
はじめに
初めまして!イノベーションセンターテクノロジー部門 データ分析コンサルタントPJの松岡和志です。普段はお客様の経営課題に対して、データ分析を通して解決策を提示する仕事をしています。
この記事では内製開発サービスであるノーコードAI開発ツール Node-AIを用いた需要予測について紹介していきます。
読んでほしい人
- AIについてこれから勉強しようと思っている人
- AIを使ったデータ分析をやりたい人
- AIを活用した需要予測を業務に導入したいと思っている人
- 効率的にデータ分析したい人
- ノーコードツールに興味がある人
伝えたいこと
- Node-AIで簡単に需要予測をするやり方
- Node-AIはAIを作る工程がわかりやすく分かれていること
Node-AIとは
Node-AIは、ブラウザ上からノーコードでAIモデルを作成できるサービスです。NTT Comが独自に開発し、2021年10月11日にリリースしました。現在は製造業のお客様を中心に、異常検知やプラント運転支援などの様々な領域で活用されています。
以前こちらのブログ記事でも紹介しているので、お時間がある方はぜひこちらもお読み下さい! また最近このような賞も受賞させていただきました。
何を予測するのか
今回取り扱うデータは、2011年~2012年のワシントンD.Cで使われた自転車シェアサイクル1 です。こちらからダウンロードできます(要ユーザー登録)。
データのカラムとしては以下のようなものがあります。
- dteday : 日付
- season : 季節 (1:春, 2:夏, 3:秋, 4:冬)
- yr : 年 (0:2011、1:2012)
- mnth : 月(1〜12)
- hr : 時間(0〜23)
- holiday : 休日の判定
- weekday : 曜日
- workingday : 平日は1、土日祝日は0
- weathersit :
- 1 : 晴れ~少しの雲
- 2 : くもり
- 3 : 小雨
- 4 : 大雨
- temp : 気温
- atemp: 体感温度
- hum:湿度
- windspeed:風速
- casual:このシェアサイクルの非会員の自転車利用数
- registered:このシェアサイクルの会員の自転車利用数
- cnt: 自転車利用の総台数 (casualとregisteredの合計)
今回は自転車利用の総台数(cnt)を予測するために、会員の利用数(registered)と非会員の利用数(casual)を分けて予測するモデルを作成していきたいと思います。※流れは同じなのでcasualのみ対象として記載します。
自転車利用の総台数を予測することによって
- 利用希望者が全員満足に利用できる台数の必要最小限数での設置
- 利用数の少ない時間帯に合わせた計画的なメンテナンス実施
等ビジネスに有効な施策を講じることができます。
予測モデル作成の流れ
予測モデル作成は
- データの統計やグラフを見ることで全体の概要を把握
- データの前処理(AIモデルを当てはめるためにデータを加工したり抜けているデータを補完したり、モデルを作るデータとそのモデルを評価するデータに分けたりすること)
- モデル作成、学習
- 評価
- (評価で納得できなければ)前処理に戻ってパラメーター変更
といった流れになります(より詳細な内容やNTT Com独自のノウハウについてはこちら)。
Node-AIでは予測モデル作成に必要な工程がカードで分かれているため、どうやってAIモデルを作るのかを理解したい人にもおすすめです。
予測したいデータを設定する
まずはNode-AIに予測したいデータをアップロードします。上記のデータをダウンロードしてから、こちらからデータをNode-AIにアップロードします。
その後できたデータカードを、キャンバス(Node-AI上にてデータを配置したりデータを処理するカードを設置するエリア)に出してからクリックして開いてみると、データのテーブルや各カラムごとの統計、時系列での推移が可視化されているグラフが見られます。
各カラムの統計
統計について、予測したいcasualの『75%』と『最大値』を見てみます。
『75%』は48.000で『最大値』は367.000となっていて、これはcasualの全データ中75%は48以下であり、最大値は367ということを示しています。
また『平均』が35.676であることから、1時間での非会員の利用数は大体30台〜50台であるが、何かしらの出来事があった際に10倍近くの自転車が使われたということがイメージできます。
この10倍近く使われる台数と時間を予測できれば、利用者と会社双方に理想的な自転車の設置ができそうだと思いますね。

予測したいデータ(casual)の時系列推移
時系列推移の期間選択を見ると、後半にある山が高く、かつ山になる頻度が増えているように見えます。 これはざっくり2012年の方が2011年と比較して利用台数、利用頻度が増えている事を示します。
情報が無いのであくまで想像の域を出ませんが、このサービスの認知度上昇や利用可能場所の増加によってより多くの利用者が増えたのではないかといったことも考えられます。

ここで今回予測する非登録者の利用数(casual)を目的変数、そして予測に関係していそうなパラメーターとして
- holiday : 休日かどうかの判定
- weekday : 曜日
- workingday : 土日祝日でない場合は1、そうでない場合は0。
- weathersit :
- 1 : 晴れ~少しの雲
- 2 : くもり
- 3 : 小雨
- 4 : 大雨
- temp : 気温
- atemp: 体感温度
- hum:湿度
- windspeed:風速
を説明変数に選択して保存を押します。
これでデータの設定は完了しました。
データの前処理~モデル作成~学習~評価
ここからがさらに簡単です。
本来データ分析をする際には、様々な工程をRやPythonといったプログラミング言語を用いて実装していく必要があります。Node-AIはこの工程をカードを繋げるだけで実装できます。(様々な工程について説明した内容はこちら)
そしてさらにNode-AIには『データの前処理~モデル作成~学習~評価』といった一連の流れをできるようカードが設計されているレシピがあります。 レシピとは、処理したい様に繋げたカード群等を保存呼び出しできる機能です。 クイックスタートレシピをダウンロードしてインポートすることで、データの前処理からAIモデルの評価までつながっている状態のフローが出てきます。

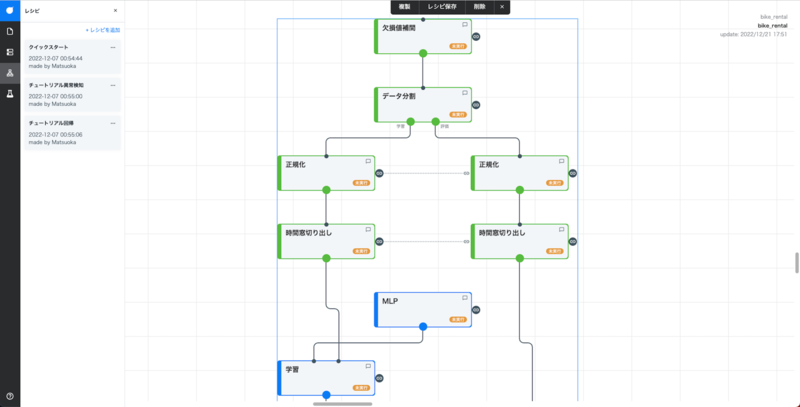
基本的に上のカードから順にクリックして実行を押すだけで、AIモデルができて評価まで見ることができます! このレシピの中で少し設定が必要なデータ分割のカードと時間窓切り出しについてお話しします。
データ分割
これは元々のデータカードから、どこまでをAIモデルを作るためのデータ(学習データ)とそのAIモデルがどの程度あっているかを確認するためのデータ(テストデータ)に分けるものです。 今回はシンプルに、2011年のデータは学習データに、2012年はテストデータにするように設定します。

時間窓切り出し
これはモデル作成の際に時系列データを学習可能な形式に変換するカードです。
今回の様に多変量での時系列データを予測するモデルを作成する際には、予測先の1つの時点を予測をするために、一定の時間幅で切り取ったデータを用いる事が多く、このカードはその設定をするものです。詳しい説明はこちら。
今回は1週間後の需要予測をするために、過去1週間のデータを説明変数とするよう設定します。 このデータは1時間刻みのデータなので、1週間は24(時間)×7(日)=168をN(予測先)とM(窓幅)に設定します。 他のL(丸め幅)とS(ストライド幅)は、推奨されている1に設定します。

評価
MLPカードや学習カード、正規化カードについてもクリックしてすぐに実行を押します。以下のような予測モデルができました。
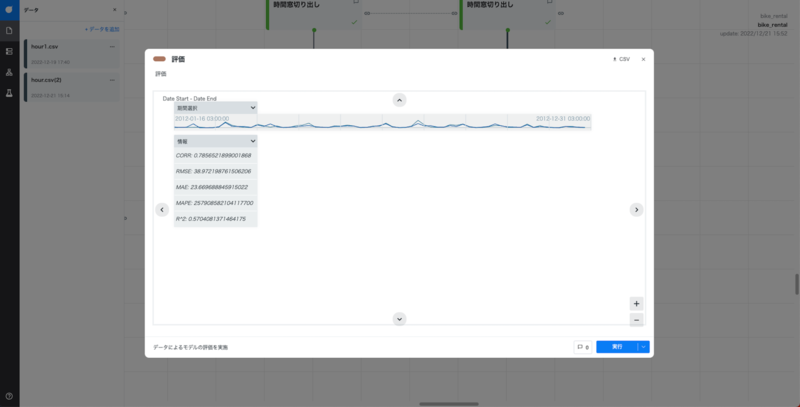
作成したモデルは既知のデータを元に作られたものなので、未知のデータをどの程度予測してくれるのかを評価する必要があります。 しかし、手元にない未知のデータに対して予測精度の評価はしようがありません。 そこで学習データとテストデータに分けて、学習データで作成したAIモデルの予測値とテストデータの値を比較することでAIモデルの予測精度を評価します。 今回は2011年の情報を学習データとして予測モデルを作成し、2012年の情報をテストデータとすることで予測モデルの評価をします。
今回はRMSE、R2の2つを評価指標として考えます。
RMSEとは二乗平均平方根誤差のことで、予測値と実測値の誤差を2乗して平均したものの平方根を取ったものです。 RMSEは0に近いほど予測精度が高いということを示しています。
R2とは決定係数のことで、モデルと実測値を比較してのモデルの当てはまりの良さを示しています。1に近いほどモデルが実測値に当てはまっていることになります。(ただし、これがどのくらいの値が良いかの目安は諸説あります) R2=0.57ということでそこそこ当てはまっているんだなということが分かります。
今回取り扱わなかった評価指標や今回取り扱った2つの詳細についてはこちらをご覧ください。
パラメーターの再設定
このようにレシピを使えばすぐにモデルを作成できますし、より精度を上げたいなと思ったらAIについて調べて勉強すればよりNode-AIを使いこなせるようになります! たとえば多重共線性と呼ばれる、説明変数間で相関係数が高いものを用いて分析するという問題を回避するために、説明変数を減らしてみるなどが考えられます。
実例として先程の分析の説明変数を見てみると
- holidayとworkingday
- tempとatemp
はそれぞれ似たようなものを説明していると思いませんか? ということで多重共線性を回避するために、holidayとatempを説明変数から除外して分析した結果がこちらになります。
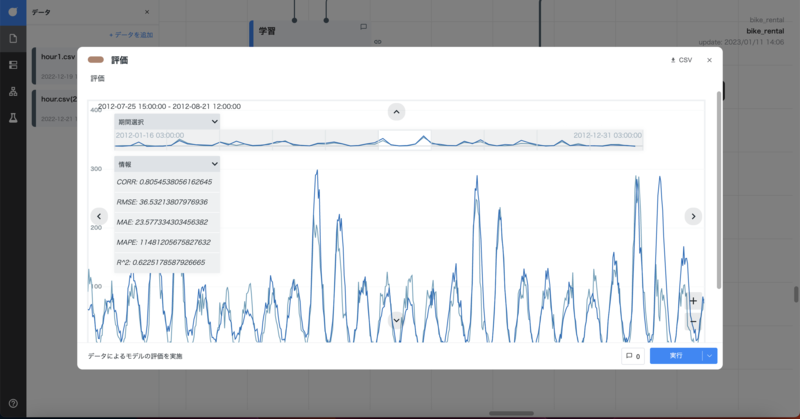
評価指標はこのように変化しました。
- RMSE 39.0→36.5
- R2 0.57→0.62
RMSEは0に、R2は1に近づくことで予測精度とモデルの当てはまりの良さが向上しました。
これ以外にも様々な手法があるので、ぜひとも自分の手で動かしてみてください!
ちなみに、Node-AIを起動してから最初のモデル評価を確認するまで1時間程度でできました。この工程を直感的なカード配置と簡単な数値入力でできるのは個人的には非常に楽だなと思います。
もう1つのやさしい機能としてNTT Com独自技術でもあるAIの可視化機能の重要度可視化や要因分析、因果分析については別の記事で話させていただきたいと思います。
まとめ
- Node-AIを使うことによって簡単に需要予測のAIが作れる
- カード毎に分かれているのでAI作成の工程が理解できる
- レシピを使うことによってデータをつなげるだけでAIモデル作成評価ができる
現在Node-AIはメールアドレスを登録するだけで30日間無料で使えます! こちらの記事を読んでデータ分析に興味を持った方はぜひ登録して使ってみてください。分析対象となるデータから、データをつなげるだけですぐAIモデル開発までできるレシピもあります。まずは触ってみてご自身の職場で使えそうだなと思ったら、ぜひともこちらのフォームからお問い合わせをお願いします。
- Fanaee-T, Hadi, and Gama, Joao, "Event labeling combining ensemble detectors and background knowledge", Progress in Artificial Intelligence (2013): pp. 1-15, Springer Berlin Heidelberg, doi:10.1007/s13748-013-0040-3.↩