
この記事は、NTTコミュニケーションズ Advent Calendar 2023 11日目の記事です。
はじめに
こんにちは。コミュニケーション&アプリケーションサービス部の石井です。 今年はAI分野においては LLM1 の話題で持ちきりの一年でしたが、そんな LLM とは全く関係のないグラフニューラルネットワーク(以下、GNN)の説明性に関する手法である GNNExplainer を題材に扱っていこうと思います。
GNN2 とはグラフで表現された構造化データを深層学習で扱うためのニューラルネットワーク手法の総称です。グラフデータはさまざまな事象を表現できる可能性を秘めていて、GNN の予測結果を解釈できれば、人との関係性把握やマーケティングへの応用など幅広い活用が期待できると思っています。GNN に興味がない方もこんな技術があるのかと深く考えずに読んでもらえればと思います。
本記事で扱う内容
本記事では以下の内容について扱います。
- 説明可能な AI(XAI)について
- GNNExplainer とは
- GNNExplainer の実践
説明可能な AI(XAI)や GNNExplainer に関しての簡単な概要説明をした後に、サンプルデータを用いて構築したモデルに GNNExplainer を当てはめてみた結果についてコードと併せて解説をしていきます。説明可能なAI(XAI)や GNNExplainer の概要についてはすでに知っているという方は記事後半の「GNNExplainer の実践」まで飛ばして見てください。
説明可能なAI(XAI)について
機械学習モデルにおける意思決定を行う際に、そのモデルが下した判断を人間が理解できるように説明することを目的とした技術の総称を「説明可能なAI(XAI)3」と言います。昨今の技術発展は、ディープラーニングを皮切りにより高い予測精度を達成している一方で、予測における説明可能性というのは複雑化する関数近似によって犠牲になっています。つまり、予測精度と説明可能性の間にはトレードオフの関係があり、昨今では機械学習モデルを人間が理解することは極めて難しくなっています。
では、なぜ説明可能なAI(XAI)が大事なのかというと、それは現実世界やビジネス領域では意思決定における透明性や不偏性が要求されるためです。例えば、医療分野である人の病気の発症リスクを予測する判定を機械学習モデルで行い、予測結果として発症リスクが高いとの判断をした場合には、その結果と根拠理由を示さなければ納得が得られず信用を損なう可能性があります。
このように説明可能性は現実世界では極めて重要な要素の1つとなっており、一般的に人間は自分が解釈したり理解できないものを採用しない傾向があるため、機械学習モデルの説明可能性はあらゆるシーンにおいて無視できないものとなっています。そのため、 GNN においても同様にモデルの説明可能性は要求されることから、 GNN における説明性に焦点を当てた技術が開発されてきています。
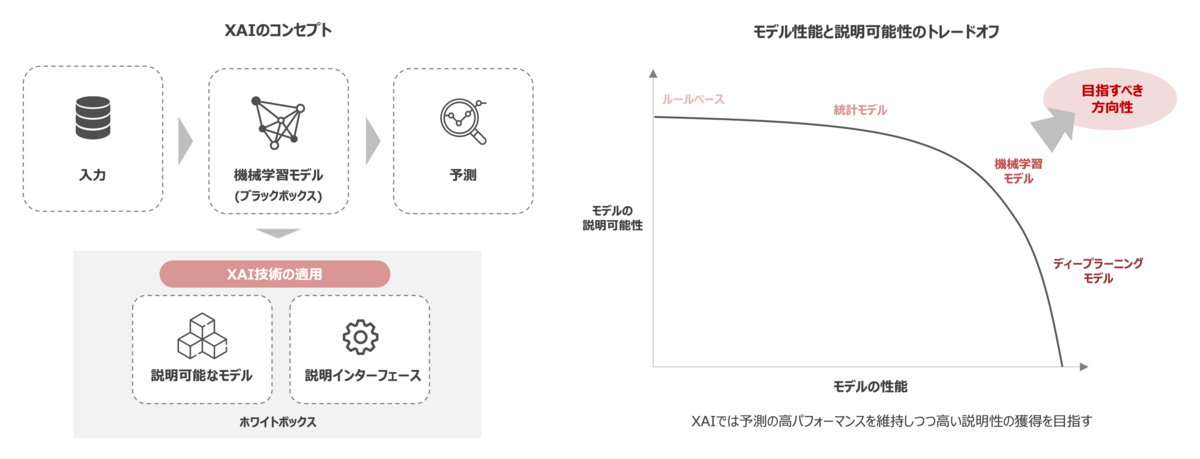
GNNExplainer とは
GNNExplainer4 とは、2019年に NeurIPS5 で採択された論文である「GNNExplainer: Generating Explanations for Graph Neural Networks」の中で提案された GNN の説明性に関する手法です。
GNNExplainer は学習済みの GNN モデルと予測結果を入力として与えると、出力として予測に影響を与えたノードの特徴量と予測を説明するサブグラフを返すことで予測結果を説明することを可能にします。 また、model-agnostic な手法であるため、特定のモデルに依存することなく扱うことができます。加えて、GNN で扱う問題設定にはいくつかの種類がありますが、ノード分類、リンク予測、グラフ分類など一般的なグラフの問題設定に対応しているため適用範囲が広いことが言えます。 論文内では、実世界のデータセットを用いて、GNNExplainer の説明性における妥当性を定量分析と定性分析の両側面から評価してどれくらい有効であるかを述べています。興味がある方は、論文を参照して詳しい実験内容について見てください。
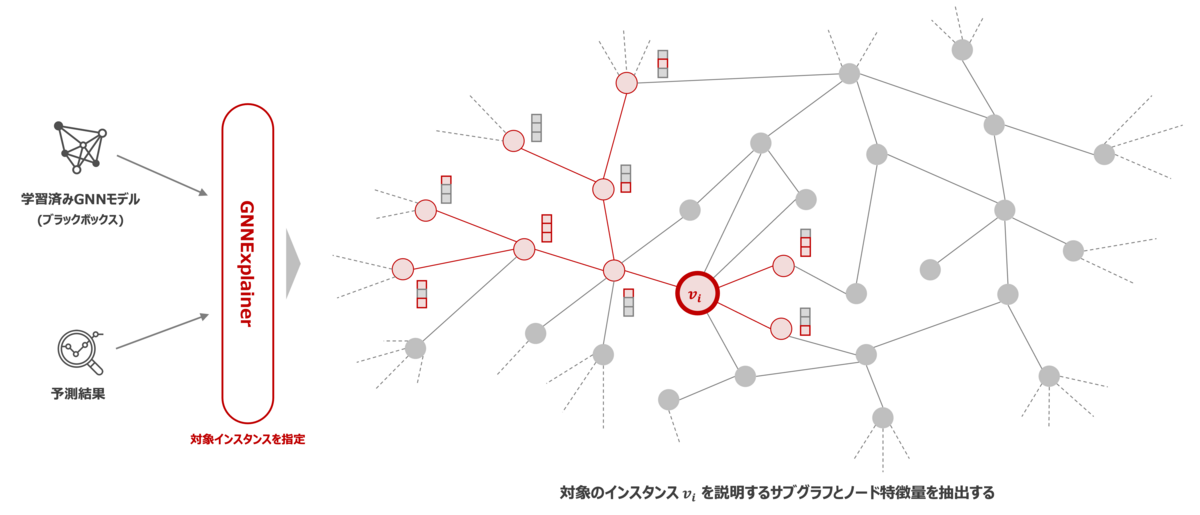
GNNExplainer のアルゴリズムは、ノード が与えられた際に予測根拠をよく説明するようなサブグラフ
とノードの特徴量
を特定することを目指していきます。そして、ここで述べているよく説明ができているサブグラフ
を、当該アルゴリズムでは相互情報量
を最大化するような
と定義しています。
上記の定式は、エントロピー と条件付きエントロピー
の差分を最大化することを意味しており、学習済みの GNN では予測確率は固定であることからエントロピー
の項は一定となるため、条件付きエントロピー
の項を最小化するようなサブグラフ
を探索していくことを実質的に行います。
もう少し簡単に説明すると、全体のグラフから対象ノード
とは別のノードである
を除外した際の予測確率
の増減を見て、予測確率が大きく減少する場合はノード
は予測に良い影響を与えると判断して、予測に大きく寄与するエッジのみを選択していくことで有効なサブグラフの獲得を目指していきます。
実際には、このサブグラフの選定の際には全探索すると計算コストが膨大となるため、直接最適化問題を解くことはせずに条件付きエントロピーの式をイェンセンの不等式や平均場近似を用いてエッジの存在有無を示す期待値に変換して、サブグラフの隣接行列を計算して求めていくことで実現します。この辺りの詳細な説明については元の論文を参照ください。
GNNExplainer の使い方
GNNExplainer は PyTorch Geometric6 内のモジュールとしてすでに実装済です。そのため、当該フレームワークを利用することで簡単に GNNExplainer の処理を再現できます。 PyTorch Geometric ではバージョン2.2から説明性のフレームワークとして explain モジュールを提供しており、さまざまなアルゴリズムを用いて GNN の説明性生成や可視化のための柔軟なインターフェースを提供しています。
PyTorch Geometric では GNNExplainer 以外のアルゴリズムとして、CaptumExplainer や PGExplainer7 、 AttentionExplainer8 などのアルゴリズムが用意されており利用することが可能です。以下にそれぞれの特徴をまとめます。

GNNExplainer はノードの重要特徴量だけでなくグラフトポロジに基づいた重要なサブグラフを同時に明らかにする GNN に対して有効な説明手法を提案した最初の技術です。単一のインスタンス(予測対象であるグラフやノードの単位)に対して、独立した説明性に関わる特徴量やサブグラフを生成するため、その説明性を対象としていない別のインスタンスに一般化することが困難であるという課題があります。しかし、複雑な GNN の理解に際して解釈を一助することは間違いないため、適切な状況下での利用や他の手法と組み合わせて解釈を補うことが可能です。
CaptumExplainer は Integrated Gradients9 と呼ばれる勾配積分法の公理に基づいて各次元における特徴量の寄与度を算出する手法で、算出過程がモデル実装に依存しないため、model-agnostic な手法に分類されています。また、Integrated Gradients はあらゆる微分可能モデルへの適用が可能なため、GNN に限らずさまざまなモデルで説明性の技術として適用されています。一方で、Integrated Gradients はグラフに特化した手法ではないことから、ノード間などの相互作用などが考慮されないため、説明性についても当然に相互作用が考慮されない形で出力されるといった課題があります。
PGExplainer は GNNExplainer で課題となる単一インスタンスに制限される課題を、説明性の生成過程をニューラルネットワークよりパラメータ化することで、一連のインスタンスの予測をまとめてモデル全体としての説明性を取得することを可能にした手法です。こちらも model-agnostic な手法となっています。また、一連のインスタンスを予測する際に GNNExplainer では新しいインスタンスに対して再学習を要するが、PGExplainer では一度学習した説明器のモデルを帰納的な設定のみで新しいインスタンスを説明可能となることから、再学習を必要とせず大規模なデータセットに対しても手法適用が可能とされています。
ちなみに余談にはなりますが、PyTorch Geometric と同様に GNN を扱うフレームワークである DGL10 でもバージョン 1.0.0 以降で GNNExplainer 等をサポートしています。どちらのフレームワークでも GNNExplainer を扱うことができるため、ご自身ですでに使い慣れているフレームワークに合わせて選択されると良いかと思います。
GNNExplainer の実践
ここからは実際にサンプルデータを用いて、構築した GNN モデルに GNNExplainer を適用して予測を解釈することを試していこうと思います。
実行環境・インストール
まずは実行環境です。 今回は以下の内容で PyTorch Geometric が扱える環境を用意しました。
# cat /etc/os-release NAME="CentOS Linux" VERSION="7 (Core)" ID="centos" ID_LIKE="rhel fedora" # pip list | egrep "(torch)" torch 2.1.1 torch-cluster 1.6.3+pt21cpu torch_geometric 2.4.0 torch-scatter 2.1.2+pt21cpu torch-sparse 0.6.18+pt21cpu torch-spline-conv 1.2.2+pt21cpu torchaudio 2.1.1 torchvision 0.16.1
PyTorch や PyTorch Geometric のインストールは公式サイトに分かりやすく記載していますのでそちらを参照してコマンドを実行してみてください。
データ準備
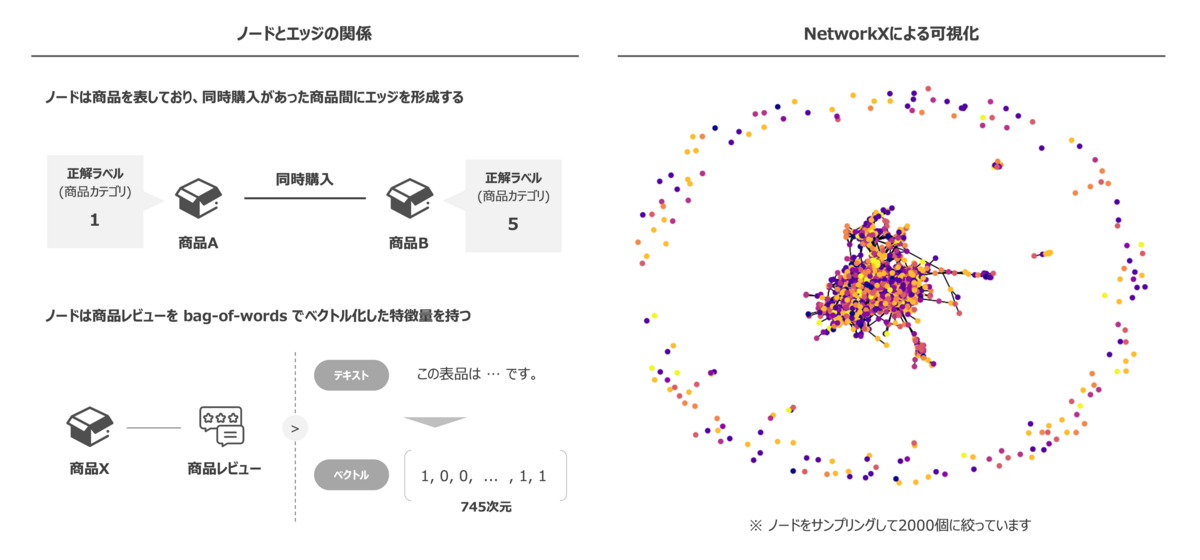
今回はベンチマークとしても利用されているオープンデータである Amazon Dataset 11 を利用します。 このデータセットはノードが商品を示し、エッジは共同購入されたことを表したグラフデータです。 ノード特徴量は商品レビューを bag-of-words12 によりベクトル変換したデータとなっており、745次元の特徴量を持っています。また、ノードのターゲットラベルは商品カテゴリを示しており、8つの商品カテゴリのいずれかに該当します。
| 項目 | 内容 |
|---|---|
| ノード数 | 7,650 |
| エッジ数 | 238,162 |
| ノード特徴量(次元数) | 745 |
| クラス数 | 8 |
文章では少し分かりづらい部分もあるかと思いますので、ノードとエッジの関係性を簡易に示した図と実際のデータを NetworkX13 にて可視化したグラフを載せておきます。
問題設定
問題設定はシンプルにマルチクラスのノード分類問題を考えます。以下に概要を示します。
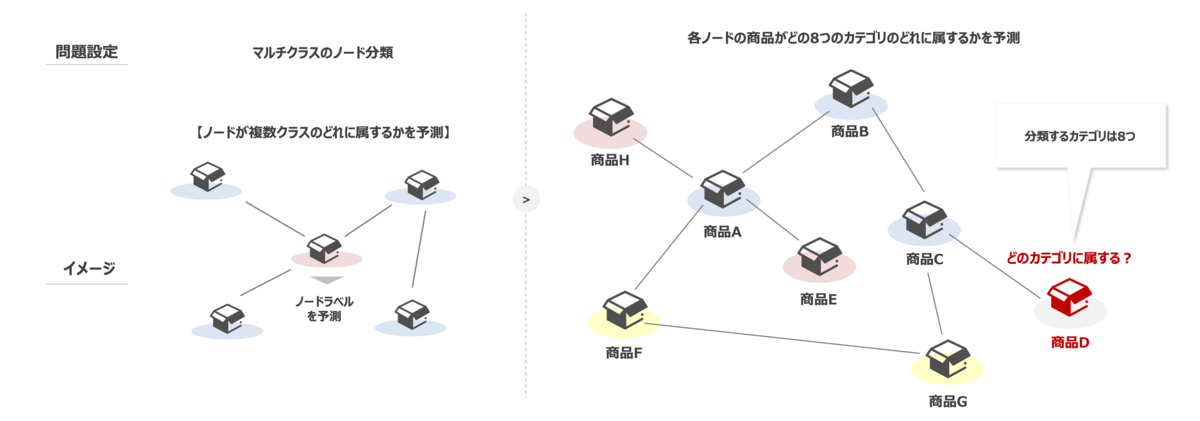
予測対象となる商品ノードが8つの商品カテゴリのどれに当てはまるのかを予測する GNN モデルを構築することを目指します。 加えて、今回は説明性を獲得したいので構築した GNN モデルに対して、GNNExplainer を適用してその得られた説明性について確認していこうと思います。
モデル解釈
本題のモデル構築と GNNExplainer による説明性の獲得についてコードを載せながら述べていきます。まずは、GNN モデルを作成します。
import random from math import sqrt from collections import Counter import networkx as nx import torch import torch.nn as nn import torch.nn.functional as F import torch_geometric.transforms as T from torch_geometric.explain import Explainer, GNNExplainer from torch_geometric.explain.metric import fidelity from torch_geometric.explain.metric import groundtruth_metrics from torch_geometric.nn import GCNConv from torch_geometric.utils import to_networkx from torch_geometric.datasets import Amazon # パラメータ指定 DIM = 16 # データ読み込み dataset = Amazon(root='../data', name='Photo') data = dataset[0] # データ分割(学習データ:テストデータ:バリデーションデータ=7:2:1) split = T.RandomNodeSplit(num_val=0.1, num_test=0.2) data = split(data) # モデル定義 class Model(nn.Module): def __init__(self, num_features, dim=16, num_classes=8): super().__init__() self.conv1 = GCNConv(dataset.num_node_features, dim) self.conv2 = GCNConv(dim, num_classes) def forward(self, x, edge_index): x = self.conv1(x, edge_index) x = F.relu(x) out = self.conv2(x, edge_index) return F.log_softmax(out, dim=1) def train(model, data, optimizer, criterion, epochs=100): for epoch in range(1, epochs + 1): model.train() optimizer.zero_grad() out = model(data.x, data.edge_index) loss = criterion(out[data.train_mask], data.y[data.train_mask]) loss.backward() optimizer.step() pred = out.argmax(dim=1) acc_train = int((pred[data.train_mask] == data.y[data.train_mask]).sum()) / int(data.train_mask.sum()) acc_val = eval_acc(model, data, data.val_mask) if epoch % 10 == 0: print(f'Epoch: {epoch:03d}, Train Loss: {loss:.3f}, Train Loss: {acc_train:.3f} ,Val Acc: {acc_val:.3f}') return model def eval_acc(model, data, mask): model.eval() pred = model(data.x, data.edge_index).argmax(dim=1) correct = (pred[mask] == data.y[mask]).sum() acc = int(correct) / int(mask.sum()) return acc # パラメータセット device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') data = data.to(device) model = Model(dataset.num_node_features, dim=DIM, num_classes=dataset.num_classes).to(device) optimizer = torch.optim.Adam(model.parameters(), lr=0.005, weight_decay=5e-3) criterion = nn.CrossEntropyLoss() # モデル学習とテストデータによる精度評価 model_gnn = train(model, data, optimizer, criterion, 300) acc_test = eval_acc(model_gnn, data, data.test_mask) print(f'Test Acc: {acc_test:.3f}')
上記のコードでは Amazon Dataset のデータ読み込みからモデル学習、評価までを実装しています。
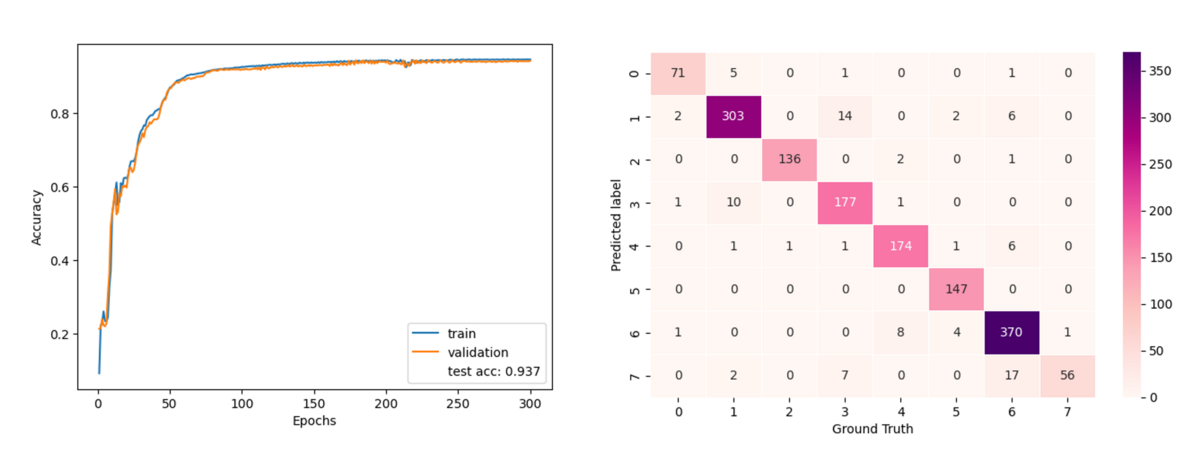
学習結果はテストデータでの accuracy が 93.7% で正しく学習できている様子が伺えます。なかなかの高精度ですね。各カテゴリ別の正答一致数を混同行列より確認してみても、ほとんどのカテゴリで正しく予測が出来ていることが見てわかります。
さて、ここまでで構築された GNN モデルを用いて、いよいよ本題の GNNExplainer の実装に移っていきます。
先ほど学習したモデル(model_gnn)を Explainer クラスのパラメータとして渡して説明性を取得していきます。
# サブグラフを可視化する関数 def viz_subgraph(edge_index, edge_weight, target, node_index): target_color = '#FFFFFF' color_list = ['#FCFFA4', '#F7E425', '#FEBA2C', '#F89540', '#F2844B', '#E16462', '#CC4778', '#B12A90'] if edge_weight is not None: edge_weight = edge_weight - edge_weight.min() edge_weight = edge_weight / edge_weight.max() if edge_weight is not None: mask = edge_weight > 1e-7 edge_index = edge_index[:, mask] edge_weight = edge_weight[mask] if edge_weight is None: edge_weight = torch.ones(edge_index.size(1)) subgraph_idx = np.unique(explanation.edge_index[:, mask][0]) target_idx = np.where(subgraph_idx == node_index)[0] target = [color_list[idx] for idx in target[subgraph_idx]] target[target_idx[0]] = target_color g = nx.DiGraph() node_size = 800 for node in edge_index.view(-1).unique().tolist(): g.add_node(node) for (src, dst), w in zip(edge_index.t().tolist(), edge_weight.tolist()): g.add_edge(src, dst, alpha=w) plt.figure(figsize=(15,8)) ax = plt.gca() pos = nx.spring_layout(g) for src, dst, data in g.edges(data=True): ax.annotate( '', xy=pos[src], xytext=pos[dst], arrowprops=dict( arrowstyle="->", alpha=data['alpha'], shrinkA=sqrt(node_size) / 2.0, shrinkB=sqrt(node_size) / 2.0, connectionstyle="arc3,rad=0.1", ), ) nodes = nx.draw_networkx_nodes(g, pos, node_size=node_size, node_color=target, margins=0.1,) nodes.set_edgecolor('black') nx.draw_networkx_labels(g, pos, font_size=10) plt.show() plt.close() # explainerインスタンスの定義 explainer = Explainer( model=model_gnn, algorithm=GNNExplainer(epochs=200), explanation_type='model', node_mask_type='attributes', edge_mask_type='object', model_config=dict( mode='multiclass_classification', task_level='node', return_type='log_probs', ), ) # 説明性に関わるノード指定と演算処理 node_index = 700 explanation = explainer(data.x, data.edge_index, index=node_index) # ノード特徴量における重要変数の可視化 explanation.visualize_feature_importance("feature_importance.png",feat_labels=None, top_k=10) # 指定したノードに関係するサブグラフ可視化 viz_subgraph(explanation.edge_index, explanation.edge_mask, explanation.target, node_index)
初めに定義している viz_subgraph 関数は GNNExplainer より得られた結果のエッジ情報及びマスク情報を元にサブグラフを可視化する処理を定義しています。
次いで、Explainer クラスを用いてインスタンスを作成することで、ノードの重要変数とサブグラフ取得などの説明性の獲得を行なっています。この Explainer クラスは全ての説明性に関わるパラメータを扱うようにデザインされたクラスで、フレームワーク利用者はこのクラスのパラメータを変更することで共通処理のままで複数のアルゴリズムを操作すること可能にしています。今回は GNNExplainer を利用するため、algorithm の GNNExplainer を指定して、model_config に GNN モデルのタスクに合わせて適切なパラメータを設定しています。
Explainer クラスのインスタンスを作成した後は、入力データと説明性の対象とするインスタンス(今回はノード)のインデックス番号を与えることで予測における説明性情報を取得します。インスタンスのインデックス番号を適当に 700 とした場合の結果は以下のようになりました。
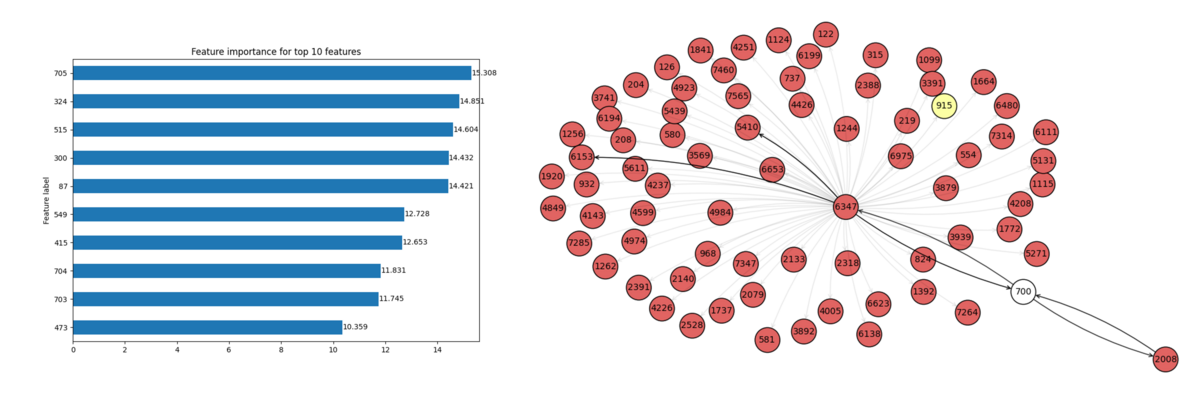
まずは、ノードにおける重要変数(Feature Importance)ですが、重要度が高い方から top_k で指定した数だけ特徴量を棒グラフで可視化しています。今回のデータセットではノード特徴量は bag-of-words によってベクトル化した情報のため、どのようなワードが重要であるかを当該データから判別はできませんが、意味のあるラベル付きの情報であった場合は何が予測に効いているのかを把握するのに有効な方法だと思います。
最後に、ノードインデックスが 700 の予測に寄与しているサブグラフを可視化して見てみると、700 の商品ノード(白い丸)には 2008 と 6347 の商品ノードが予測に密接に関係しているという結果が見られます。また、予測に寄与しているサブグラフの商品ノードは、ほとんどが同一カテゴリ(赤丸のノード)であることから、同一カテゴリの商品と一緒に購買されていていることが分かります。特に 2008 は単独で同時に購買されているが、6347 はその他の関連する商品と同時に購買されていることが言えそうです。
GNNExplainer では特定のノードに焦点を当てているため、グラフデータ全体としての説明性を明言することは難しいですが、このように単一のノードを起点にした説明性の理解から大まかな全体傾向を掴むなどの活用に期待はできそうですね。
終わりに
今回は GNNExplainer の概要とモデルに対しての適用方法について紹介しました。 GNN によってグラフ構造をニューラルネットワークで扱えるようになりましたが、グラフ構造自体の複雑性も相まって説明性・解釈性は非常に高いわけではありません。 そのため、今回紹介した GNNExplainer などによる GNN の予測根拠の説明性向上は、追加特徴量の検討や予測根拠によるマーケティング活用など幅広く応用が効くものになるかと思います。 まだまだ、発展途上の分野ではありますが、今後もXAI領域の発展には期待したいですね。
それでは、明日の記事もお楽しみに!
- Large Language Model の略で、極めて大量のデータと深層学習技術によって構築された言語モデルです。↩
- こちらで GNN についての解説が詳しく記載されています。↩
- https://www.darpa.mil/program/explainable-artificial-intelligence↩
- https://arxiv.org/pdf/1903.03894.pdf↩
- https://nips.cc/↩
- https://pytorch-geometric.readthedocs.io/en/latest/↩
- https://arxiv.org/pdf/2011.04573.pdf↩
- Attention ベースの GNN により Attention 係数をエッジの説明に応用した解釈性の手法です。Attention 機構を扱った特定のアルゴリズムで学習したGNNモデルのみが利用可能となります。↩
- https://arxiv.org/pdf/1703.01365.pdf↩
- https://www.dgl.ai/↩
- https://arxiv.org/pdf/1811.05868.pdf↩
- 文章中に出現する単語の順番は考慮せずに、単語の出現回数のみからベクトルを表現する手法を指します。↩
- https://networkx.org/↩