
こんにちは、クラウド&ネットワークサービス部の福岡です。 SDPF(Smart Data Platform) クラウドの IaaS である、ベアメタルサーバー・ハイパーバイザーサービス開発のソフトウェアエンジニアとして働いています。
本記事では、リリースプロセスの改善を目指して QA チームが実施している試験の一部を自動化したことで、チームの底力が爆上がりした事例について紹介します。
- SDPF ベアメタルサーバーサービスのミッション
- 機能リリースまでの流れと課題
- QA 削減に向けた取り組み 〜自動テストによる代替〜
- 思いがけない困難
- どうやってこの困難に立ち向かったのか
- 取り組みの成果
- うれしい副次的効果 〜スキルの底上げ〜
- まとめ
SDPF ベアメタルサーバーサービスのミッション
ベアメタルサーバーサービス は、NTT コミュニケーションズが提供している Smart Data Platform におけるクラウド/サーバーメニューの1つです。
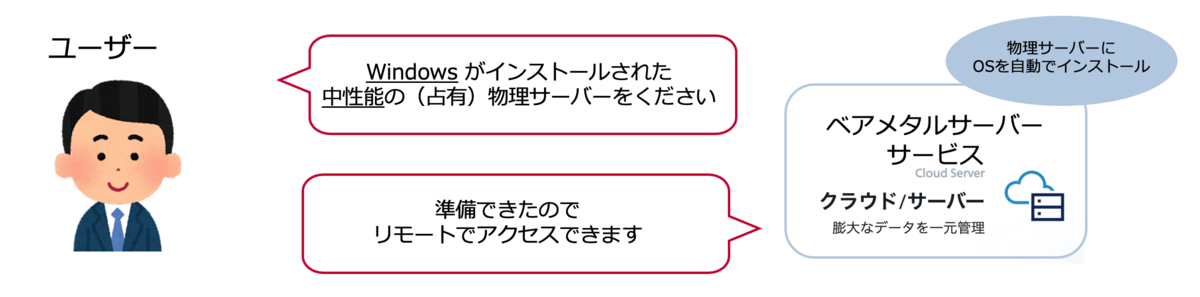
このサービスは OS インストール済みの物理サーバー(ベアメタルサーバー)をオンデマンドに提供するサービスです。 ユーザーは、物理サーバーのスペック、OS の種類などの情報をポータルの画面から指定することで、数十分後に諸々の設定が完了した物理サーバーにリモートでアクセスできるようになります。
このベアメタルサーバーサービスですが、開発の重要なミッションの1つとして 「最新の OS / ハードウェアの継続提供」 があります。 例えば、我々は物理サーバーにインストールできる OS として Red Hat Enterprise Linux (RHEL) を提供していますが、定期的に公開される RHEL の最新バージョンに可能な限り早く追従することを目指しています。
機能リリースまでの流れと課題
ベアメタルサーバーサービスの機能リリースは以下の流れで行なっています。
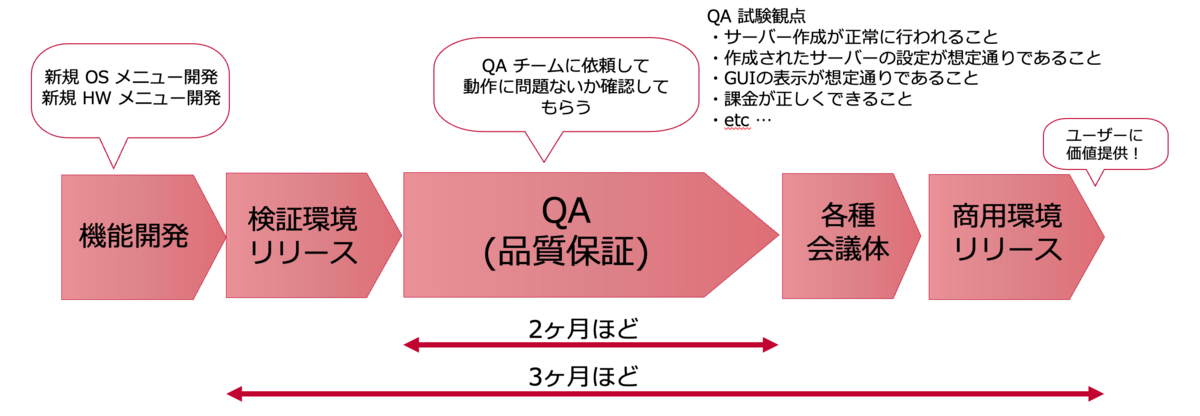
IaaS という、小さな不具合が大きな損害に繋がりかねないサービスを提供している以上、個々のプロセスは不可欠なものなのですが、 機能開発が完了してから商用環境にリリースしてユーザーに価値を提供できるようになるまで、およそ3ヶ月ほどかかってしまっているのが現状です。 その中でも大きな割合を占めるのが QA チームによる QA (品質保証) でした。
ベアメタルサーバーサービスでは、リリースまでにかかる QA の期間の長さが原因で、以下のような 2 つの課題が生じていました。
課題1: 価値提供までのリードタイムが長くなる
当たり前の話なのですが、機能開発が完了してからユーザーに価値を提供できるようになるまでのリードタイムが長くなります。 先ほど述べたように、我々のミッションは最新の OS を「可能な限り早く」提供することなので、この問題は致命的です。
課題2: QA チームの稼働がひっ迫する
QA チームは我々以外のチームの QA を兼任しているため、慢性的に稼働が足りない状況になりがちです。 我々が依頼する QA の期間が長くなってしまうと QA チームの稼働がひっ迫し、本当に QA が必要なところで QA の稼働が取れず、SDPF 全体の開発が停滞することに繋がります。
QA 削減に向けた取り組み 〜自動テストによる代替〜
これらの課題を解決するため、QA チームに実施してもらっている試験項目を精査し、 自動テスト で代替することを考えました。
QA の試験項目には以下のようにさまざまな項目がありました。
- サーバー作成が正常に行われること
- 作成されたサーバーの設定が想定通りであること
- GUI の表示が想定通りであること
- 課金が正しくできること
- etc...
これらの項目のうち、CLI で実装可能である 「サーバー作成が正常に行われること」「作成されたサーバーの設定が想定通りであること」 の2つにスコープを絞れば、QA を自動テストで代替できるのではないかと考えました。
実装イメージは、Serverspec 等を利用した下記のようなものであり、 提供している OS (VMware ESXi, RHEL, Windows 等、細かいバージョン違いを含めておよそ 20 パターンほど) 全てを対象とする想定でした。
# Chronyの起動と有効化をテスト describe service('chronyd') do it { should be_running } it { should be_enabled } end # NTPの停止と無効化をテスト describe service('ntpd') do it { should_not be_running } it { should_not be_enabled } end # clond-initのインストール状況とバージョンをテスト describe command('cloud-init --version') do its(:stdout) { should match(/cloud-init 22\.1-9\.el9/) } end ...
思いがけない困難
しかし、この取り組みですが、計画したはいいものの一向に進む気配がありませんでした。
OS インストール後のサーバーの状態を試験するという特性上、自動化に工夫 1 が必要になること、および、OS の種類が 20 種類と多く実装稼働がかかることも理由の1つでしたが、それ以外にもっと大きな原因がありました。
それは 「網羅性が低く、かつ、メンテナンスされていない自動テストがすでにそこそこ存在していたこと」 です。
既存のコードの保守改修をしている方は共感していただけるかと思うのですが、このような自動テストを網羅性がある完全なものにするのは、大事な作業ではあるものの、創造性があまりなく面白味にかけます。 すでに存在していることが、逆にモチベーションを阻害します。
また、実装が完成したとしても 「コードレビューが滞りがちになってしまう」 という問題もありました。 これは、今回の自動テストの再実装においては、レビュアーは実装されたものが「網羅性のある完全なテスト」であることを逐一確認する必要があるため、レビュアーの負荷が高くなってしまうことが原因でした。
さらに、 「日々締切のある機能開発に追われている状況」 であったことも相まって、この自動テストの再実装はやらなくても直近で問題がないタスクとして後回しになってしまいました。
どうやってこの困難に立ち向かったのか
なんとかしてこの取り組みを推し進めるために、主に2つの工夫を取り入れました。
1. 締切のあるタスクと締切のないタスクをセットにして取り組む
1つめの工夫は、自動テストの再実装をそれ単体のタスクして扱うのではなく、新バージョン OS メニューの開発タスクとをセットで実施するようにしたことです。
例えば RHEL 9.2 メニューの新規開発をするときには、同時に RHEL に関する自動テストを過去バージョンを含めて全て実装し直すことにしました。
新バージョンの OS メニュー開発という締切があるタスクと、自動テストの再実装という締切のないタスクをセットにして実施することによって、インクリメンタルに無理なくこれまでの開発サイクルに組み込むような形で、自動テストの再実装を推し進めることができました。
2. チームでサービス説明書の読み合わせ会を実施
サービス説明書(サビ説)とは、我々が提供するサービスで満たすべき要件が記載されている文書です。
自動テストの実装およびレビューは、この文書をベースにして網羅的かつ正確に行う必要があります。 ただ、文言が全体的に固かったり、OS に関する事前知識が必要だったりと、少しとっつきにくいところがあります。
自動テストのレビューが滞る要因の1つに、レビュアーのサビ説を把握する手間があるのではないかと考え、 事前に自動テストの実装に必要なサービス説明書の読み合わせ会をチーム全体で開催することにしました。
この読み合わせ会の開催によって自動テストで実装すべき内容を強制的にインプットする機会を作ることで、実装後のレビューのコストを下げることができました。
取り組みの成果
自動テストの再実装により QA の短縮およびリリースプロセスの改善が達成できたことで、具体的に以下のような恩恵が得られることになりました。
1. QA の稼働削減
単純計算で、単一の OS あたり 20 時間/人ほどの稼働の削減になりました。 我々はおよそ 20 パターンの OS を提供しているため、 リリースごとに 400 時間/人ほど の稼働の削減ができたことになりました。
2. ソフトウェアの品質向上
先ほどおよそ 20 パターンほどの OS を提供していると述べましたが、QA チームの稼働には限りがあるため、実際のところは重要度の高い OS のみを対象にした QA しかできていませんでした。
それ以外の OS については QA を省略してリリースするということが半ば慣習化 しており、過去にそれが原因でトラブルを発生させてしまったこともありました。
しかし今回の取り組みによって、 全ての OS パターンについての網羅的な試験 を自動テストとして実行できるようになったため、ソフトウェアの品質向上に繋がりました。
3. セキュリティ向上
自動テストの実装により、QA チームの作業期間の短縮ができたので、 短いリードタイムでユーザーに最新の OS メニューの提供ができるようになりました。 これにより、脆弱性対応等の OS のマイナーバージョンのアップデート等の軽微な修正であっても、OS をその都度リリースする選択肢が生まれたため、結果的にセキュリティの向上に繋がりました。
うれしい副次的効果 〜スキルの底上げ〜
元々意図したものではなかったのですが、この取り組みを通して、経験の浅いメンバーを含めた開発メンバー全員のスキルの底上げが実現できました。

1. サービス仕様の理解が向上
ベアメタルサーバーサービスは巨大なサービス2 であるため、経験が浅いメンバーは 「改修で触ったことがある部分はわかるけれど、それ以外の部分はさっぱり」「実装を断片的に読んだことはあるけど仕様はよく覚えていない」 となりがちでした。
今回の取り組みを通して、開発メンバー全員が一通りサビ説の内容が頭に入っている状態にまで持っていくことができました。 特に経験が長いメンバーに偏りがちな 「サービス仕様に関わる問い合わせ対応」 を全員で分担してできるようになったのは大きな成長でした。
2. QA 試験項目の理解が向上
今回の取り組み前は、試験項目のリストアップを QA チームにやってもらっているのをいいことに、 多くの開発メンバーは試験項目に対して興味が薄い状況でした。
恥ずかしながら 「細かいことはあまり把握していないものの、最終的に不具合があったら QA チームによって指摘されるから問題ない」 という意識で開発を進めていることが多々ありました。
しかし今回の取り組みを通して、QA の試験項目のうち「どこが自動化可能なのか」を真剣にチームで議論したことによって、具体的に何を QA で見てもらっているのかについての理解が向上しました。
その結果、「ここは開発のユニットテストでカバーしていて、ここの GUI との結合部分(or 課金部分)はQA チームに見てもらうことになる」というように、個々の機能について最終的にどこで動作確認をするのか、ということを常に意識した 堅実な開発 ができるようになりました。
まとめ
以下が本記事のまとめとなります。
- ベアメタルサーバーサービスではリリースプロセスにおいて時間のかかる QA が課題であった
- OS インストール後のサーバーの状態を確認する自動テストの再実装をして、QA のプロセスを一部短縮
- 優先度が低くなりがちな自動テストの再実装を推し進めるために、以下の工夫を導入
- 締切有りのタスクと締切無しのタスクをセットで行う
- レビュー負荷の軽減を目的としたサービス説明書の読み合わせ会を実施
- 結果的にリリースプロセスの改善だけではなく、開発メンバー全員のスキルの底上げを実現
最後になりますが、SDPF クラウドは国内最大級のクラウドサービスです。 開発メンバーは、数千台以上の物理サーバーの操作の自動化をはじめとした、技術的難易度の高い課題に取り組みつつ、日々より良いサービスにしようと邁進しております。
直近ではベアメタルサーバー・ハイパーバイザーチームは「B26.大規模国産クラウドを支える IaaS (ベアメタルサーバー/ハイパーバイザー) のソフトウェア開発」というポストで現場受け入れ型インターンシップの募集をしています。 本記事に興味を持った学生の方は是非奮ってご応募ください。