
こんにちは。なんの因果かNTTコミュニケーションズのエバンジェリストをやっている西塚です。
この記事は、NTT Communications Advent Calendar 2021 22日目の記事です。
5分でわかる「Trino」
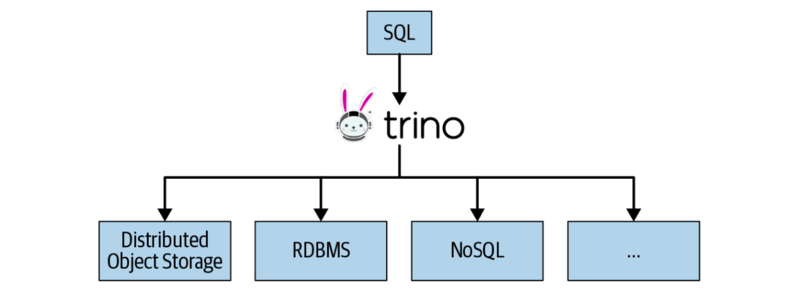
「Trino」は、異なるデータソースに対しても高速でインタラクティブに分析ができる高性能分散SQLエンジンです。 以下の特徴を持っており、ビッグデータ分析を支える重要なOSS(オープンソースソフトウェア)の1つです。
- SQL-on-Anything: Hadoopだけでなく従来のRDBMS(リレーショナルデータベース)やNoSQLまで、標準SQL(ANSI SQL)に準拠したアクセスをワンストップに提供
- 並列処理でビッグデータに対して容易にスケールアップ
- しかも高速(hiveの数十倍)
Netflix, LinkedIn, Salesforce, Shopify, LINEなど世界中の企業のデータサイエンスチームに使われていますが、日本語での情報はまだ少ないです。
今日のブログエントリは、「Trino」の概要を5分程度で紹介し、「Trino」について日本語で検索した時に一番に表示されるサイトを狙っていきます。
知っておきたいTrinoとPrestoの関係
「Trino」はかつて「Presto」と呼ばれていました。 歴史を紐解いて関係を整理しておきましょう。
Prestoは、2012年にFacebook内で開発されました。 もともとは、 300PBのHiveデータに対するクエリが遅かったことを解決するためのプロジェクトだったと言います。2013年に、Apache Licenceの元、OSS化されました。 この系列のPrestoをPrestoDBと呼びます。
2018年に、Prestoのコアの開発者がFacebookを去り("PrestoのOSS開発に集中するため"といいます)、2019年にPresto Software Foundationを立ち上げました。 オープンソースコミュニティとしてPrestoDBよりも多様なユースケースを取り入れるためにPrestoSQLの系列が作られました。 そして、2020年12月、PrestoSQLは「Trino」と名称を変更しました。
PrestoSQLで"Presto"の名称が使えなくなった経緯についての詳細はこちら(英語)に記載されています。
github上には、prestodbとtrinoの両方のリポジトリがありますが、2019年を境にコア開発者がTrinoでの活動に移っています。 「Trino(Presto)」と併記する場合もありますが、今後は「Trino」が定着していくと思います。
Presto Software Foundationは、Trino Software Foundationに名称が変わり、かわいいマスコットキャラクターも産まれました。

Commander Bun Bun です。
NTT ComのTrinoへの貢献
私の所属するデータ分析専門部隊では、NTTコミュニケーションズをデータドリブン企業に変革するために、社内の各種システムからデータを一元的に収集するデータプラットフォームを構築し、その上でデータサイエンティストたちがブレーンとして分析に取り組んでいます。

Trinoは、データプラットフォーム(Hadoopを中心に作られています)と、様々な分析ツールを繋ぐ重要な役割を担っています。
企業ユーザとしてTrinoの公式Webサイトにもロゴを載せています。 また、チームメンバーがTrinoのOSS contributeをしています。

Trinoのユースケース
Trinoの特徴を活かす
冒頭でSQL-on-Anythingと説明したように、Trinoは様々なデータソースを扱うことができます。
例えば、
- hive上の巨大なテーブルの特定のカラムに対して、MySQL上の属性データを結合して情報を付加する
- BigQueryとオンプレのデータを結合して分析する
といった分析者がやりたいことがSQL文で簡単にできてしまいます。
全てのデータソースに対して透過的に1つのSQLアクセスを提供してくれるため、BIツールによるダッシュボード作成から、高度な機械学習のための複雑なクエリまで幅広いニーズに対応します。
この特徴から、データ仮想化製品と比較されることがありますが、重要な点として、Trino単体ではデータストレージとしての機能を持ちません。ですので従来のRDBを置き換えるものではありません。データの書き出しについては、hiveを利用できるため後述します。
「分散」の名称からわかる通り、並列処理のworkerを増やすことによって性能がスケールアウトしますが、データソースから取得してきたデータをworkerのオンメモリに展開してJOIN等の処理をするアーキテクチャになっているので、メモリ容量を超えるとクエリは失敗します。その代わり、オンメモリ処理のため超高速です。 そうです、Trinoを使う時はメモリをリッチに使いましょう。また、メモリに関する各種パラメータのチューニングが重要です。
- Trinoによる分散処理のアーキテクチャの概要

NTT Comでの活用事例
我々のチームでは2017年頃からすでにTrino(当時はPresto)を使っておりました。
事例1: pmacct->kafka->presto->re:dashを使った高速なflow解析
2017年にJANOG39で発表した内容です。 この例では、ルータ等ネットワーク機器からリアルタイムに生成されるトラフィック情報をkafkaに入れてPrestoで参照しています。可視化部分(BIツール)としてはre:dashを使っていました。
事例2: データ分析コンペ
今年の夏、インターネットトラフィックを予測する社内コンペを開催しました。 参加者に Jupyter labベースのkaggleライクなコンペ環境を用意し、Python/Rを使ってインターネットのトラフィックデータを分析できるようにしました。 データセットはHadoop上に置き、Trinoを使って自由に参加者がSQLを叩いてアクセスできるようにしました。これにより参加者全員がTrinoでの高速クエリのメリットを享受することができました。
当然ですが扱うデータは通信系のデータだけではありません。他にもSalesforceのデータを取得し、企業情報を付加して分析するようなことも行っています。 また、IBM Netezzaにデータを蓄積している社内システムがあったため、Trinoからデータ参照するためにNetezza Connectorを開発したりしています。
Trino、認証/認可も大丈夫だってよ
ここまでの説明で、認証/認可の機能が備わっているのか気になった方もいるかと思います。ご安心ください。
TrinoとApache Rangerを組み合わせて利用することにより、Trinoから各データソースへのクエリにおいて、AzureADなどのIdP(IDプロバイダー)と連携したユーザ認証を行い、スキーマ/テーブル/カラム単位でアクセスを制御できます。 例えば機微なデータを特定の個人やグループにのみ公開するなどのポリシーをRangerのGUIで管理できます。
TrinoとApache Rangerの連携部分は我々のチームが精力的にコミュニティに貢献しています。
- Trino+Rangerによるデータへのアクセスの制御

広がるTrinoの活用領域: Trino for ETL
これからは、TrinoをデータのETLにも利用したいと考えています。
ETLとは、Extract/Transform/Loadの頭文字をとったデータ前処理のことです。
Trinoは INSERT INTO ... SELECT構文により、データをHDFSやS3などに書き出すことができます。
これにより、シンプルにRDBなどのデータソースから取得(Extract)したデータを加工(Transform)してhiveに書き込む(Load)ことができます。
RDBを利用しているシステムからhdfsにデータを移動してhiveにデータを読み込ませる(Data Ingestion)にはいくつもの方法があります。Apache SqoopやEmbulkも試しましたが、パーティショニングに関する機能が不足していたり、データ加工に関わるモデル化やコードのメンテナンスが困難でした。 対してTrinoを使えば、データ加工・モデル化と分析の両方が同時に賄えるため大きなメリットになります。Apache Airflow(ワークフロー管理)やdbt(data build tool)との相性も抜群です。 Salesforce社のEngineer blogでもTrino for ETLの利点についての記事がでており、注目されている領域です。
Trino 利用イメージ
Trino CLI
$ trino --server https://<trino hostname> --user <ID> --password
Password: (パスワードを入力)
trino> show catalogs;
Catalog
-------------------------------
hive
mysql
trino> select * from hive.table1 join mysql.table2 on hive.table1.column1 = mysql.table2.column2 limit 10;
python
import trino cur = trino.dbapi.connect( host='<trino hostname>', port=443, http_scheme='https', verify=False, auth=trino.auth.BasicAuthentication('<ID>', '<PW>'), user='<ID>', ).cursor() cur.execute('show catalogs') print(cur.fetchall())
上記はBasic認証の例ですが、我々はJWTを用いた認証を使っています。
Tableau
サーバ接続でPrestoを指定することで利用可能です。 現時点(2021/12)でTrinoとPrestoのドライバは共通です。

最後に
Trinoは、データを武器にしているデータドリブン企業に活発に利用されています。大量のデータが毎日生まれるサービスにおいてデータに基づいた仮説検証を行うためには、分析者に使いやすいデータプラットフォームが欠かせません。
我々のデータプラットフォームでは、オンプレのkubernetes基盤上にTrinoを構築し、日々の分析で活用しています(我々はオンプレですが、Trino自体はクラウドでも場所は選びません)。
OSS開発も活発で、海外企業での利用が広がっています。日本でもTrinoの導入事例が増えることを期待してやみません。
Trino利用開始に役立つリンク集
- Trino: The Definitive Guide
- 概要からアーキテクチャまで、このオライリー本1冊を読めば間違いない(英語版のみ)。
- Trino Documentation
- 対応している型やSQL文のシンタックスがわからなくなった時に参照します。公式のドキュメントが充実している点もTrinoの素晴らしい点です。
- github/trino
- 公式のリポジトリです。バグらしきものを見つけたときに探します。
- Trino Forum
- Q&Aのフォーラムもあります。
- Trino Slack
- ユーザから開発者まで集うslackです。困ったことがあれば、呟けば直ぐに他ユーザや開発者自身が助けてくれます。