを作ります。
<データレイク用S3 Bucket> |- serviceA ←作成次に、購買データ、アクセスデータ、会員データ用のフォルダ(
buy,access,member)を作ります。<データレイク用S3 Bucket> |- serviceA |- buy ←作成 |- access ←作成 |- member ←作成購買データは年ごとの
2020.csv,2021.csvというようなファイルだったとします。この場合は、作成したbuyフォルダにそのままアップロードします。<データレイク用S3 Bucket> |- serviceA |- buy | |- 2020.csv ←アップロード | |- 2021.csv ←アップロード |- access |- memberアクセスデータは時間ごとの
2200.csv(22時のデータ),2300.csv(23時のデータ)というようなファイルで、日ごとのフォルダが必要だったとします。この場合は作成したaccessフォルダ下に日付のフォルダを作り、その中にアップロードします。<データレイク用S3 Bucket> |- serviceA |- buy | |- 2020.csv | |- 2021.csv |- access | |- 20210101 ←作成 | | |- 2200.csv ←アップロード | | |- 2300.csv ←アップロード | |- 20210102 ←作成 | | |- 2200.csv ←アップロード | | |- 2300.csv ←アップロード |- member最後に、会員データは
member.csvという1つだけのファイルだったとします。この場合も作成したmemberフォルダにそのままアップロードします。注意点は、この場合も会員データ用のフォルダ(member)を作らないといけなく、serviceAフォルダ配下にアップロードしてはいけない点です。<データレイク用S3 Bucket> |- serviceA |- buy | |- 2020.csv | |- 2021.csv |- access | |- 20210101 | | |- 2200.csv | | |- 2300.csv | |- 20210102 | | |- 2200.csv | | |- 2300.csv |- member |- member.csv ←アップロード |- member.csv ←ここにアップロードするのはNG!上記のようなフォルダ構成を取ると、この後の手順でデータカタログを自動作成した時に
buy,access,memberというテーブルが作成されます。※今回はこの例のようにはなりません。
データレイクに保存したファイルのメタデータを自動取得しデータカタログに登録する
次に、GlueのCrawlerという機能を用いてデータレイクに保存したファイルのメタデータを自動取得し、データカタログに登録します。
メタデータとはフォーマット(csvやparquetなど)や構造(csvのカラムなど)、保存場所などデータがどのようなものかを表す情報になります。
まず、メタデータを登録する先となるデータカタログのデータベースを作成する作業をします。
Lake Formation>Data catalog下のDatabases>Create database- 以下を入力(指定がないものはデフォルト) >
Create database- Name:任意の名称
また、任意でLF-Tagをデータベースにアサインします。
LF-TagはLake Formation Tagの略で、Lake Formation内で権限管理などに使えるタグになります。
Lake Formationではこちらを設定して権限管理することが推奨されています。(この後の手順を進めると以下のようにLF-Tagがrecommendedされているのが確認できます。)
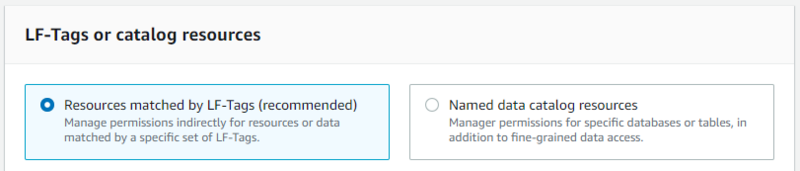
ただし、どのようなLF-Tagを定義しておくかの設計が事前に必要なのと、データレイク管理者のみがLF-Tagを作成できることは注意が必要です。(参考:LFタグの作成)
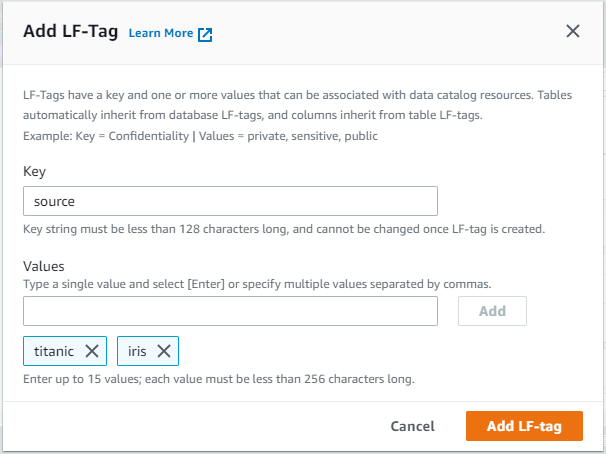
Lake Formation>Permissions下のLF-Tags>Add LF-TagKeyとValuesを設定してAdd LF-Tag
ここではLF-Tagの事前の設計が必要ですが、例えば以下のようなKey,Valuesなどが考えられます。Key=env,Values=development, staging, productionKey=service,Values=serviceA, serviceBKey=source,Values=titanic, iris※今回はこちらを設定します。irisの方は使用しません。
Databasesに戻り、作成したデータベースを選択 >Actions>Edit LF-TagsAssign new LF-Tagを押して、設定したいKeyとValues(今回はKey=source,Values=titanic)を選択してSave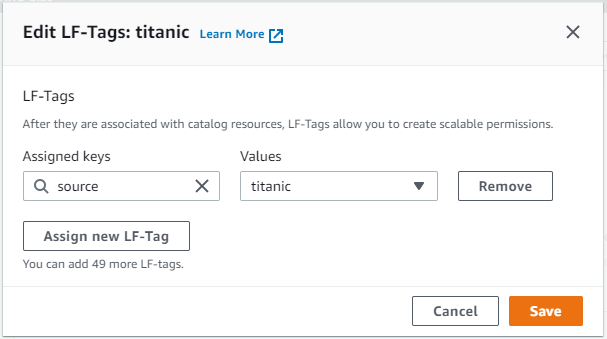
次に、Crawlerで使用するIAMロールを作成し権限を付与します。
権限付与はいくつか必要になりますので少し長いですが、最後に補足で各手順がどのような用途のためなのかをまとめます。
IAM>ロール>ロールを作成- 以下を入力(指定がないものはデフォルト) > 最後に
ロールの作成- ユースケース:
Glueを選択 - アクセス権限:
AWSGlueServiceRole - ロール名:任意の名称
- ユースケース:
- 作成した
IAMロールを選択 >+インラインポリシーの追加 JSONタブに切り替えて以下を入力してポリシーの確認>名前に任意の名称を入れてポリシーの作成
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": "s3:*",
"Resource": [
"arn:aws:s3:::<データレイクのS3バケット名>",
"arn:aws:s3:::<データレイクのS3バケット名>/*"
]
}
]
}
データベースへの権限付与を以下の手順で実施します。
Lake Formationに移動 >Permissions下のData lake permissions>Grant- 以下を入力(指定がないものはデフォルト) > 最後に
Grant- IAM users and roles:上記で作成した
IAMロール - LF-Tags or catalog resources
- データベースに
LF-Tagを設定した場合はResources matched by LF-Tags (recommended)を選択 >Add LF-Tagでデータベースに設定したLF-TagのKey,Valuesを選択(今回はKey=source,Values=titanic) - 設定していない場合は
Named data catalog resourcesを選択 >Databasesで作成したデータベースを選択
- データベースに
- Database permissions:
Database permissionsのSuperを選択
- IAM users and roles:上記で作成した
データレイク(S3 Bucket)への権限付与を以下の手順で実施します。
IAMロールにも手順10でS3 Bucketへの権限を付与していますが、こちらの手順も必要です。
Permissions下のData locations>Grant- 以下を入力(指定がないものはデフォルト) > 最後に
Grant- IAM users and roles:上記で作成した
IAMロール - Storage locations:データレイクの
S3 Bucketを選択
- IAM users and roles:上記で作成した
(補足) 各手順で設定したアクセス権限は以下の用途です。
IAMロールへの権限付与:データカタログを介さないS3アクセスに必要 ※今回だとCrawlerがファイルのメタデータを取得するときに必要- データベースへの権限付与:データカタログのデータベースアクセスに必要 ※今回だと
Crawlerがファイルのメタデータを登録するときに必要 - データレイクへの権限付与:S3のデータに向いたデータカタログを登録するときに必要 ※今回だと
Crawlerがファイルのメタデータを登録するときに必要
ここまで長かったですが、準備が整ったのでGlueのCrawlerを作成し、実行します。
Glueに移動 >クローラ>クローラの追加- 以下を入力(指定がないものはデフォルト) > 最後に
完了- クローラの名前:任意の名称
- Crawler source type :
Data stores - データストアの選択:
S3 - インクルードパス:フォルダマークを押して、
データレイク保存で作成したtitanicフォルダ - IAM ロールの選択:
既存のIAMロールを選択 - IAMロール:上記で作成した
IAMロール - データベース:上記で作成したデータベース
- 作成した
Crawlerを選択 >クローラの実行
完了した後にテーブルへ移動すると、自動的にtitanicテーブルが追加されていることを確認できます。これがtitanic.csvのメタデータになります。
さらに中身を見てみるとデータの場所や、下にスクロールすると以下のようにカラムの情報が自動的に取得されるところも確認できます。
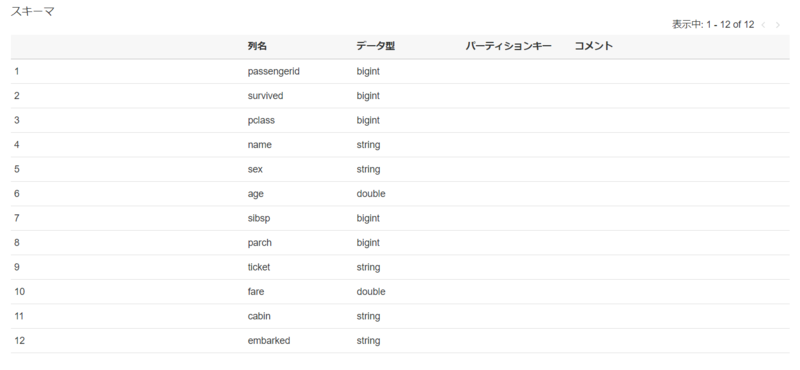
ここまででメタデータの自動取得とデータカタログへの登録は完了です!
データカタログを介してファイルの中身にアクセスする
データへのアクセスができるか、Athenaで確認してみます。
Athenaはサーバ不要でS3内のデータにクエリを投げられるサービスです。
クエリを投げる対象のファイルはGlueのデータカタログにメタデータが登録されている必要がありますが、ここまでの手順で登録が完了しているのですぐに使い始めることができます。
Athenaへ移動データベースに設定したデータベースを選択して、テーブルにtitanicテーブルが表示されることを確認エディタで以下を入力して
実行SELECT * FROM titanic limit 10;クエリの保存先に関するエラーが出たら、こちらを参考にしてクエリの出力先のS3を別途作成・設定
実行がうまくいくと以下のようにデータの中身が表示される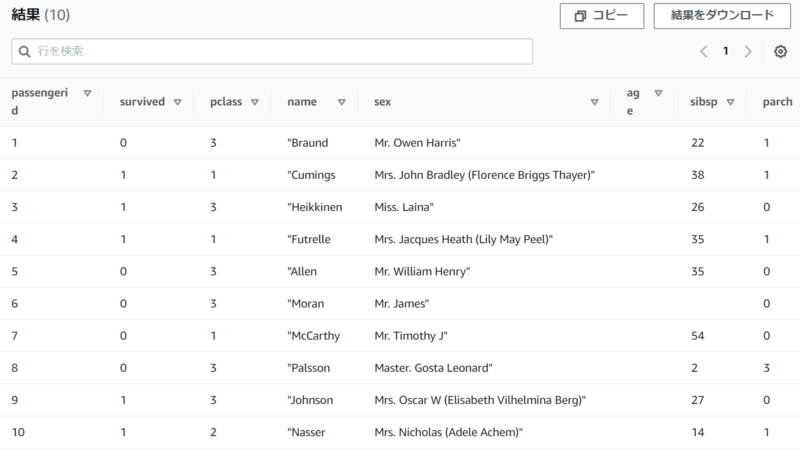
Athenaを使い、データカタログを用いたデータアクセスをすることが確認できました!
特にDB等に保存しているわけではないファイルにクエリを投げられるのは便利で、S3に置いてあるファイルに対してちょっとした分析をしたいときなどに手軽に使えます。
今回は単純なSELECT *でしたが、複雑なクエリを投げて分析することも可能です。
終わりに
今回は、AWSのLake Formationでのデータレイク登録からデータアクセスまでを試してみました。
ご紹介したのはあくまで一例で、Lake FormationやそのベースとなっているGlueでできることはもっと多くのことがあるので、興味のある方は使い込んでみてください!
AWSを利用してデータレイクを構築するというユースケースは今後増えてくると思いますが、まだ調べてもサンプルケースが出てこない場合が多かったりします。 何か例を探している方がいましたら、この記事が参考になれば幸いです。
ご覧いただきありがとうございました! それでは、明日の記事もお楽しみに!