
目次
はじめに
この記事は前回の記事の後編です。ECCV2022で紹介されたトラッキングに関する論文をいくつかご紹介します。
ECCV2022のトラッキング論文
1645本の論文の中で"tracking"や"tracker"という単語がタイトルに含まれているものは、以下の表に示した通り30件ありました。 これに限らず、Video Segmentationなどの文脈で物体追跡をおこなっている論文もあるようでした。
2次元物体追跡
| 論文タイトル | リンク |
|---|---|
| ⭐️ Towards Grand Unification of Object Tracking | abst GitHub |
| ⭐️ Tracking Objects as Pixel-wise Distributions | abst GitHub |
| ⭐️ Particle Video Revisited: Tracking Through Occlusions Using Point Trajectories | abst GitHub |
| ⭐️ XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model | abst GitHub |
| AiATrack: Attention in Attention for Transformer Visual Tracking | abst GitHub |
| Joint Feature Learning and Relation Modeling for Tracking: A One-Stream Framework | abst GitHub |
| Backbone is All Your Need: A Simplified Architecture for Visual Object Tracking | abst GitHub |
| Hierarchical Feature Embedding for Visual Tracking | abst GitHub |
| MOTR: End-to-End Multiple-Object Tracking with TRansformer | abst GitHub |
| Tracking Every Thing in the Wild | abst |
| Bayesian Tracking of Video Graphs Using Joint Kalman Smoothing and Registration | abst |
| ByteTrack: Multi-Object Tracking by Associating Every Detection Box | abst GitHub |
| Robust Multi-Object Tracking by Marginal Inference | abst |
| Towards Sequence-Level Training for Visual Tracking | abst GitHub |
| Tracking by Associating Clips | abst |
| Graph Neural Network for Cell Tracking in Microscopy Videos | abst GitHub |
| Robust Visual Tracking by Segmentation | abst GitHub |
| FEAR: Fast, Efficient, Accurate and Robust Visual Tracker | abst GitHub |
| HVC-Net: Unifying Homography, Visibility, and Confidence Learning for Planar Object Tracking | abst |
| Robust Landmark-based Stent Tracking in X-ray Fluoroscopy | abst |
3次元物体追跡
| 論文タイトル | リンク |
|---|---|
| CMT: Context-Matching-Guided Transformer for 3D Tracking in Point Clouds | abst |
| Towards Generic 3D Tracking in RGBD Videos: Benchmark and Baseline | abst GitHub |
| SpOT: Spatiotemporal Modeling for 3D Object Tracking | abst |
| 3D Siamese Transformer Network for Single Object Tracking on Point Clouds | abst GitHub |
| Large-displacement 3D Object Tracking with Hybrid Non-local Optimization | abst GitHub |
| PolarMOT: How far can geometric relations take us in 3D multi-object tracking? | abst project |
その他
| 論文タイトル | リンク | 概要 |
|---|---|---|
| MOTCOM: The Multi-Object Tracking Dataset Complexity Metric | link project | データセットの難易度評価 |
| The Fish Counting Dataset: A Benchmark for Multiple Object Tracking and Counting | link GitHub | 新しいデータセットの提案 |
| Large scale Real-world Multi Person Tracking | link GitHub | 新しいデータセットの提案 |
| BodySLAM: Joint Camera Localisation, Mapping, and Human Motion Tracking | link video | 画像から人物の姿勢、3Dメッシュなどを推定 |
| AvatarPoser: Articulated Full-Body Pose Tracking from Sparse Motion Sensing | link GitHub | 体につけた少数のVRトラッカから全身の姿勢を推定 |
ピックアップした論文
以下では、リストアップした中で私たちが特に興味を持った4つの論文について詳細に見ていきます。
Towards Grand Unification of Object Tracking
概要
シングルカメラのトラッキングには似て非なる以下の4つのタスクがあります。本論文ではこれらのいずれにも適用可能なモデルが提案されています。
- Single Object Tracking (SOT)
- 動画の冒頭にユーザーがバウンディングボックスで指定した単一の物体を追跡するタスク。カテゴリの指定が無く半教師的な推論を必要とする。
- サーベイ論文: Single Object Tracking: A Survey of Methods, Datasets, and Evaluation Metrics
- 関連データセット: TrackingNet 1, LaSOT 2
- Multiple Object Tracking (MOT)
- Video Object Segmentation (VOS)
- 動画の冒頭にユーザーがセグメンテーションマスクで指定した物体を追跡するタスク。
- 関連データセット: DAVIS(Densely Annotated Video Segmentation)-2016 & DAVIS-20175
- Multi Object Tracking and Segmentation (MOTS)
- 特定のカテゴリに属する複数の物体をセグメンテーションマスクで追跡するタスク。
- 関連データセット: MOTS20 Challenge6, BDD100K MOTS Challenge
研究のモチベーション
著者の問題意識として以下の2点が挙げられています。
- 現状最新の手法は特定のタスクに特化しすぎて汎用性に欠けている
- 独立してモデル設計をしているため、パラメーターが冗長化している
上記のタスクを同一のネットワークで解くことにより、これらを解決しようとしています。
関連研究
以下のようにSOTとVOTを同時に解ける手法や、MOTとMOTSを同時に解ける手法などがこれまで提案されてきましたが、4つのタスクを全て同時に解く手法は本論文が初めてだと主張しています。
SOTとVOTを同一ネットワークで解いた研究
- D3S-a discriminative single shot segmentation tracker7, In CVPR2020
- Siam R-CNN: Visual Tracking by Re-Detection8, In CVPR2020
MOTとMOTSを同一のネットワークで解いた研究
提案手法
以下の図に示したネットワークはUnicornと名付けられています。まず初めに、Reference FrameとCurrent Frameの両方を解像度そのままでFPN(Feature Pyramid Network)に入力し、次に説明するUnified EmbeddingやUnified Headに渡します。

Unified Embedding
このコンポーネントでは特徴マップからフレーム間をピクセルレベルで対応付けます。 まず図中のI(Interaction)の部分ではVision Transformer (ViT)を用いることで、タイムスタンプが離れているReference FrameとCurrent Frameに対して正確な対応関係を抽出します。単なるViTでは計算量が増えてしまうので、Deformable Attention Transformerと呼ばれるAttention範囲を自由に変形しながら効率よく重要な領域を参照するモデルを使っています。
Unified Head
上で得られた対応関係はタスクによって異なる活用がなされます。
SOTとVOSでは図中のP(Propagation)の部分で、ユーザーがReference Frameに与えたセグメンテーションマスクから(バウンディングボックスが与えられた場合は四角いマスクとみなし同様に処理します)、計算したピクセルの対応関係に基づいて、Current Frameにおいて物体のありそうな位置の事前分布を計算します。この事前分布は物体検出モジュールであるUnified Headの直前に適用され、画像の注目すべき箇所を示しています。
一方、MOTとMOTSでは物体検出後の図中のA(Association)の部分で、ピクセルレベルの対応関係をもとにインスタンスレベルでのオブジェクト同士の紐付けを行い、追跡中のターゲットとCurrent Frameから検出した物体の対応づけを行います。
このようにひとつの出力を4つのタスクそれぞれに流用できることがこの手法の特長です。
学習方法
全体の学習方法はSOT-MOT合同学習とVOS-MOTS合同学習の2つの段階で行われます。初めにSOT-MOT合同学習では、SOTとMOTのデータセットからエンドツーエンドにUnified Embeddingのピクセルレベルの対応損失とUnified Headの検出損失を用いてネットワークを最適化します。次のVOS-MOTS合同学習では、マスクブランチ11, 12 を追加して他のパラメータを固定してVOSとMOTSのデータセットを用いてマスク損失を最適化することで学習します。
実験結果
学習には16台のNVIDIA Tesla A100で回しています。論文には書かれていませんでしたが、推論もおそらく学習時と同じ環境を使っていると思われます。 各タスクそれぞれについて専門的に学習したモデルと同程度の性能を持ち、A100で入力解像度640x1024に対し20FPSというリアルタイム推論も達成しています。
感想
本来4つのモデルが必要であるところを1つのモデルで完結させることができ、トレーニングコストの面でも推論コストの面でも有用だと言えます。また、異なるタスクを単一のモデルに解かせることで、汎化性能の高いモデルが獲得できているのではないかとも感じました。
Tracking Objects As Pixel-Wise Distributions
概要
この論文では、Multi-object tracking (MOT)においてバウンディングボックスや中心点による従来のトラッキング手法と異なり、オブジェクト位置の分布をピクセル単位に推定してトラッキングする手法P3AFormerを提案しています。ピクセル単位に推定することで小さなオブジェクトにオクルージョンが発生した場合も正しくトラッキングすることが可能になります。
提案手法
次の図は、提案手法のオブジェクト位置の分布をピクセル単位で予測する方法を示しています。まず、ResNetやSwin-Transformer13などのBackboneが用いられ画像特徴を抽出します。そこからPixel DecoderにはDETR14のdecoderが用いられ、アップサンプリングを適用することでピクセル単位の表現を生成します。次に、フロー間の特徴をまとめるためにFlowNet15, 16を用いて前フレームからピクセル単位の特徴伝搬(Pixel-wise Propagation)を行います。最終的にTransformer Decoderを用いてピクセル単位のオブジェクト位置の分布を予測します。

次の図は、ピクセル単位で推定されたオブジェクト位置の分布を用いてフレームごとの関連付けを行う概要です。基本的な枠組みはカルマンフィルター17とハンガリアンアルゴリズムを利用する一般的な方法と同様です。ハンガリアンアルゴリズムのコスト関数は式(6)のように定義されています。式(6)の右辺括弧内が、これまでの時刻で追跡されたオブジェクトと時刻
で検出された候補オブジェクトiに定義されるコストです。
は予測クラスのクロスエントロピー誤差です。
はピクセルのヒートマップを表しており、真のヒートマップ
はオブジェクト中心に位置するように設定されたガウス関数が用いられます。ガウス関数の半径はオブジェクトの大きさに比例するように設定されます。つまり式(6)は、既に追跡されたオブジェクト集合と時刻
で新たに検出された候補オブジェクト集合の総当たりペアのうち、予測されたクラスラベルが正しくかつヒートマップの重なりが大きいものが同一物体として対応付けられるよう設計された関数であると言えます。


実験結果
次の図は(a)MOTR18, (b)TransCenter19, (c)提案手法のP3AFormerのトラッキング結果を示しています。画像右上に小さく表示されている人物に注目してください。(a)は小さな人物の検出に失敗しています。(b)は青枠で示しているようにオクルージョンが発生した場合IDが誤って割り当てられます。これに対して(c)の提案手法はピクセル単位のオブジェクト位置の推定によりオクルージョン下においても小さな人物を頑健にトラッキングしていることが分かります。

次の図はP3AFormerのピクセル単位で推定した中心ヒートマップとトラッキング結果を可視化しています。オブジェクトの中心は全貌が大きく隠れた場合でも正しく推定できており、結果として隠れに頑健な追跡につながっていることが分かります。

感想
トラッキングにピクセル単位の推定を用いることでオクルージョンが頑健になり性能を向上させている点が面白かったです。
Particle Video Revisited: Tracking through Occlusions Using Point Trajectories
概要
任意のピクセルをターゲットとしてトラッキングを行う論文です。この手法をベースに、ユーザーに指定されたセグメンテーションマスクのそれぞれのピクセルを追跡することでVOTタスクを解くことができます。同じくピクセルレベルの密なトラッキングが可能なoptical flowよりもオクルージョンに強く、長いフレームにわたって対象を追跡できるという特長があります。
背景
モーション推定のアプローチは2通りに分けられます。
- feature matchingで特徴点の対応をとる
- 離れたフレーム間でも対応可能
- 推定が疎であり、狙ったピクセルのトラッキングができない
- optical flowで各ピクセルのモーションベクトルを得る
- optical flowの計算を繰り返せば狙ったピクセルをトラッキングできる
- あくまで局所的なピクセルの変化しか追えない
- 追跡対象の手前を何かが通り過ぎた時、手前の物にトラッカーが移るなどして破綻する
- 追跡中のピクセルが少しずつずれていく
そしてこの2つのアプローチの中間をとった2006年のparticle video20では、画面全体にトラッカーを配置しフレームごとにお互いの位置関係を調整させることで、feature matchingよりも密でoptical flowよりも長期間安定したモーション推定が可能になりました。 しかしその手法は依然としてオクルージョンに対応しきれておらず、追跡対象が隠れたことは検知できるもののそのまま見失ってしまうという問題がありました。 本論文ではそれをディープラーニングベースに拡張し、任意のピクセルを独立に追跡できるうえ、一時的なオクルージョンなら再追跡ができるようになっています。
提案手法

フレームの連続画像と、トラッキングしたい点(トラッカーと呼びます)の初期座標を入力として、各フレームにおけるトラッカーの座標と、トラッカーが隠れているかどうかを示すオクルージョンフラグを推定します。原理的には追跡対象が隠れても
フレーム以内にまた現れれば見つけ出せることが期待できます。
全体設計はoptical flow推定器のRAFT21に似ており、更新関数を繰り返し適用して次のフレームの予測値を収束させるという方法をとっています。
まずRAFTと同じネットワークを利用し、各フレーム独立に特徴マップ(feats)を作成します。
次に初期フレームでの座標とその位置の特徴
を用意し、
フレームにわたる予測値を全てそれらに初期化します(
)。これはちょうどトラッカーが
フレームの間全く動いていないと仮定していることになります。
そしてIterative inferenceで囲われている処理によって各時刻におけるトラッカーの座標
, 特徴
, オクルージョンフラグ
が少しずつ最適化されていき、
回のイテレーションの後に得られた予測値
を最終的な予測とします。
Iterative inferenceではイテレーションごとに次のような操作が行われます。初めに、現状のトラッカーの推定特徴と特徴マップfeatsとのdot productをとり、トラッカーと入力画像との類似度マップを生成します。次に、類似度マップからトラッカーの推定位置
の周り
の範囲を切り出します。この時切り出す解像度は
種類用意しており、1つのトラッカーに対して
のshapeを持つテンソルが手に入ります。
そして、ナイーブな手法を考えるならその中で最大値を取る(つまり最も類似度の高い)点が一番もっともらしいトラッカー位置だと言えますが、本手法ではMLP Mixerと呼ばれるニューラルネットを用いてトラッカーの位置
, 特徴
, オクルージョンフラグ
を推定します。以上の操作を繰り返すことで予測を少しずつ最適化していきます。
フレームの推論を終えた後、次の
フレームを入力し追跡を続けることになります。しかし単に最後の予測値
を次の初期値にすると、見た目の一時的な変化(すなわち特徴量の変化)のせいでトラッカーがずれるという問題や、その時対象が隠れていた場合見失ってしまうという問題があります。そこで、オクルージョンフラグを参照し一番よく見えている時刻
の座標と、初期値の
を用いて再追跡を行います。
デモ
以下のデモ動画では馬のかかとを追跡させており、提案手法では足が手前の柱に隠れても見失っていないことがわかります。
https://particle-video-revisited.github.io/videos/horse_all.mp4particle-video-revisited.github.io
感想
物体のカテゴリによらずピクセルレベルで追跡ができるというのは魅力的に感じました。物体検出タスクなどにおけるアノテーション支援にも使えそうです。
XMem: Long-Term Video Object Segmentation with an Atkinson-Shiffrin Memory Model
概要
この論文は、1968年に提唱されたAtkinson–Shiffrin memory model22という感覚記憶、作業記憶、長期記憶の3つからなる記憶モデルに触発された長時間映像用のVOS手法XMemを提案しています。

この手法の特長はGPUメモリの消費が少ない点と長時間の映像にも対応できる点です。次の図は、短時間の映像データセットDAVISと、合計7000フレーム以上の3つのビデオを含む長時間の映像データセットLong-time Video dataset23を用いた実験結果です。左のグラフではモデルが使用するGPUメモリとVOS性能の関係、右では入力映像長を変化させたときの性能の変化が示されています。左から、提案モデルは既存モデルよりもメモリ使用量が少ないにも関わらず高い性能であることが分かります。また右から、既存手法は入力映像長が長くなると性能が劣化する一方で、提案手法の性能は劣化するどころかむしろ向上していることが分かります。STM24, AOT25, STCN26のように特徴メモリが急激に増加する既存手法では、メモリに保存する頻度を落として使用せざるをえず長時間入力に対して安定した性能を発揮できていません。

次の図はSTCNとXMemのスケーリング挙動を詳細に示しています。横軸がフレーム数で、縦軸が精度です。フレームが増加するとSTCNは文脈の欠落により性能が低下するが、XMemは十分な文脈を保持し安定していることが分かります。

提案手法
次の図はXMemの全体像を示しています。この手法はAtkinson–Shiffrin memory modelと同様にSensory memory, Working memory, Long-term memoryの3つのメモリストアから構成されています。Sensory memoryは毎フレーム更新され、非常に局所的な時間の特徴を保存します。Working memoryは枚ごとに情報を蓄積し、事前に設定された最大保持フレームを超えると情報を圧縮した上でLong-term memoryに移行します。Long-term memoryは事前に設定した最大フレーム数(およそ数千フレーム)を超えると特徴を忘れる機能を持ちます。以上のように超短期、短期、長期の3つのメモリストアを活用することで非常に長い映像でも少ないGPUメモリ使用量で高品質な特徴を捉えることができます。
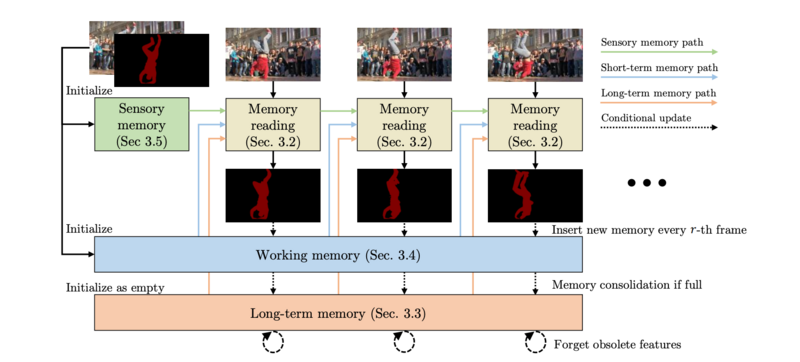
次の図は1フレームにおける処理をより具体的に示したものになります。

Memory reading
全体像で示されているMemory reading操作は上図のQuery, Affinity, Readout featuresの一連の流れに該当し、Working memoryとLong-term memoryから最適な特徴量を取り出し、Decoderを通すことで推定マスクを生成します。
Working memoryとLong-term memoryで使われているメモリは、既存手法のSTCNと同様のものです。ここにはQuery encoderによってエンコードされた入力画像をkeyとし、Value encoderによってエンコードされた出力マスクをvalueとする辞書が保存されており、新しく入力されエンコードされた画像に最も適合するvalueを次の方法で読み出しています。
まずQuery encoderから出力される Query と、Working/Long-term Memoryに保存されているkey
との比較から得られる類似度行列に対してsoftmaxを適用することで、Affinityと呼ばれる行列
を生成します。そしてそれを基にMemory中のvalue
を重みづけたもの
をMemory readingの出力
とします。
このAffinityを計算するとき、STCNで指摘されているように類似度行列の計算にL2距離を利用するとdot product27よりも安定するようです。しかし、次の図の(a)で示しているように全てのメモリ要素を一律に考慮しているためそれぞれの信頼度を符号化できない表現力の乏しさが難点です。そこで提案手法では収縮項
, 選択項
を用いて次の式(2)のように類似度を表現することで図の(c), (d)のように複雑な類似度関係のモデリングを可能としています。


次の節ではWorking memoryとLong-term memoryの更新方法を説明します。
Working memory
Working memoryは高解像度の特徴を一時的に保存しています。上述の通り入力画像のエンコード結果であるQuery と予測されたマスクのエンコード結果であるValueの辞書からなり、
フレームごとにQueryとValueの組(以降エントリと呼びます)が追加されます。
メモリ節約のために、エントリ数がある閾値
を超えると、新しめのいくつかのエントリと、ユーザーにアノテーションされたフレームがエンコードされている最初のエントリのみを残してLong-term memoryに引き渡します。
Long-term memory
Working-memoryから渡されたエントリたちは、次の図ようにプロトタイプと呼ばれるエントリたち
に圧縮されてからLong-term memoryの辞書に保存されます。
まず図中のPrototype selectionにあたる部分で
組のエントリを
のグリッドに分割して、その
個の中からこれまでに最も多くアクセスされた
個のパッチをプロトタイプのkey
として選択します。この時アクセス数は、これまで計算したAffinityの累積和を取ることで計算しています。
次にPotentiationとして、プロトタイプのkeyに対応するvalueを
からうまく重み付けして生成します。具体的にはプロトタイプのkey(図中の星マーク)に類似するグリッドを検索し、特徴量を集約してそのkeyに対応するvalue(金色で囲っている星マーク)を生成します。その結果としてプロトタイプのエントリがLong-term memoryに保存されます。

次の図は、Long-term memoryの処理を可視化したものです。最上段の画像がWorking memoryから渡されたエントリに対応する入力フレームです。黄色の十字がプロトタイプの位置を表しており、それに類似する箇所は赤色で表示されています。また、プロトタイプを示すフレームは赤枠で表示されています。具体的な連結処理では、白鳥のクチバシ(2行目)、植生の一部(3行目)、川岸の一部(4行目)、植生と川岸の境界(5行目)、水面の一部(6行目)という意味のある情報が集約されています。

Sensory memory
Working/Long-term memoryから読み出した値をデコードする際に、Sensory memoryと呼ばれる、Working memoryよりもさらに短期間の情報を保持するメモリから時間局所性の高い特徴量をデコーダに加えています。このSensory memoryの更新は以下のように行われます。
次の図はSensory memory の更新を示しています。Decoderからのマルチスケール特徴をダウンサンプリングしてGRUへの入力として連結します。
フレームごとにWorking memoryの更新とともに行われるDeep Updateでは、Working memoryへの入力と別のGRUを使ってメモリを更新します。これにより既にWorking memoryに保存されたであろう冗長な情報を、最小限のオーバーヘッドでSensor memoryから破棄できます。

以上がXMemの処理内容です。Working memoryで短期的な記憶を、Long-term memoryを長期的な記憶を保持し、それらから取り出した特徴をSensory memoryの情報と合わせることで推論の時間的連続性を担保していることがわかると思います。
デモ
GitHubページ にデモが載っています。10分もある動画に対してもうまく対象の人物をマスクできていることがわかります。
感想
Atkinson-Shiffrin memory modelの3つの記憶モデルを適切なネットワークに落とし込んで設計している点が興味深かったです。
最後に
本ブログでは、私たちが興味を持ったECCV2022の論文についてご紹介しました。NTT Comでは、今回ご紹介した論文調査、画像や映像、更には音声言語も含めた様々なメディアAI技術の研究開発に今後も積極的に取り組んでいきます。
- アカデミックな研究に注力したくさん論文を書きたい
- 最新の技術をいち早く取り入れ実用化に結び付けたい
- AIアルゴリズムに加え、AI/MLシステム全体の最適な設計を模索したい
という方々に活躍していただけるフィールドがNTT Comには多くあります。新卒採用の情報についてはこちらのページをご覧ください。 今後も私たちの取り組みをブログ等で発信していきますので、興味を持ってくださった方は是非今後もご注目ください!
- Muller, M., Bibi, A., Giancola, S., Alsubaihi, S., Ghanem, B.: Trackingnet: A largescale dataset and benchmark for object tracking in the wild. In: ECCV (2018) 1, 9, 10, 20↩
- Fan, H., Lin, L., Yang, F., Chu, P., Deng, G., Yu, S., Bai, H., Xu, Y., Liao, C., Ling, H.: LaSOT: A high-quality benchmark for large-scale single object tracking. In: CVPR (2019) 1, 4, 9, 10, 20↩
- Milan, A., Leal-Taix´e, L., Reid, I., Roth, S., Schindler, K.: MOT16: A benchmark for multi-object tracking. arXiv preprint arXiv:1603.00831 (2016) 1, 4, 10, 11, 20↩
- Yu, F., Chen, H., Wang, X., Xian, W., Chen, Y., Liu, F., Madhavan, V., Darrell, T.: BDD100K: A diverse driving dataset for heterogeneous multitask learning. In: CVPR (2020) 1, 2, 4, 10, 11, 12, 20↩
- Pont-Tuset, J., Perazzi, F., Caelles, S., Arbel´aez, P., Sorkine-Hornung, A., Van Gool, L.: The 2017 davis challenge on video object segmentation. arXiv preprint arXiv:1704.00675 (2017) 1, 4, 11, 20↩
- Voigtlaender, P., Krause, M., Osep, A., Luiten, J., Sekar, B.B.G., Geiger, A., Leibe, B.: MOTS: Multi-object tracking and segmentation. In: CVPR (2019) 2, 4, 12, 13, 20↩
- Lukezic, A., Matas, J., Kristan, M.: D3S-a discriminative single shot segmentation tracker. In: CVPR (2020) 2, 4, 10, 12↩
- Voigtlaender, P., Luiten, J., Torr, P.H., Leibe, B.: Siam R-CNN: Visual tracking by re-detection. In: CVPR (2020) 2, 3, 4, 10, 12↩
- Meinhardt, T., Kirillov, A., Leal-Taixe, L., Feichtenhofer, C.: TrackFormer: Multiobject tracking with transformers. arXiv preprint arXiv:2101.02702 (2021) 2, 3, 4, 11, 13↩
- Wu, J., Cao, J., Song, L., Wang, Y., Yang, M., Yuan, J.: Track to detect and segment: An online multi-object tracker. In: CVPR (2021) 2, 4, 5, 11, 13↩
- Wang, Q., Zhang, L., Bertinetto, L., Hu, W., Torr, P.H.S.: Fast online object tracking and segmentation: A unifying approach. In: CVPR (2019) 2, 4, 5, 12↩
- Lukezic, A., Matas, J., Kristan, M.: D3S-a discriminative single shot segmentation tracker. In: CVPR (2020) 2, 4, 11, 12↩
- Liu, Z., Lin, Y., Cao, Y., Hu, H., Wei, Y., Zhang, Z., Lin, S., Guo, B.: Swin transformer: Hierarchical vision transformer using shifted windows. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 10012–10022 (2021)↩
- Zhu, X., Su, W., Lu, L., Li, B., Wang, X., Dai, J.: Deformable detr: Deformable transformers for end-to-end object detection. arXiv preprint arXiv:2010.04159 (2020)↩
- Dosovitskiy, A., Fischer, P., Ilg, E., Hausser, P., Hazirbas, C., Golkov, V., Van Der Smagt, P., Cremers, D., Brox, T.: Flownet: Learning optical flow with convolutional networks. In: Proceedings of the IEEE international conference on computer vision. pp. 2758–2766 (2015)↩
- Zhu, X., Wang, Y., Dai, J., Yuan, L., Wei, Y.: Flow-guided feature aggregation for video object detection. In: Proceedings of the IEEE international conference on computer vision. pp. 408–417 (2017)↩
- Meinhold, R.J., Singpurwalla, N.D.: Understanding the kalman filter. The American Statistician 37(2), 123–127 (1983)↩
- Zeng, F., Dong, B., Wang, T., Zhang, X., Wei, Y.: Motr: End-to-end multipleobject tracking with transformer. arXiv preprint arXiv:2105.03247 (2021)↩
- Xu, Y., Ban, Y., Delorme, G., Gan, C., Rus, D., Alameda-Pineda, X.: Transcenter: Transformers with dense queries for multiple-object tracking. arXiv preprint arXiv:2103.15145 (2021)↩
- Peter Sand and Seth Teller: Particle Video: Long-Range Motion Estimation using Point Trajectories. In: CVPR (2006)↩
- Zachary Teed and Jia Deng: RAFT: Recurrent All-Pairs Field Transforms for Optical Flow. In: ECCV (2020)↩
- Atkinson, R.C., Shiffrin, R.M.: Human memory: A proposed system and its control processes. In: Psychology of learning and motivation, vol. 2, pp. 89–195. Elsevier (1968)↩
- Liang, Y., Li, X., Jafari, N., Chen, J.: Video object segmentation with adaptive feature bank and uncertain-region refinement. In: NeurIPS (2020)↩
- Oh, S.W., Lee, J.Y., Xu, N., Kim, S.J.: Video object segmentation using space-time memory networks. In: ICCV (2019)↩
- Yang, Z., Wei, Y., Yang, Y.: Associating objects with transformers for video object segmentation. In: NeurIPS (2021)↩
- Cheng, H.K., Tai, Y.W., Tang, C.K.: Rethinking space-time networks with improved memory coverage for efficient video object segmentation. In: NeurIPS (2021)↩
- Oh, S.W., Lee, J.Y., Xu, N., Kim, S.J.: Video object segmentation using space-time memory networks. In: ICCV (2019)↩