
はじめに
こんにちは、イノベーションセンターの鈴ヶ嶺・齋藤です。本記事は前回の記事の後編となっており、引き続きICCV2021の論文を紹介します。
論文紹介
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(ORAL PAPER & Marr Prize Best Paper)
Swin Transformerとは
この論文では、NLPで汎用バックボーンとして活用されているTransformer1の適用範囲を拡大して、コンピュータビジョンにおいても汎用バックボーンとして使用可能とするVision Transformer(ViT)2ベースのSwin Transformerを新たに提案しています。
これまでの映像分野におけるViTの課題は、主に2つあります。まず1つ目がスケールの違いです。単語トークンなどの固定化されたスケールのものとは異なり、映像ではスケールが大幅に変化する可能性があります。2つ目の違いはSelf-Attentionの計算量は画像サイズの二乗で増加し、大きな計算量が必要となる点です。これらの課題に対して、階層的な特徴マップにより様々なスケールの画像に対応し、かつ計算量を画像サイズに対して線形の計算量に削減する手法を提案しています。
Swin Transformerは次のようなアーキテクチャで構成されています。

まず初めに、Patch Partitionでは、以下の従来のViTと同様に画像をパッチとして分割して線形写像します。

その後の処理は、後述するPatch MergingとSwin Tranformer Blockの2つで構成されるStageの繰り返しとなっています。
Patch Merging

Patch Mergingでは隣接されたそれぞれのチャンネル数Cの2x2のパッチを連結して、チャンネル数4Cの1つの特徴に変換して線形射影しています。これにより大域的な特徴抽出を維持しつつ、ネットワークが深くなるにつれトークンの数を減らすことでSelf-Attentionの計算量の増加を線形に削減する貢献をしています。
Swin Transformer Block

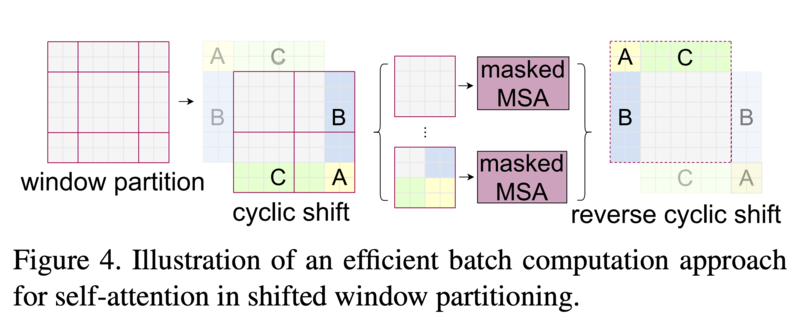
アーキテクチャの図3(b)から分かるように、Swin Transformer Blockでは通常のMulti-head Self-Attention(MSA)をWindowsベースのW-MSAとShifted WindowsベースのSW-MSAに置き換えています。W-MSAはパッチをWindowごとに分割しSelf-Attentionを計算を効率化させることで計算量を二乗から線形に削減しています。しかしW-MSAのみで構成するとWindow間の接続がないため、そのモデリングの表現に限界があります。そこで効率的な計算を維持しつつ、Window間の接続を与えるため、上記の画像のようにWindowをシフトさせた層のSW-MSAの2つで構成します。SW-MSAでは、上記の例のようにWindow数が4から9へと増加し計算コストも増加する課題があります。この課題に対して、次の画像のようにcyclic shifttという小さなWindowsを反対側に移動させてまとめることでWindows数を一定にする方法を提案しています。また、隣接していないパッチがWindow内にある場合はSelf-Attentionの計算時にはmask処理することで対応しています。
実験結果
ImageNet-1K3を学習させて比較した結果が次のようになっています。既存手法である通常のViT-B4と既存のViTベースのモデルでstate-of-the-artな手法であるDeiT-B5と計算量が同等にしたSwin-Bを比較しています。またSwin-T, Swin-S, Swin-Lはそれぞれの計算量が0.25倍, 0.5倍, 2倍に設定されています。

上記の画像から、同程度のモデルサイズ同士の精度(acc)を比較するとSwin-TはDeiT-Sを1.5%上回り、Swin-BはDeiT-Bを1.4%上回る結果であることが分かります。
次にCOCO6データセットを用いてObject DetectionとSegmentationの実験をしました。 box AP(Average Precision)とmask APのそれぞれのstate-of-the-artな手法であるCopy-paste7とDetectoRS8を比較しています。

上記の結果のtest-devにおいて提案手法のSwin-L(HTC++)は、box APについてはCopy-pasteを2.7上回る58.7、mask APについてはDetectoRSを2.6上回る51.1という結果であることが分かります。
実際に動作させた結果
MMDetectionが必要となるためget_started.mdを見てインストールしておきます。
まず、次のように推論用のinference.pyを用意します。
import sys import torch from mmdet.apis import init_detector, inference_detector, show_result_pyplot from mmcv import Config import mmcv # setup arg ## mmdetection config ## ex: 'configs/swin/mask_rcnn_swin_tiny_patch4_window7_mstrain_480-800_adamw_1x_coco.py' config_file = sys.argv[1] ## checkpoint file ## ex: 'checkpoints/mask_rcnn_swin_tiny_patch4_window7_1x.pth' checkpoint_file = sys.argv[2] ## input image path img = sys.argv[3] ## output image path out = sys.argv[4] # init model device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu') model = init_detector(config_file, checkpoint_file, device=device) # inference result = inference_detector(model, img) # save the results model.show_result(img, result, out_file=out)
以下が実際に動作させたものになります。
git clone --depth 1 https://github.com/SwinTransformer/Swin-Transformer-Object-Detection.git cd Swin-Transformer-Object-Detection # setup pretrain model mkdir checkpoints wget https://github.com/SwinTransformer/storage/releases/download/v1.0.3/mask_rcnn_swin_tiny_patch4_window7_1x.pth -P checkpoints # setup inference.py # vim inference.py # setup input data # cp /path/to/input_img.jpg . python inference.py \ configs/swin/mask_rcnn_swin_tiny_patch4_window7_mstrain_480-800_adamw_1x_coco.py \ checkpoints/mask_rcnn_swin_tiny_patch4_window7_1x.pth \ input_img.jpg \ output_img.jpg
街中を撮影した画像を入力して推定した結果が次のようになっています。


MMDetectionのフレームワーク上で実装されているため、簡単に人物や車のObject detectionやSegmentationのタスクについて処理可能であることが分かります。
所感
NLPから映像分野にTransformerの適用を拡大させるために、階層的な特徴マップを用いて線型の計算量に削減したこの提案手法は非常に有用であると思い紹介しました。今後、映像分野におけるViTのさらなる発展を期待しています。
GANcraft: Unsupervised 3D Neural Rendering of Minecraft Worlds(ORAL PAPER)
GANcraftとは
ポスターにセンスを感じてしまい、今回解説をすることにしました。 GANCraftでは、マインクラフトで作った世界をリアルな世界に変換しています。
前提としてマインクラフトは、視点を自由に動かすことができます。 そのため、リアルな画像に変換する場合、自由に動かせる視点に対して変換する必要があります。それにあたり重要になる関連研究として、NeRF-Wがあります。NeRF-Wとは、様々な画角、天候などのオクルージョンを含む画像など様々な条件で撮影された複数の画像から、新しい視点からの画像を合成する研究です。 NeRF-Wをそのまま適用して、この変換をすれば良さそうです。
しかし、今回の対象であるマインクラフトの画像に対して、複数の画角から撮影したリアルな画像の正解データを用意するのが難しいという問題点があります。 その問題を解決する手法としてGANCraft を提案しています。マインクラフトとそれに対するリアルな画像のペアとなる正解データがない場合、疑似的な正解データをGANで生成し、NeRF-Wを適用することでその問題を解決しています。提案手法は4つのベースライン手法と比較した実験において、全ての結果でその有効性を示していました。

モデルの説明

まず、マインクラフトの画像に対してセグメンテーションマスクをかけます。その後SPADE9によりマスクに基づくリアルな画像を生成します。次に、実画像を使う場合、Adversarial lossを用いてスタイル特徴を抽出するStyle encoderを行います。擬似的なGround Truth画像を使う場合、Adversarial loss、perceptual loss、L1、L2を組み合わせてStyle encoderを行い、スタイル特徴量を抽出します。スタイル特徴量とMLPを用いてボリュームレンダリングを行い、画像ではなくピクセルごとの特徴ベクトルを生成します。ボリュームレンダリングの方法に、3次元の色と密度を予測するNeRF-Wを使います。NeRF-Wで、ボリュームレンダリングするのは、地上にあるブロックだけではありません。空を表現するために、GANcraftでは、環境マッピングで空を表現しています。環境マッピングで表現された空を先程紹介した、ボリュームレンダリングによって2次元特徴マップに変換します。NeRF-Wによりピクセルごとの特徴量マップを出した後に、CNNを用いて、ピクセルごとの特徴マップをGround Truth or 擬似的なGround Truth画像と同じ大きさになるように、画像の変換を行っています。
実験結果
セグメンテーションと実画像のペアを作るために、100万枚の風景画像にそれぞれに対して、DeepLabV210を用いて182クラスのCOCO-STAFFセグメンテーションラベルを付与しています。

実験におけるベースラインは、MUNIT11、SPADE、wc-vid2vid12、NSVF-Wの4つを用意しています。 評価の指標には、人間の好みのスコアを示す指標を設定し、評価を行なっております。
評価者は、
- どちらの映像が見ていて違和感がないか
- リアルな映像はどちらか
の質問を用意し、2つの映像を比較してもらう評価を行なっていました。結果としては、提案されたGANcraftの手法がいずれの手法よりも映像に違和感がなくリアルな映像であると評価されました。
Multimodal unsupervised image-to-image translation. ECCV, 2018.
実際に動作させた結果
自身の実行環境は、Ubuntu18.04、Single NVIDIA RTX3090です。 GANCraftは、Imaginaireをフレームワークとして用いています。そのため、最初にImaginaireのインストールを行います(公式マニュアル)。
インストールの方法は、3つ示されていました。
- シェルスクリプト
- Docker
- Anaconda
それぞれの方法で実行してみたのですが、私の環境ではうまく構築できませんでした。 また、 以下のようにnvcr.io/nvidia/pytorch:21.06-py3 を含むDockerfileを作り環境構築をしようとしたのですがその方法もエラーが解消できませんでした。
From nvcr.io/nvidia/pytorch:21.06-py3 ... ...
そのため、nvcr.io/nvidia/pytorch:21.06-py3 をdocker pullしその中で、以下のスクリプトを実行しました。
以下は、ホストPCのterminalで実行したスクリプトです。
sudo docker pull nvcr.io/nvidia/pytorch:21.06-py3 sudo docker images #nvcr.io/nvidia/pytorch:21.06のIMAGE IDをメモしておきます sudo docker run -it --gpus all ${IMAGE_ID} bash
コンテナの中に入り、以下のスクリプトを実行します。今回は、学習済みモデルを使用して推論しました。
# コンテナの中に入ったら、以下のコードをworkspaceのディレクトリで実行します apt-get update && apt-get upgrade #libgl1-mesa-devをインストールしないと推論できないため注意 apt-get install -y libgl1-mesa-dev git clone https://github.com/nvlabs/imaginaire cd imaginaire bash scripts/install.sh python scripts/download_test_data.py --model_name gancraft # 3種類の事前学習済みモデルが用意されています # demoworld, landscape, survivalislandの中から選択します python -m torch.distributed.launch --nproc_per_node=1 inference.py \ --config configs/projects/gancraft/{world_name}.yaml \ --output_dir projects/gancraft/output/{world_name}
左側がマインクラフトのワールドをセグメンテーションマスクした画像。右側がセグメンテーションマスクを元にGANCraftを用いて、生成した画像となります。論文で草、砂、雪、木、水のブロックが滑らかな現実世界の存在しそうなブロックに変換されて描写されていることが分かります。空の描写に関しても、リアルな空に近く感じました。



所感
GANCraftのポスターを見てポスターの使い方に思わず笑ってしまいました。 GANCraftを用いてマインクラフトで、リアルタイムにこの綺麗な描写で遊ぶことは、まだ実現されていないです。いつか、こんなにリアルな描写でも遊べたら楽しそうですね!
最後に
ここまで前編・後編を通してICCV2021で発表された論文をご紹介しました。コンピュータービジョンのトップカンファレンスに実際に参加し、今回は掲載された論文を実際に手を動かしてみました。論文で提案していたことを実際に目で見て有効性を実感しとても楽しかったです。
NTT Comでは、今回ご紹介した論文調査、画像や映像、更には音声言語も含めた様々なメディアAI技術の研究開発に今後も積極的に取り組んでいきます。
- アカデミックな研究に注力したくさん論文を書きたい
- 最新の技術をいちはやく取り入れ実用化に結び付けたい
- AIアルゴリズムに加え、AI/MLシステム全体の最適な設計を模索したい
という方々に活躍していただけるフィールドがNTT Comには多くあり、一緒に技術開発を進めてくれる仲間を絶賛募集中です。
-
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Advances in Neural Information Processing Systems, pages 5998–6008, 2017.↩
-
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021.↩
-
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.↩
-
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In International Conference on Learning Representations, 2021.↩
-
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herve J ´ egou. Training ´ data-efficient image transformers & distillation through attention. arXiv preprint arXiv:2012.12877, 2020.↩
-
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence ´ Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.↩
-
Golnaz Ghiasi, Yin Cui, Aravind Srinivas, Rui Qian, TsungYi Lin, Ekin D Cubuk, Quoc V Le, and Barret Zoph. Simple copy-paste is a strong data augmentation method for instance segmentation. arXiv preprint arXiv:2012.07177, 2020.↩
-
Siyuan Qiao, Liang-Chieh Chen, and Alan Yuille. Detectors: Detecting objects with recursive feature pyramid and switchable atrous convolution. arXiv preprint arXiv:2006.02334, 2020.↩
-
Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. In CVPR, 2019.↩
-
Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE TPAMI, 2017.↩
-
Xun Huang, Ming-Yu Liu, Serge Belongie, and Jan Kautz.↩
-
Arun Mallya, Ting-Chun Wang, Karan Sapra, and Ming-Yu Liu. World-consistent video-to-video synthesis. In ECCV, 2020.↩