
はじめに
初めまして!イノベーションセンターでノーコードAI開発ツール「Node-AI」のプロダクトオーナーやXAI・因果分析の研究をしております、切通恵介(@kirikei)です。
Node-AIは2021年10月11日にリリースされたNTT Communicationsの内製開発サービスで、その名の通りブラウザ上からノーコードでAIモデルを開発できるサービスで、製造業のお客様を中心に異常検知やプラント運転支援などの様々な領域で活用されています。(ニュースリリースはこちらやこちらやこちら)
いつもはサービスの営業的な紹介をすることが多いのですが、今回はEngineer's Blogでの執筆ということで、エンジニアの方向けの技術、プロダクトマネジメント、チームビルディング、スクラムなどの様々な観点でお伝えできればと考えています。とはいえ、Node-AIに関しては詳細に書きたいことが山ほどあって1つの記事には到底収まらない(!)ので、何回かに分けてシリーズモノとしてお送りする予定です。
そんな中で記念すべき第1回の今回の記事では
- Node-AIがどのようなサービスであるか
- Node-AIで扱う技術領域にはどのようなものが含まれるか
- Node-AIをどのように開発しているか
の3点に関してをプロダクトオーナーである私とテックリードである内藤理大、スクラムマスターの小澤暖から述べます。
Node-AIとは
Node-AIはノーコードAI開発ツールというその名の通り、ブラウザから以下の図のようにカード(モジュール)を直感的につなげるだけで時系列データの前処理からAIモデルの学習・評価までの一連のパイプラインを作成・実行できるツールです。

Node-AIで目指す世界
Node-AIチームには「データ分析にまつわる全て(機能・人)が集まってコミュニケーションしながらデータ分析を継続的に実行し様々な課題を解決し続けている世界」を目指す、というビジョンがあります。
少しこのビジョンを掘り下げてみます。
【課題解決に必要なもの】
昨今、AIという言葉の流行によって様々なデータ分析案件が生まれ、課題解決に利用する流れができてきた一方で「うまく進まない」例もたくさんあります。私自身データサイエンティスト的な役割、すなわちお客様から課題をヒアリングし、データを受け取りそれを分析して最終的な課題解決を行うといういわゆる「データ分析案件」に携わる中で様々な失敗してきています。
この原因としては、「課題解決」というものの範囲が広く、そして複雑であることが挙げられます。例えば以下のような案件があったとしましょう。

データ分析者な我々にとってはまずプラントに存在する時系列のセンサーデータをcsvなどでもらって、その中の不純物(シリカ)の量を表すカラムを目的変数として選択し、その未来の値を教師データとしてcsvのデータから特徴量を作成して何かしらのモデル(ARやLightGBMでもいいしTransformerのような高級なモデルを使ってもいいし...)で予測すれば良い、というのが頭に思い浮かびます。
しかしながら、このモデルを作成するという部分が課題解決自体を示すわけではありません。このゴールは少なくとも「精度の高い予測値をリアルタイムに可視化し、その結果を運用者が見て攪拌のための操作を変えて鉄の収集量が上がること」です。つまりモデルを作成した後に業務に導入するところまで必要となります。
そして「少なくとも」とした通り、このゴールも残念ながら完全ではありません。例えば「精度の高い」はどれくらいの精度なのか、「予測値」とはどれだけ先の未来を当てるのか、「リアルタイム」とはどれくらいの遅延が許されるのか、「運用者が見て」とはどのようなシステムでどんなUIで見るのかなどを課題に関わる様々なステークホルダーとすり合わせなければなりません。
さらに、上記の具体的なゴールを初めに決めたとしてもステークホルダーとの話し合いは終わるのではありません。例えば特徴量の作成には実際にデータを見ている現場の運用者の知見が必要になります。さらに十分な精度を得たとしても実際に導入できるかどうかは最終的なGoサインを出す意思決定者との話し合いが必要になりますし、最終的にモデルを何らかのシステム、例えば工場であれば工場で既に使われているデータ可視化ツールに組み込むためには工場のシステム担当とも意思疎通を図る必要があります。
そして、導入を行ったとしてもそこでプロジェクトが終わることはありません。例えば季節変化による精度の劣化への対応や、ビジネス要件やデータ定義の変化によるモデルの再作成や問題の再定義など、ステークホルダーとコミュニケーションしながら改善を進めていく必要があります。
長々と書きましたが、ここまでまとめると、以下となります。
データ分析による課題解決を継続的に行うには、モデルを作成して終わりではなく、意思決定やシステム導入に至るまでが必要。またデータ分析者で完結することはなく、課題に関係するステークホルダーとのすり合わせ・相互理解が重要。
実際にこれらが実現できているかというと、そこには様々な壁があります。
【壁その1:ステークホルダーの分析内容の相互理解】
上で述べたとおり、課題解決にはステークホルダーとのすり合わせ、特に分析中は精度を上げたり導入判断を行うためのフィードバックが重要になります。この時、データ分析者とステークホルダーは分析内容をしっかり把握することで、より深いフィードバックが可能になります。
例えば、時系列データであれば時系列の前処理において時間窓をどれくらい取るのか、サンプリング間隔をどれくらいにするのかを運用者の知見から決めることがあるでしょうし、特徴選択においては運用者が普段不純物の状態を確かめるのに必要なセンサーを教えてもらうこともあります。このような精度を上げるためのフィードバックには、専門家にもどのような前処理や学習を行っていてどのようなパラメータがあるのかを詳細に理解してもらう必要があります。
また、その理解は意思決定者にも必要になります。意思決定者は導入のための責任を負っているので、その分析によって真に課題が解決でき、自分や現場の知見と照らし合わせても問題ないかどうかを確かめる必要があります。この時に内部のフローを理解していることで、意思決定に必要な情報が得られるため、正当な判断をしやすくなります。導入を担当する社内のシステム担当者にとっても、現状運用を行なっている可視化システムに繋ぐためにデータのフローを理解するのは非常に重要です。
一方で、データ分析者の分析の多くはPythonやRなどのプログラミング言語でなされており、専門外であることも多いステークホルダーにとってはその分析自体がブラックボックスとして捉えられてしまいます。この状態では上記で挙げたような精度を上げるための深いフィードバックや、もっと手前の課題設定が正当性の把握などが遅れてしまい、精度が上がるのに時間がかかったり、導入に至らず課題設定からやり直したりするようなことが起きてしまいます。
【壁その2:コミュニケーションの重さ】
ステークホルダーとのすり合わせを行うために、データ分析者とステークホルダーで例えば2週間に1回打ち合わせをすることがあるでしょう(ステークホルダーは大体忙しいので意思決定者が御登場するのは1ヶ月に1回かもしれない)。この時データ分析者は打ち合わせのために自分の統計量の可視化結果や予測値と実測値のグラフ、はたまた特徴量の設計方法などをJupyterLabのスクショをとってスライドにぺたぺた貼って、さらにステークホルダーにも分かるように平易な言葉で説明を並べ、2週間空いているので課題やKPIも改めて確認して...などの報告書を作成します。これはデータ分析者にとっては重労働で、本来は分析に利用したい稼働の大半を報告書作りに割いてしまうこととなります。
さらに打ち合わせの中では月一参加の意思決定者から課題設定が正当でないことを指摘されてしまったり、現場の運用者から新しい知見が与えられて前処理を追加しなければならない、といったことが起きます。これによりデータ分析者の2週間の稼働は無駄になってしまうことも多々あります。打ち合わせの間隔を1週間にすればこれも防げるように思えますが、先に述べた報告資料の重さを考えると2週間程度のスパンは必要ですし、まさにデッドロック状態になってしまいます。このようにコミュニケーションの重さからフィードバックの間隔が空いてしまうことにより、最終的な課題解決のための右往左往が増えてしまうことになります。そうやっている間に投資判断を行う人から継続をNGにされてしまうこともあるでしょう。
【壁その3:導入の判断と導入自体の難しさ】
上記の壁をなんとか乗り越え、分析がある程度進みモデルが作成できたとしましょう。ここからは導入に向けた壁を乗り越える必要があります。
導入には意思決定者のGoサインが必要になります。これを判断する際問題になるのが「モデルの信頼性」です。例えば1時間後の不純物の割合の予測によると、不純物が減る兆候を示しており、それをもとに運用者が攪拌のスピードを上げるとしましょう。もしこのモデルの予測が誤っていた場合、攪拌のスピードアップによってプラントが傷ついてしまい生産がストップする...と言うこともあり得ます。これを防ぐためには様々な方法がありますが、その1つとしてモデルが何を見て予測をしているかを明らかにし、それが現場で知られている知見と整合性が取れるか確かめるというものがあります。運用者の間では攪拌の際温度を見ながら操作することが提唱されていると言うような知見があれば、モデルが温度を入力として重要視しているかを確かめることで、そのモデルの信頼性を測ることができます。一方、昨今利用される非線形性を含む複雑なモデルではそのような予測の判断根拠を抽出するのは難しく、さらに抽出したとしても説明自体を解釈するにはより専門的な知識が必要であると言う問題があります(この分野はXAIと呼ばれ、私が専門としている分野で色々と語りたいですが、ここでは割愛)。
また、モデルが仮にTensorflowで用いられるSavedModel形式で保存されていたり、前処理がsklearnのpreprocessingで行われているとしましょう。このモデルの導入や運用を行う工場のシステム担当者にとっては、作成されたモデルを扱うにはPythonといった言語や機械学習ライブラリ、Webアプリケーションの知識が必要であり、かなりハードルが高いものとなります。したがって、技術的な観点でも現場にモデルを導入していくことは課題があります。
Node-AIの解決策
ここまで長々と課題を述べてきましたが、ここからはそういった課題を解決するためにNode-AIがどのような特徴を持っているのか、説明していきたいと思います。
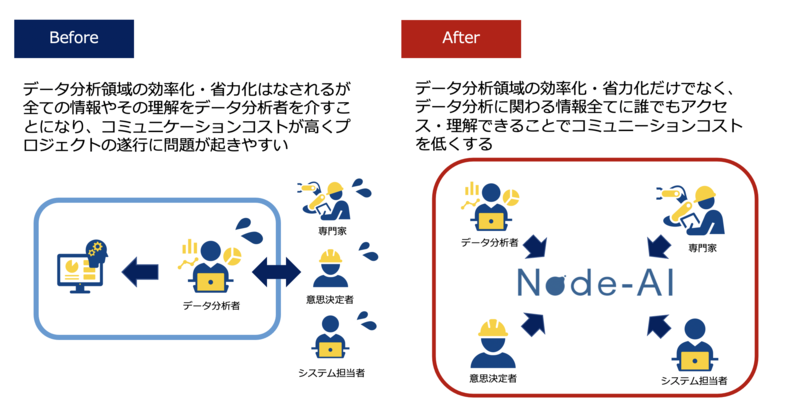
Node-AIが他のツールと比べて最も異なるのは、上に挙げたような「ステークホルダーとのコラボレーション」を重要視している点です。今までのツールのようにデータ分析者のみが分析を効率化するのに使うのではなく、ステークホルダーも含めて利用することでデータ分析での課題解決全体を効率化することを目的とした一風変わった特徴を持っています。すなわち、最終的な課題解決のために必要不可欠な分析の理解のためのコミュニケーションや、導入判断などを打ち合わせだけではなく、ブラウザからアクセスするNode-AIの上で全部やってしまおうと言うアイデアです。したがって、単なる機械学習モデルを作成するツールではなく、データ分析プロジェクトを効率化するツールと言う側面も持っています。以下の項ではそれをどのように実現しているか、いわゆるHowな部分を紐解いていきます。
【ビジュアルプログラミング】

Node-AIは上記の画像の通り、モジュール(我々はカードと呼んでいます)をドラッグ&ドロップでつなげることでデータの前処理、モデルの定義、学習、評価といった一連の分析のフローを実現します。また、各カード内で処理されたデータやその統計量はカードを開くことで逐一確認できるようになっています。これにより、プログラミングの知識のないユーザでも機械学習モデルの作成を行うことができるだけでなく、分析フローが可視化されると言うメリットがあります。
これにより、課題の1つのステークホルダーとの分析内容の相互理解が促進され、データ分析者だけでなくステークホルダーにとってもどのように分析しているかが明確になり、分析工程自体がブラックボックスになることを防ぎます。意思決定者にとってはどのような分析が行われているか知ることで分析の信頼性を得ることが容易になりますし、データの専門家にとっても具体的なパラメータに対するアドバイスがやりやすくなります。加えて、データ分析者にとっても、複数人で分析する場合にその分析フローを引き継いだり比較しやすくなると言うメリットもあります。
【コラボレーション機能】


報告資料作成やフィードバックが早くもらえないというコミュニケーションの重さも課題解決の壁の1つでした。Node-AIでは可視化された分析フローの横でMarkdown形式による資料作成ができます。今まではスライドに可視化した画像を貼り付けたり、前処理の中身を書いたりと、報告書を作成するのに時間がかかっていましたが、可視化すべきデータや分析フローはNode-AI上に全てあるので資料作成のためにデータを取り出す必要もありません。さらにデータの全容もその場で確認できるため、より深い議論が可能になります。
また、フィードバックに関しても、コメント機能を利用することでステークホルダーにメンションを飛ばして質問できます。メンションされたコメントはユーザにメールで通知され、ユーザはそのコメントを見に行くことができます。これにより分析中に出てくる相談をクイックに行うことで、打ち合わせのみと比べて効率的な分析を行えます。
ちなみにNode-AIの分析フローを作成する場所をキャンバスと呼んでいて、文字を書いたり分析フローを作ったりできるまるで自由帳のような働きができるようにしています。
【要因分析・因果分析機能】


導入の難しさの原因の1つは機械学習モデルがブラックボックスであることです。この対応のためにNode-AIでは要因分析、いわゆるモデルの説明性を可視化する機能を備えています。この機能では予測に対してどの特徴のどの遅れ時間のデータが効いていたのかを重要度としてヒートマップで表示できます。さらに、ニューラルネットワークを利用した場合は各時刻における重要度の変化を閲覧することもできます。
さらに、特徴間の時系列を考慮した因果関係を可視化する因果分析機能を兼ね備えており、特徴量の選択やシステムの理解に役立ちます。例えば制御を意味する特徴が入っているデータの場合にはその特徴を変化させるとどういった結果が得られるのかなど、実応用の考察に必要な情報を与えることができます。
【開発したモデルを他システムに組み込みやすくする機能】
モデルの利用に対して機械学習の知識が必要になることから生じるモデル利用の困難さに対しては、Node-AI Berryというモデルを簡単に利用するためのライブラリを用意しています。このライブラリはNode-AIからダウンロードしたモデルを利用して、データを受け取って前処理からモデルの推論までを行いその結果を返すAPIを簡単に作成できます。具体的にはNode-AIからモデルファイルをダウンロードし、所定のフォルダにおいた状態でdocker runするだけです。
さらに、学習データを与えることでそのモデルを再学習するような機能もついているので、課題解決の先にあるモデルの運用という部分もカバーしています。
小括
ここまでデータ分析による課題解決の困難さ・難しさを述べてきました。また、それをNode-AIでどのように解決しようとしているかを紹介しました。
世の中で様々なデータ分析案件が現れ、そして失敗していくのを見てきました(し、自分たちでも失敗してきた)が、一方で私たちはデータ分析の導入は既存のビジネスに絶大な効果を齎すことを信じています。実際に様々なデータ分析案件が真に課題を解決し、色々なところで成果を出し始めています。この流れを加速させるための道具として私たちはNode-AIというサービスを開発しています。(すっごい雑にいうと、もっと全員でデータ分析で色々解決しようぜ!って感じです。)
Node-AIで扱う技術領域
本章の紹介は、Node-AIのテックリードをしております、内藤理大(github.com/ridai)から紹介させていただきます。
Node-AIの開発では、コンテナ技術からアプリケーションの設計・実装まで、幅広い技術を検証した上で利用しています。
本章では、簡単に扱っている技術を紹介したいと思います。(各技術の中で苦労した話や工夫した話は後日、別記事にて紹介させていただきますので、よろしければそちらもご覧ください。)
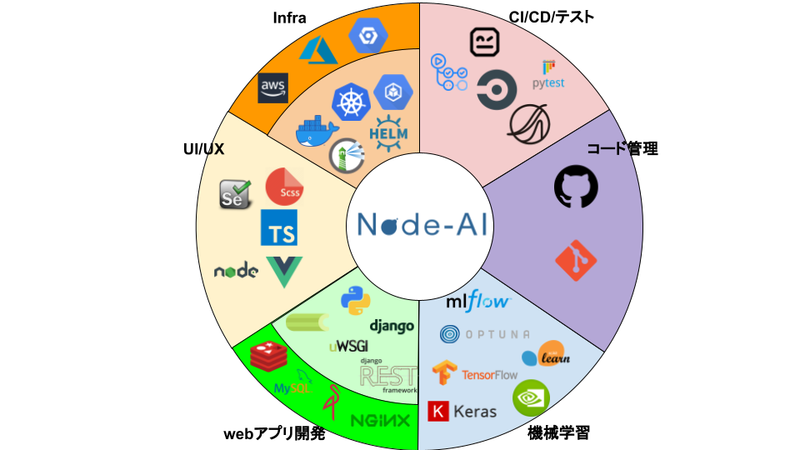
Infra技術
Node-AIは「機械学習を取り扱う」という性質上、GPUを備えたサーバもdeploy先環境として取り扱っています。具体的には、NTT ComAIインフラPJが提供するオンプレミスのGPUクラスタ環境と、GCPのComputeEngine環境を利用しています。(AWSやAzureでの構築も検討中)
また、開発環境と本番環境をコードで管理し、同一の環境を簡単に構築するためにも、アプリケーション自体はDockerコンテナ上に構築しています。
そして、アプリケーションを構成する複数のコンテナの管理を楽にするために、docker-composeを利用するパターンと、より複雑なオーケストレーションを行うためにKubernetesを利用するパターンを用意しています。
CI/CD/テスト
Node-AIでは、開発プロセス中のテストやdeploy作業の自動化にも取り組んでいます。テストについては、開発したPythonモジュールの機能テストのほか、RobotFrameworkを用いたエンドツーエンドテストを用意しています。
まず、テストの流れとしては開発した機能をGithubの作業ブランチにpushするたびに、CircleCIまたはGithubActionsを使った機能の単体テストが自動で行われます。また、本番環境にdeployを行う際には、NTT ComプロダクトのQmonusを利用して機能テストとエンドツーエンドテストが自動で行われます。
次に、deployの流れとしては、同様にQmonusを利用し、ターゲットのVM環境にアプリケーションを自動で配信し、立ち上げを行います。
コード管理
Node-AIでは、Gitを用いてアプリケーションのソースコードのリビジョン管理を行なっています。そして、それらコードのリポジトリとして、GitHubを利用しています。
UI/UX
Node-AIのフロントエンドは、Vue.js + Typescriptを用いたSinglePageApplicationがベースとなっています。ユーザの入力やサーバでの処理結果を動的に処理し、単一のページ上で軽快に機械学習が実行できるUXを提供しています。
また、UIについても、ElementUIを用いたデザインの統一と、SCSSを用いたスタイル指定の効率化に取り組んでいます。
Webアプリ開発
機械学習ではPythonでのライブラリ開発が活発であることから、Node-AI開発でもPythonを採用した開発しています。そして、Webアプリケーションフレームワークとしては、django/dinago REST frameworkを採用しています。
また、機械学習は非常に処理時間がかかるため、celeryというタスクのキューイング処理フレームワーク採用して、非同期的に学習が実行できる仕組みにしています。
他にも、実行に関わる永続データの保持には、MySQLなどのRDBMSの他、ObjectStorageを採用しています。これらデータの保存サービスとして、MySQLやMinIOをDockerコンテナとして立ち上げて利用できるほか、GCPのSaaSサービス等も利用できるような仕組みとなっています。
開発チームでは、これら仕組みを効率的に実装・実現させるため、DDDという開発手法とCleanArchitectureという設計思想を用いています。
機械学習
Node-AIでは、数値の時系列データをターゲットとした、異常検知と予測モデルの作成を可能としています。そこで用いる学習処理としては、sk-learnを用いた線形回帰処理と、tensorflowを用いたNeuralNetworkモデルの回帰/自己符号化器処理となります。
しかし、もっとも特徴的な機能は、「要因分析の可視化」や「因果分析」といったComオリジナルの技術にあります。この機能は、Comの機械学習の研究者による成果であり、Node-AIの開発者と共同で研究技術の導入・提供を行なうことができる体制になっているため、実現できています。
他にも、tensorflowを用いた処理では、optunaを用いたハイパーパラメータの自動探索機能とGPUリソースを判別して利用する仕組みを導入しています。また、mlflowを用いて、ユーザの学習処理の記録も保持しているため、結果の比較・検討も容易にできる仕組みになっています。
Node-AIのアジャイル内製開発
Node-AIチームのスクラムマスター(最近は社内のアジャイル開発案件支援をしながら社内へのアジャイル開発普及活動も)やってます小澤です。ここではNode-AIチームが日々どのように開発業務を行っているかご紹介したいと思います。
Node-AIの扱うAI(機械学習)やデータ分析といった分野は、最新のアルゴリズムは日々更新されお客様の求めるニーズも変化しやすい等、変化が激しく不確実性の高い領域です。これに対応するため、Node-AI開発では初期からアジャイル開発手法の1つである「スクラム」という開発フレームワーク(下図参照、詳細な説明は割愛します)を採用することでアジャイルに内製開発を進めています。
【スクラムフレームワーク】

チームメンバー構成としては、
- プロダクトオーナー(認定資格(CSPO)) 1名
- スクラムマスター(認定資格(A-CSM)) 1名
- 開発者(フロントエンド、バックエンド、QA等) 9名
- デザイナー 2名
となっています。スクラムに関して外部認定資格を持ったメンバーもおり、それぞれ専門的な知識とスキルを持った10名程度の少数精鋭メンバーでチームが構成されています。
【スクラムチーム】

またスクラムは「スプリント」と呼ばれる通常1〜4週間といった比較的短期間の固定の時間枠(タイムボックス)を定め、この中で優先度の高い機能から順次開発したり、様々なスクラムイベント(後述)などを行っていきます(短期間のスプリントを何度も繰り返すことで変化する顧客や市場のニーズに迅速に対応しながら開発します)。Node-AIチームでは1週間スプリントを採用しています。大まかな1週間の流れとしては以下の通りです。
- 水曜PM
- スプリントプランニング(2−4時間程度): スプリントの始まり、スプリントの詳細な計画をチーム全員で立てます(このスプリントのゴールは何か、どんな機能をどのように作るのか、等を決めます)。
- 木曜〜火曜
- 朝会(毎日15分): 毎日決まった時間にチーム全員が集まり、15分間でチームの一日の行動計画を立てます。障害になっていること(課題)の共有も行い、朝会後に別途課題解決の時間を設けることもあります(2次会)。
- プロダクトバックログリファインメント(週1回1時間): 直近のスプリントで実施予定のプロダクトバックログ(機能等)に関して、開発者とプロダクトオーナーが協力して仕様の詳細化や開発規模の見積もりをします。
- デザインミーティング(週1回1時間): スクラムに定義されていないNode-AIチーム独自のイベントです。デザイナー、プロダクトオーナー、開発者が協力し、新規機能の画面デザイン検討やユーザーヒアリング等の結果を受けて既存機能のUI/UX改善に関する議論をしたり、ペルソナの作成・修正等を行います。
- 水曜AM
- スプリントレビュー(1時間): そのスプリントで完成した成果物(Node-AIの場合は動くソフトウェア)を実際の顧客などのステークホルダーにデモのような形で披露しフィードバックを得るイベントです。このフィードバックによってその時点で顧客にとって本当に価値のあるプロダクトになっているかチーム全体で確認ができ、またプロダクトの価値の最適化(プロダクトバックログやリリース計画の見直し等)を図ることができます。
- スプリントレトロスペクティブ(1時間〜1.5時間): スプリントの最後に行われ、スプリントの振り返りを行うイベントです。そのスプリントにおけるスクラムチームの動きなど主にプロセスに注目して振り返りを行い、良かった点や改善したほうが良い点・改善案などを出し合います。Node-AIチームではKPT(Keep・Problem・Try)やFDL(Fun・Done・Learn)、Timelineといったフレームワークを使ったり、みんなで雑談しながらチーム状況を振り返ったりと、いろいろと状況によって使い分けたりしています。
【振り返り例(FDL)】
1週間スプリントだとイベントなどのコストが増えやすいですが、その分細かく軌道修正できる・詳細な計画が立てやすい・改善が進みやすいなどのメリットもあります(個人的には特にアジャイル開発に慣れていないチームほど短いスプリントをおすすめします)。またNode-AIチームでは各イベントのファシリテーター(進行役)を固定せず、ローテーションで回しています。これによりファシリテーターの負荷分散やチームメンバーの誰もがチームをリードする意識、当事者意識を持てるように工夫しています。
現在、日々の開発やイベントはすべてリモートワークで行っています。スクラムでの開発ではチーム連携が非常に重要であるため、NeWorkやSlack、Trello等のコミュニケーションツールやタスク管理ツールをフルで活用しながら、リモート環境下でも、なるべく誰がどこでどのような作業をしているのか可視化したり、ペア作業や雑談等を行いやすい環境を整えています。
またここ最近は実施できていませんが、チームの結束を高めたり、チームビルディングを効果的に行うために「開発合宿」を定期的に実施したりしています。こういった活動もアフターコロナにおいては積極的に実施していきたいと思っています。
【開発合宿】


終わりに
ここまで長文を読んでいただきありがとうございました。今回の記事から技術部分も開発体制もさらに掘り下げて様々な発信をしていこうと考えていますので、今後ともNode-AIをよろしくお願いします!